이 게시글은 서울대학교 데이터사이언스대학원 조요한 교수님의
거대언어모델과 대화형 인공지능 강의를
학습을 위해 재구성하였습니다
이 수업을 중간에 청강 신청하는 바람에
1강(OT) 내용은 못들었다..
그래서 2강인 본격적인 수업부터 차근차근 정리해보려고 한다

오늘 배울 내용은 자연어처리의 기본이 되는
word2vec과 seq2seq이다

word2vec의 기본 아이디어는 word를 벡터로 나타내는 것이다
한 마디로 단어를 dense vector로 나타내는 것
이 word2vec 이전에 one hot vector라는게 있었는데
이건 sparse vector로 단어를 나타내는 것이다
우리가 단어를 표현할 때 사전에 5만개의 단어가 있다고 해보자
그럼 그 전체 5만개 중에서 그 단어가 있는 인덱스를 찾아서
그것만 1로 표현하고 나머지는 다 0으로 표현하는게
one hot vector이다
벡터의 형태를 하고있지만 사실상 인덱스의 형태에 가깝다
그래서 이러한 one hot vector는 sparse vector이다
dense vector는 sparse vector보다 훨씬 적은 dimension으로 단어를 표현하는 것이다
sparse vector는 대부분의 dimension이 0인 벡터인데
dense vector는 단어들을 0이 아닌 의미있는 벡터들로 표현하고 싶은 것이다
대부분의 언어모델들은 input으로 dense word vector를 받는다
그런데 이 방식이 항상 그래왔던 것은 아니다
상대적으로 역사가 짧다
2013년정도부터 사람들이 dense vector를 입력으로 받는 것을 시도해왔다
그 전에는 단어라는 것들이 보통 one hot vector로 많이 표현되었고
그 대표적인게 bag of words이다
document가 있으면 그 document에 단어들이 여러 개 등장하는데
그 각각의 단어들에 index가 있으니까
그 각각의 index에 해당된 단어가 document에 총 몇 번이 등장하는지
count해서 표현하는 것이 bag of words인데
일종의 one hot vector를 이용한 것이다
아무튼 오늘 우리가 배울 word2vec은 단어를 dense vector로 만들고싶은 것이고
word2vec에는 크게 2가지 알고리즘이 존재한다
바로 skip-gram과 CBOW이다
위 2가지 알고리즘은 단순히 옛날 알고리즘이 아니고
오늘날의 BERT와 같은 언어모델에도 적용되는 원칙과 같은 알고리즘이라
제대로 알아두면 좋다

그렇다면 왜 단어를 dense vector로 만들면 좋을까
기본적으로 언어는 symbolic하다
하지만 이게 컴퓨터에는 굉장히 좋지 않다
위 ppt 예시에서 the, cat, sat 등등은 다 symbolic해서
컴퓨터가 이해하기에는 어렵다

위 ppt에 있는 2개의 문장은 의미는 유사하지만 단어는 굉장히 다르다
the cat sat on the mat과
the kitty took its place upon the rug
는 사용되는 단어는 매우 다르지만 의미는 유사하다
그런데 단어가 매우 다르기 때문에 컴퓨터 입장에서는
위 두 문장이 유사하다고 판단하기가 힘들다
그렇기 때문에 이러한 symbolic 표현은 컴퓨터 입장에서
그렇게 좋은 representation이 아니다
그에 반해서 vector는 컴퓨터 입장에서 매우 좋은 representation이다

역사적으로 많은 머신러닝 기법들이 vector를 입력값으로 받아왔다
그래서 단어도 vector로 받는 것은 좋다
그리고 단어를 vector로 받게되면 단어의 유사도나 관련성을
벡터로 굉장히 intuitive하게 표현할 수 있게 된다
이 단어 벡터들이 구성하는 좌표 공간이 있을텐데
하나의 단어를 백개의 dimension 벡터로 표현할거라면
100 dimension의 좌표공간을 생각할 수 있을 것이다
그 안에서 유사하거나 비슷한 단어는 비슷한 위치를 차지하게 만들고
관련이 없는 단어는 멀리 떨어지게 만들면
이 단어들간의 관련성을 굉장히 직관적으로 표현할 수 있다

one hot vector는 단어의 개수를 dimension으로 만들어야해서
공간을 매우 많이 차지한다
우리가 만약에 저 단어들을 좋은 word vector로 표현할 수 있다면
단어들을 이용해서 수학적인 연산이 가능하게 된다
위 ppt에서 the cat sat on the mat 이라는 각각의 단어들의 벡터를 다 더하면
저 문장의 의미가 되도록 만들 수 있는 것이다
한 마디로 언어를 가지고 어떤 수학적 연산을 할 수 있게 되는 것인데
이게 굉장히 중요한 점이다

만약에 우리가 각각의 단어들에 대해서 아주 좋은 dense vector를 구할 수가 있으면
이 벡터들을 이용해서 NLP task에서 잘 활용할 수가 있다
그래서 word vector들은 이렇게 굉장히 다양한 장점들을 갖고 있다

word vector는 word embedding이라고도 불린다
그렇다면 각각의 단어를 임베딩으로 만들었을 때
그 중에서도 뭘 제일 지켜야할까?
어떤 특징들을 꼭 가졌으면 좋은걸까?
이런걸 함께 고려해보자
그런 특징들 중에서 가장 중요한
word embedding이라고 하면 이것만큼은 가졌으면 좋겠다고 한 특징이
단어가 비슷하면 비슷할수록
관련이 있으면 있을 수록
벡터의 좌표 공간에서 둘의 위치가 가까웠으면 좋겠는 것이다
이것만큼은 꼭 워드 임베딩이 만족시켰으면 좋겠는 것이다
그렇다면 이런 특징이 왜 중요할까?
만약 우리가 번역테스트라고 생각을 해보자
이 번역기가 학습을 할 때 학습 데이터에서 movie라는 단어를 봐서
이걸 영화로 번역을 잘 하는데
만약에 처음 보는 film이라는 단어는 영화로 번역을 잘 못할 수가 있다
그런데 이 movie와 film이 비슷한 벡터를 갖고있다면
두 개가 유사하다는 것을 모델이 알 수가 있다

위 예시 이외에도 각각의 단어가 갖고있는 문법적이나
의미적인 정보를 잘 추론할 수가 있다
하나의 단어를 vector로 transformation 해야하는데
이 과정도 빨라야하는데 이것도 잘 할 수가 있다
그리고 위와 같은 특징을 잘 살리면
굉장히 다양한 언어에 대해서 최대한 많은 단어들을 커버할 수가 있다

그래서 비슷한 단어들이 좌표상에서 비슷한 위치에 놓여있게 하고싶은 것이다
이게 중요하다고 했는데
그렇다면 유사도라는 것은 뭘까?
관련이 있다는 것은 뭘까?
이런 철학적인 질문을 던질 수 밖에 없다
두 단어가 유사하다는 것은 뭘까?

여기서 나온 아주 역사가 깊은 이론이 바로
distributional hypothesis다
여기서 말하는 단어의 의미라는 것은 context간의
distribution에 의해 결정이 된다는 것이다
즉 어떤 단어들이 같이 나타나는지를 보겠다는 것이다
단어의 의미를, 주위에 어떤 단어들이 주로 나타나는지로 정의하겠다는 것이다
그렇다면 이게 왜 말이되는지를 한 번 살펴보자
의미가 비슷한 단어들은 우리가 통계적으로 봤을 때
비슷한 맥락, 비슷한 문맥에서 나타난다
runs와 walk는 우리가 생각했을 때 완전히 동일하지는 않지만
유사한 의미를 갖고 있는 단어이다
위 두 단어는 어떤 문장에서 쓰일 수 있는지를 생각해보자
위 ppt에서도 보면 runs와 walks는 자연스럽게 같이 쓰일 수 있다
그래서 저 단어들은 사람이 느끼기에도 굉장히 유사하다고 느껴지는 단어들인것이다
이것이 문법적으로도 마찬가지이다
세상에는 수많은 동사들이 있는데
통계적으로 봤을 때 굉장히 비슷하게 단어들이 겹치는 것이 많다
이 세상에 무수히 많은 명사들이 있는데
이 명사들은 대부분 공통적으로 근처에 관사들이 나타난다
이런 식으로 문법적으로 비슷한 단어들도 비슷한 문맥을 갖고있다
이것이 바로 distribution hypothesis가 말하고있는 것이다

비슷한 개념으로
친구를 보면 그 사람을 알 수있다는 것과 동일하다
위 ppt에서 물음표로 쳐진 어떤 사람이 있다
오른쪽에 있는 9명 중에서 이 사람의 친구가 누구인지 맞춰보자
그리고 우리에게 저 물음표 쳐진 사람에 대해서
몇 가지 질문을 하면 대답을 하겠다라고 한다면
우리는 어떠한 질문을 할 수 있을까?
나이, 성별, 국가 등등에 대해서 질문할 수 있을 것이다
단순히 친구에 대한 질문이 아니고
인간의 어떤 identity를 결정하는 굉장히 중요한 정보들이 될 수도 있다
결국 친구를 맞추기 위해서 할 수 있는 질문들이
사람의 핵심적인 identity를 결정하는 질문들이 되는 것이다

위 ppt에서 aboofa라는 잘 모르는 단어가 있다고 해보자
그렇다면 오른쪽의 9개 중에서 어떤 단어가 가장 많이 나타날 것 같은지 맞추고싶다면
가운데 있는 것들에 대해서 질문할 수 있다
성별이 어떤지, 품사가 뭔지, 복수인지 단수인지 등을 물을 수 있다
그리고 마지막 inferior, coward, gracious 등을 구분하려면
긍정인지 부정인지도 질문할 수 있을 것이다
이 단어 주위에 어떤 단어가 나타나는지를 맞춰보자고 했는데
이건 주위의 문맥을 넘어서 어떤 단어의 identity를 결정하는
매우 중요한 요소들이 되는 것이다

그래서 이걸 이용해서 단어의 좋은 임베딩을 구할 수 있지않을까? 한 것이다
좋은 임베딩이란건 이 단어의 뜻을 다 포괄하고 있어야하기 때문이다
그래서 위 ppt처럼 neural network를 만들어서
word2vec task를 해보자고 한 것이다
input으로 어떤 단어를 넣어서 neural network로 디자인을 해서
결과로 주변에 어떤 단어들이 나오는지 맞추는 task를 해보자고 한 것이다
이 단어 주위에 이 단어가 나타날까? 안나타날까?
이걸 0과 1로 나타내는 task를 수행하는 것이다
이렇게 디자인해서 학습을 시키면 중간에 bottleneck이 되는 것들은
이 단어의 핵심이 되는 것들만 학습이 될 수밖에 없을 것이라고 생각한 것이다
결국 이 prediction은 중간 bottleneck에 해당되는 벡터들로부터
예측이 되는 구조가 되는 것이다
이런 정보들을 다 잘 담고있어야만 이 task를 매우 훌륭하게 수행할 수가 있다
그래서 나중에 우리가 이 모델을 충분히 학습시킨 다음에
이 단어를 넣었을 때 중간에 계산되는 이 벡터들을 똑 떼다가
이 단어의 word embedding으로 사용을 하자는 것
이게 바로 핵심 아이디어가 되는 것이다
이게 바로 representation learning이라는 기본 원칙이 된다
representation learning은 우리나라말로 표현학습이라고 하는데
벡터를 representation 하는 것이다
어떤 데이터들
단어, 이미지, 오디오와 같은 데이터들을
잘 표현하는 벡터를 만들어서 이걸로 어떤 작업을 하는 것을 말한다
좋은 벡터를 만들어내는 작업을 representation learning이라고 한다
이 representation learning에서 가장 중요한 핵심적인 원칙 중에 하나는
이 벡터에다가 집어넣고자 하는 정보를 잘 알아야 풀 수 있는
성공적인 task를 디자인 하는 것이다
단어같은 경우에는 이게 문맥 맞추기가 되는 것이고
품사, sentiment와 같은 정보를 알아야 주위에 어떤 단어가 나타날지 잘 알 수 있게된다
이런식으로 디자인을 해서 학습을 시키면
좋은 representation learning을 할 수 있겠다~ 하는 것이 원칙이다
가운데 있는 값들이 비슷하면 예측값도 비슷할 수 밖에 없다
또한 이 네트워크의 구조상 끝 부분이 비슷한 단어들은
중간부분도 비슷할 가능성이 매우 크다
따라서 이런식으로 학습을 시키면
의미가 비슷한 단어들은 비슷한 벡터값을 갖도록 하고싶다는
이 조건이 만족이 되는 것이다
그리고 이렇게 하면 서로 의미가 다른 단어들은
이 중간값도 다를 가능성이 매우 크게 된다
그래서 이게 바로 word2vec의 기본적인 아이디어이다

이렇게 워드 임베딩을 구하면
두 단어가 관련이 있으면 있을 수록
좌표상에서 가깝게 위치하게 된다

그래서 기본적으로 이런 아이디어를 갖고 word2vec이 나타나는지
skip-gram과 CBOW 2가지 알고리즘을 살펴보자

우선 skip-gram부터 알아보자
위 ppt 예시에서
the cat sat on the mat
이라는 문장을 가져왔다고 해보자
이 네트워크는 단어 하나에 대해서 왼쪽과 오른쪽을 맞추도록 디자인 되어있다
slide window가 3인 것이다
cat이 들어갔을 때 the와 sat을 맞추는 학습을 한 번에 진행하게 된다
vocabulary 사이즈의 dimension 만큼을 왼쪽에 갖고있고
중간에 들어갈 단어만 1이고 나머지는 0인 그런 embedding이 input으로 들어가게된다
cat만 1이고 나머지는 0으로 들어간 다음에
중간에 matrix가 곱해져서 matrix operation이 수행되고
이 과정을 거치면 the와 sat을 맞추는
그런 neural network를 학습시키는 것이다
이런 연산과정을 한 번 시각화해보자

이렇게 곱하면 행렬곱에 의해서 input 벡터의 첫번째만 1이기 때문에
M의 첫번째 줄만 결과로 남아있게 된다
만약 세번째 input word vector가 1이라고 한다면
M의 세번째 줄만 남아있게 되는 것이다

그럼 이제 이 slide window를 한개 미뤄보자
이제는 sat이라는 단어를 넣었을 때
cat이 on을 맞추도록 학습을 시킨다
이렇게되면 M matrix의 네번째 row만 학습이 되는 것이다

위의 과정을 계속해서 반복하면 이렇게 된다
첫 번째 row에는 cat에 좋은 row가 남게되고
두번쨰 row에는 mat에 좋은 row가 남게 되고
이러식으로 각각의 단어에 좋은 row가 남게 된다
그래서 각각의 row를 똑똑똑 떼서 각각의 단어에 대해서 사용을 할 수 있게 되는 것이다
또 이러한 학습 방식의 장점은
학습 데이터를 구하기가 굉장히 쉽다는 것이다
웹에서 그냥 모든 글을 다 긁어오면 되기 때문이다
하지만 이러한 방식에도 문제가 있는데
철자가 같으면 벡터로 되는 문제가 있다

그렇다면 조금 더 생각을 해보자
Kitty라는 단어가 있다고 생각을 해보자
궁극적으로 cat과 kitty는 비슷하나 벡터를 갖게 될 가능성이 크다
그런데 만약에 vocabulary에 sitting이라는 단어가 있다고 해보자
그럼 sat과 sitting이 있는데 의미는 비슷하지만 품사가 다른 단어이다
품사가 달라서 주위에 나타나는 단어가 비슷할수도 있지만
또 품사의 차이로 인해서 다른 단어들이 있을 수도 있는 것이다
그래서 우리가 이 방식을 사용해서 학습을 하면
궁극적으로 이 sat과 sitting의 워드 임베딩이 어떻게 학습이 될지 유추를 해보면
대부분의 dimension은 비슷한 값을 가질텐데
동시에 context 단어에서 분명히 품사 때문에 오는 차이가 있기 때문에
이걸 예측해내려면 몇몇 디멘션들은 차이가 있어야 할 것이다
이렇게 우리가 유추해볼수가 있다

이제 그다음으로 CBOW 알고리즘을 살펴보자
skip-gram과 아이디어는 비슷한데
input과 output이 반대가 된다
the와 sat을 input으로 주고 중간에 들어갈 cat을 맞추는 방식으로 디자인을 하는 것이다
이렇게 학습을 수행해도 비슷한 직관으로 학습이 잘 된다
input이 이 2개의 벡터를 계산해서
element wise로 sum을 해준다
이걸 가지고 중간 단어를 예측하도록 해주는 것이다
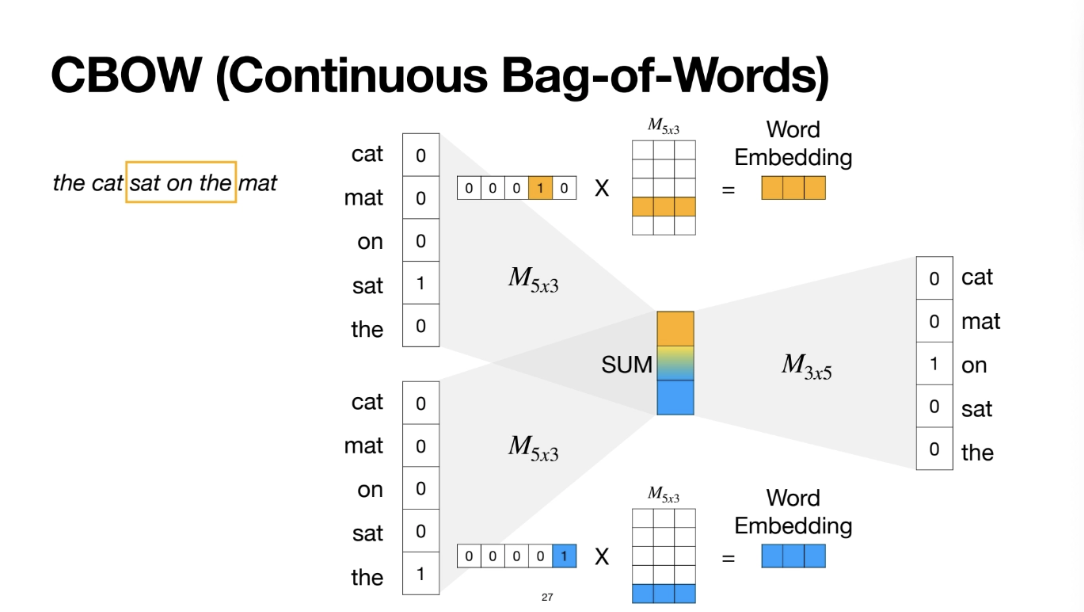
그런데 한 가지 우리가 생각을 해보자
두 벡터를 element wise sum으로 합친다고 했는데
이렇게 합칠때 벡터들의 뭉개질 수 있지 않을까?
왼쪽 단어로 만들어진 노란색 벡터가 있고
밑의 단어로 만들어진 파란색 벡터가 있을텐데
두 개를 더하니까 이걸 더하는 순간
두 벡터들의 identity를 잃어버려서 이상한 중간벡터가 될 수 있지 않을까?
이러한 생각을 해볼 수 있을 것이다
결론부터 말하면 그럴 가능성은 크지 않다고 한다
중간에 있는 단어를 맞추려면 왼쪽에 있는 단어와 오른쪽에 있는 단어 모두 중요하기 때문에
모델은 이 왼쪽과 오른쪽 단어를 각각 보존하는 방식으로 학습을 시키게 된다
그래서 이렇게 디자인을 하더라도 두 개의 벡터가
서로 간섭하지 않도록 워드 임베딩이 학습될 가능성이 높다

이렇게 했더니 서로 비슷한 단어들은 비슷한 좌표에 있도록 학습이 되었다
이렇게 학습이 된 워드 벡터들의 각각의 dimension을 분석해봤더니
이 각각의 dimension이 사람이 이해할 수 있는
semantic feature를 갖고있는 경우가 많더라는 것이다
1번 dimnesion은 gender라던지
2번 dimension은 품사라던지 등등
결국 이 임베딩들은 단어간의 relational meaning을 capture하게 되는 것이다
예를 들어서 king이라는 단어에 man의 벡터를 빼고
woman의 벡터를 넣었더니 가장 가까운 벡터가 queen이 되더라는 것이다
king이라는 벡터가 여러가지 feature들을 벡터에 담고있을텐데
여기서 남성형을 갖고있는 벡터를 쏙 빼고 여성의 성분을 담은 벡터를 넣었더니
queen의 vector와 매우 유사해지더라는 것이다
즉, 단어 벡터를 가지고 우리가 수학 연산을 할 수 있더라는 것이다

그래서 이러한 현상들을 모두가 재미있어했는데
위 The Alignment problem이라는 책에서 발췌를 해왔는데 한 번 읽어보자
이런 word2vec이 나온 뒤에 사람들이 이걸 너무 재밌어했는데
이걸 가지고 여러가지 장난을 쳐보다가
doctor에서 man을 빼고 woman을 넣었더니
갑자기 nurse라는 단어가 나오게 된 것이다
그래서 이러한 부분들에서 word2vec이 bias가 있다는 것을 알게 된 것이다

nurse와 유사한 다른 예시들도 많았다
그래서 학자들이 이 워드임베딩이 굉장히 편향된 정보를 갖고있단것을 알게 된 것이다
그럼 이게 어떤 문제인가?
알고리즘의 문제인가?
사실 알고리즘 자체는 문제가 없었다
이건 데이터 문제이다
사람들이 써놓은 문장을 가지고 모델이 예측을 하다보니 이렇게 예측을 하게 된 것이다
그냥 사람들이 쓴 훈련 데이터 자체가 bias가 존재했던 것이다
그래서 어떤 사람들은 이건 문제가 되지 않는다고 하기도 했는데
이 책의 저자들은 그렇지 않다고 주장한다
이건 매우 큰 문제고 해결해야하는 문제라고 주장한다
이런식으로 학습이 된 많은 머신러닝 모델들이
우리 세계에서 점점 decision making을 할 수 있는데
이게 결국 더 많은 bias들을 불러올 수 있다는 것이다
에를 들어서 어떤 회사에서 지원자들 각각을 벡터로 만들었는데
프로그래머 직군이라고 해보자
가장 적합한 후보자가 누군지 벡터 유사도로 뽑겠다고하는 간단한 가정을 해보자
그럼 후보자들 중에서는 남성과 관련된 정보가 많기 때문에
후보자들 중에서는 남성이 많이 뽑히게 될 것이다
이런 현상을 비판없이 수용하면 프로그래머들 중에서는 남성이 많이 뽑힐테고
이런 편향성이 계속 확장이 되게 되는 것이다
이러한 모델의 bias는 적극적으로 해결을 해야할 문제라고 이 책의 저자들은 주장한다

아무튼 이렇게 해서 word2vec이 나왔는데 한계들도 많이 있다
원래는 우리가 그냥 space 기반으로 문장을 구분했는데
단어들 중에서 형태소를 기반으로 분해가 되는 것들이 많다
특히 한국어같은 경우
뭐가, 뭐를 등등
이런 애들이 의미적으로 봤을 때는 겹치는 것들이 되게 많은데
space를 기준으로 잘라버리면 각각의 단어들을 독립적으로 학습을 시키게 된다
그래서 사람들이 space를 기준으로 token을 자르는 것이 문제가 된고 생각했고
subtoken embedding을 하자는 흐름으로 이어진다
그리고 아까 나왔던 문제였는데
하나의 단어가 다른 의미를 가질 수 있는데
하나의 단어에 하나의 고정된 벡터를 assign 시키게 되면 유동적이지 못하다
그래서 contexualized word 같은 것을 도입하게 된다

이제 seq2seq에 대해서 한 번 알아보자

이번 섹션에서 보고자 하는 것은
dialouge system의 기본이 되는 seq2seq이다
여기서 제일 중요한 것은 바로 attention mechanism이다

이 seq2seq 모델은 다른 말로 인코더 디코더 모델이라고도 부르는데
크게 인코더파트와 디코더 파트로 구성이 되기 때문이다
인코더는 입력을 받아서 임베딩을 만드는 부분인데
seq token을 받아서 임베딩으로 만들게 된다
decoder 부분은 이걸 text로 디코딩을 하는 부분이다

아무튼 아주 역사가 깊은 것이 seq-to-seq 모델이다
그 중에서도 유명한 것이 recurrent neural network인데
그 중에서도 LSTM이 유명하다
입력이 다 들어오면 디코딩 파트가 시작이 되게 되는데
시작 부분에는 start token을 넣어주고
그럼 첫번째 단어를 예측하게 된다
그 다음 le라는 단어를 짚어넣으면 다음 단어인 film을 예측하고
계속 가다가 stop token이 들어가면 예측을 마치는 것이다
그럼 이걸 학습 시키려면 학습 데이터는 어떻게 구성하면 될까?
input과 output이 있어야하고
끝에는 stop token이 들어가도록
pair로 구성을 하면
입력을 넣었을 때 출력으로 loss가 계산되도록 학습을 시키는 것이다
이게 기본적인 seq to seq 모델의 작동 원리이다

그럼 입력 벡터는 어떻게 넣어주면 될까
one hot vector를 넣어줄수도 있지만 문제가 많기 때문에
앞에서 배웠던 skip-gram등과 같은 알고리즘으로
미리 만들어진 단어 벡터를 넣어주면 된다
one hot vector는 단어에 대한 정보가 별로 없지만
dense vetor는 단어에 대한 정보를 풍성하게 갖고있기 때문에
모델 학습의 효율이 훨씬 올라간다

하지만 이런 seq2seq은 문제가 2개가 있다
첫 번째 문제는 옛날 seq2seq 모델들은
input length에 따라서 성능이 확 떨어지게 된다
이건 여러가지 이유가 있는데 우선 입력 길이가 긴 sentence들이
학습 데이터가 없었기 때문이기도 했고
이 seq2seq 모델을 보면 hidden state가 지금까지 들어온 문장의 정보를
계속 담고있어야했는데 이게 입력이 길어지면 길어질수록
어쩔 수 없이 앞에 나온 정보들을 잊어버릴 수 밖에 없었다
즉, 입력이 길어지면 길어질수록 성능이 떨어지게 되는 것이다
그리고 LSTM이 사실 이런 문제를 해결하기 위해서
short term memory, long term memory를 이용하면서
잊어버릴건 잊어버리고
기억할건 기억하는
이런 메커니즘을 도입하여 해결해보자했지만
잘 작동하지는 못했다

두 번째 문제는 학습데이터로 잘 나오지 않는 rare word에 대한 성능이
떨어진다는 점이다
그래서 이 문제를 해결하기 위해서 옛날에는
corpuse에서 10번 이상 나오지 않는 단어들은 다 통합을 시키자..
뭐 이런 류의 방법들을 썼었는데
오늘날에는 이런식으로 하지 않고 subtoken으로 쪼개서 해결을 하고자 했다
하지만 이런 subtoken으로 쪼개는 방식도 문제가 많이 발생한다고한다
아무튼 이러한 seq2seq 모델은
hidden state의 capacity가 제한되어있다는 문제와
rare word에 대한 워드임베딩을 구하기가 힘들다는 문제
이 2가지 문제를 해결하고자했고
그걸 위해서 나온 것이 바로 attention mechanism이다

그냥 input과 output에 대해서 1대1 번역이 가능하다고 해보자
그럼 우리가 복잡한 모델이 필요가 없다
target sentence를 디코딩할때
첫 번째 디코딩 할 단어는
input에서 첫번째 단어가 뭔지를 보고
the에 해당되는 french를 찾아서 내뱉고 .. 그렇게 하면 되는 것이다
이렇게 하면 일이 굉장히 간단해지게 된다
또 이렇게 하면 hidden state에 대한 burden이 굉장히 줄어들게 된다
그래서 우리가 이런 직관을 가지고 지금 디코딩 할 때
앞에 어떤 단어를 보면 되겠다.. 이런식으로 모델이 작동하도록 만들고 싶은데
하드코딩을 하지않고 어떻게하면 이걸 할수있을까?
하다가 나온 것이 바로
attention mechanism이다

attention에서는 현재 디코딩 state간에 입력 단어들과의
relevant를 계산해서
가장 relevance한 애들을 활용하는 것이 attention mechanism이다
예를 들어서 the movie was great이라는 문장이 들어왔다고 해보자
각각의 입력 단어에 대해서 얼마나 관련성이 높은지를 우선 계산한다
그럼 위와 같은 distribution이 나오는데
이걸 aggregation을 시켜서 decoding을 수행한다
즉, 각각의 단어의 관련성 distribution을 계산한 다음에
이걸 aggregation해서 벡터를 만들고 이걸로 다음 단어를 예측한다
이런식으로 작동을 하는 것이 attention mechanism이다
앞에 있는 단어들의 중요도에 따라서 다른 중요도 score를 주는 것이다

이걸 수학적으로 표현을 좀 하면
위 ppt와 같이 표현을 할 수 있다
단어를 예측하기 전에 attention score로 계산하는 과정이 들어간다
이 decoding state는 h bar와 각각의 input 단어들의
hidden state를 가지고 pair wise로 score를 게산한다
이 score를 계산하는 과정에는 여러 가지 함수를 사용해도 된다
아무튼 어떤 함수를 넣어서 2개 단어의 유사도를 계산을 한다
이걸 각각의 입력단어에 대해서 따로따로 계산을 한다
우리가 원하는건 이걸 확률분포로 구하고 싶은 것이다
그래서 여기에 softmax를 취해서 확률분포로 만들어준다
그 다음에 weighted sum을 취하게 된다
단어들 각각이 원래는 hidden state를 갖고 있었는데
이 attention의 비중에 따라서 sum을 해준다
이렇게 해서 하나의 context vector를 만들어낸다
이 context vector에는 input 단어들의 hidden state 정보가
aggregation이 되어있는 vector가 되는 것이다
이건 관련이 높은 input 단어의 정보는 더 많이 들어가고
관련이 없는 단어의 정보는 적게 들어간 C1 vector가 나오게 된다

아까 위에서 설명할 때 유사도를 계산하는 함수는
아무 함수나 쓴다고 했는데
실제로 가장 많이 쓰는 함수는 dot product이다
그런데 이건 2개의 dimension이 동일할 때만 가능한데
그냥 concat을 해서 W를 곱한다던지 여러가지 변주를 줄 수는 있다
위에 여러가지 유사도 함수들이 있는데
뭐 이 중에 어떤게 제일 좋다.. 이런건 없다

attention mechanism에 대해서 알아보자
입력 text가 들어갔을 때 디코딩을 시작한다
input 단어와 첫 번째 단어의 hidden state와 dot product를 해서 벡터가 나오고
두 번째 단어에 대해서도 마찬가지다

이렇게 각각 dot product한 값들을 softmax를 취해서 확률 분포로 만들고
이 weight를 기반으로 aggregate해서 하나의 context vector로 만들어준다
이 context vector에는 중요한 단어의 정보가 더 많이 담겨있게된다

그럼 이렇게 attention mechanism을 썼을 때의 장점을 알아보자
영어를 프랑스어로 번역하는 모델에 대한 heatmap을 보자
위 Heatmap은 각각 하나의 디코딩 스텝들이고
모델이 각각의 단어들에 얼만큼의 attention을 줬는지를 표현한 것이다
첫 번째 토큰을 디코딩 할 때 보면
첫 번째 단어에 굉장히 큰 attention이 들어간 것을 볼 수 있다
두 번째도 마찬가지
대부분 이렇게 diagonal에 큰 attention이 취해지는 현상이 발견된다
모델이 그렇게 학습이 된 것이다
중간에 어긋나는 경우도 있는데 이건 프랑스어와 영어의 어순때문일것이다
그래서 우리가 기대했던 것처럼 encoder의 hidden state가
더 이상 엄청난 history를 저장할 필요가 없어진다
그 단어가 어떤 단어인지 identity 정보만
그 relevance 정보만 인코더가 담고있으면 되는 것이고
decoder도 그냥 input에서 들어온 것들 중에서
어떤 단어가 가장 중요한지 선택할 수 있을정도만 되면 되는 것이다
굉장히 간단해진 것이다
word-by-word translation을 하는데에 필요한
딱 그정도로만 hidden state를 담고 있도록 학습을 하면 되는 것이다

그렇다면 오늘 강의를 요약해보고 수업을 끝내보자
word2vec과 seq2seq에 대해서 배웠는데
seq2seq은 input sentence를 output sentence로 바꾸는 기본적인 구조이고
dialogue의 기본이 되는 구조이다

attention mechanism을 통해서는 우리가 무엇을 할 수 있었나?
input 단어들의 정보를 합쳐서 하나의 context vector로 만들었었다
이걸 바탕으로 해서 다음 단어를 예측했다
이 과정을 개념적으로 생각해보면 CBOW에서 하는 것과 굉장히 비슷하다
물론 예측하는 단어의 위치는 다르지만 기본적인 idea는 동일하다
단어의 정보들을 합쳐서 우리가 예측하고자하는 단어를 예측을 하자는 것이다
이게 그래서 바로 많은 언어모델들에서 나오는
공통적이고 기본적인 spirit이 된다