본 게시글은
서울대학교 데이터사이언스대학원 이상원 교수님의
데이터사이언스 응용을 위한 빅데이터 및 지식기반시스템 강의를
학습을 목적으로 재구성하였습니다

DB에서 Set과 Bas Semantics의 개념을 알아보자
이 두 개념의 가장 큰 차이는
중복 허용 여부이다
Relational Algebra는 보통 Set을 따르고
SQL은 보통 기본적으로 bag semantics을 따르는데
set은 우리가 흔히 수학에서 말하는 집합으로
중복을 허용하지 않는 것이고
bag semantics는 한국어로 멀티셋 의미론이라고 하며
중복되는 튜플도 허용을 한다
SQL에서는 기본적으로 중복을 허용해서
튜플 쿼리 결과를 내놓지만
DISTINCT를 명시해주면 중복을 제거해서 보여준다

이번 수업 시간의 주요 내용인
Divison 연산인다
앞에서 배웠던 primitive operator는 아니지만
보통 all(모든)이라는 semantic을 가진 연산에서 자주 사용된다
위 ppt에서는 예시로
"Find sailors who have reserved all boats"와 같은 쿼리에
자주 사용되는 연산자라고 예시를 들어놓았다
이산 수학 수업을 들으면
모든에 대응되는 Universial Quantifier가 나오는데
Division은 이에 대응되는 개념이라고 한다
그 밑에 A/B 예시로 Division 연산을 제대로 이해해보자
A라는 Relation에는 x, y fields가 있고
B는 y field만 있다
여기서 A/B 연산을 하게 되면
모든 A tuple 중에서
B의 y가 있는 tuple들만 뽑히게 된다

Division 연산의 예시를 더 자세히 살펴보자
B1에 pno 필드만 있고 p2라는 튜플만 존재하므로
A/B1은 pno 필드에 p2를 포함하는 row만 뽑히게 된다
A/B2도 마찬가지로 pno 필드에 p2, p4가 존재하는
A의 row만 뽑히게 된다
A/B3도 마찬가지..

그렇다면 아까 위에서
Division은 관계대수에서 기본 연산자가 아니라고했는데
기본 연산자가 아니라는 것은
기본 연산자로 해당 연산을 구현할 수 있다는 뜻이다
그걸 어떻게 하면 될까?
위 ppt에 나와있는 공식대로 하는데
차근차근 설명해보도록 하겠다
위의 예시와 동일하게 A relation에는 x, y 필드가 있고
B에는 y 필드만 있다
우선 A에서 x 필드만을 뽑는 projection 연산을 수행한다
그런 다음 B에 있는 y와 cross-product 연산을 수행해서
A와 B가 생성할 수 있는 모든 조합을 생성한다
그 중에서 A에 존재하는 값을 차집합으로 제거한다
그렇게 되면 disqualified한 rows만 남게 되는데
일종의 A/B 연산의 A에 대한 여집합이 남게 되는 것이다
따라서 최종적으로 A에서 x를 projection한 것에서
위에서 구한 disqualified tuples를 빼주면
A/B 연산의 최종 결과값이 나오게 된다
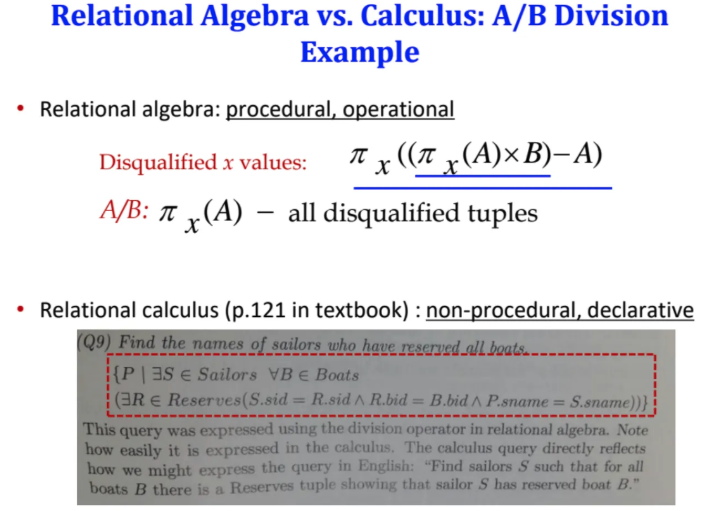
Relational Algebra와 Relational Calculus에서
Division 연산의 차이이다
relational algebra는 이걸 procedure하게 표현하는데
relational calculus는 좀 더 non-procedure하고 declarative하게 표현한다고 한다

Relational하게 생각하라고 한다..
이제부터는 이 relational한 띵킹을 위해서
쿼리 예시들을 보며 어떻게 해결할건지 살펴본다
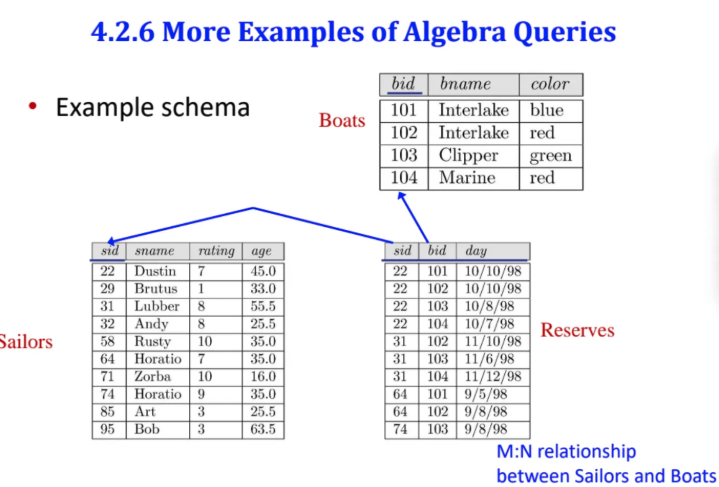
이게 우리가 사용할 예시 table이다
Sailors라는 table이 있고
Reserves, Boats table이 있다
각각 sid, bid가 pk, fk로 연결되어있다

첫 번째 질문은 103번 배를 예약한 선원들의 이름을 찾아내는 것이다
총 3가지 solution이 있는데
가장 효율적이고 가장 대중적인 방법은
Reserves에서 bid = 103인 것만 selection 한 다음
Sailors랑 join을 한 뒤 sname만 proejction 하는 것이다
그다음 solution2와 solution3처럼
해결하는 방법도 있다고 한다

두 번째 질문은
빨간색 배를 빌린 선원의 이름을 찾는 것이다
Boats table에서 color가 red인 것에 대해서
Reserves table이랑 Natural join을 한 다음
그 결과를 다시 sailors랑 natural join을 하면 된다고한다
하지만 위 방법대로 할 때 필요없는 column들이 존재하는데
그 필요없는 column들을 미리 선별하면
쿼리 성능이 더 좋아진다고한다
그래서 Boats에서는 red만 selection한 뒤 bid를 뽑아내고
그걸 Reserves랑 join을 해서 sid만 또 뽑아낸뒤
마지막으로 Sailors랑 natural join을 해서 sname을 뽑아낸다
그런데 우리가 아무리 쿼리를 개떡(?)같이 짜도
DB내부에서 효율적으로 옵티마이징을 해서
최적으로 성능이 나오도록 답을 뽑아낸다고 한다

다섯번째 질문은
(왜 갑자기 건너 뛰었는진 모르겠지만,,)
red나 green boat를 빌린 sailors를 찾는 질문이다
red or green이기 때문에 Boats에서 union을 해준뒤
위 Q2와 같은 방법으로 해주면된다

이건 red and green boat를 빌린 선원을 찾는 질문이다
위에서는 or이라서 union으로 했다면
이건 and라서 교집합으로 해주면 된다

모든 배를 빌린 선원의 이름을 찾는 쿼리이다
이건 division 연산을 사용하면 된다
Reserves에서 sid, bid만 projection한 후
Boats의 bid와 divison을 한다
그런 다음 Sailors과 join을 해주면 된다

우리가 이렇게 표면적으로는 쿼리를 하지만
DBMS는 내부에서 이 쿼리를 어떻게 돌릴지
how를 고민하고
이걸 Relational Algebra로 수행한다고 한다
오른쪽 아래에 막스가 있는데
해당 Relational Algebra가 들어오면
3번처럼 효율적으로 구성해서
최적화시키며 쿼리를 수행한다고한다
여기까지 4장 관계대수의 내용이 끝났다

5장의 내용인데 SQL에 고나한 내용이라고 한다
간단하게 읽어보라고 하셨다

이번 장에선 SQL에 대해서 제대로 배우는데
SQL의 language 표현력에 대해서 배운다고 한다
grouping과 aggregation
recursion과 간단한 data mining까지가 포함된다고한다

거의 매 수업시간마다 나오는 이 Codd 아저씨는
SQL의 창시자라고 하신다
이것도 가볍게 한 번 읽어보라고 하셨는데
SQL을 처음 디자인할 때
어떤 점들을 고려했는지를 위주로 보라고 하셨다
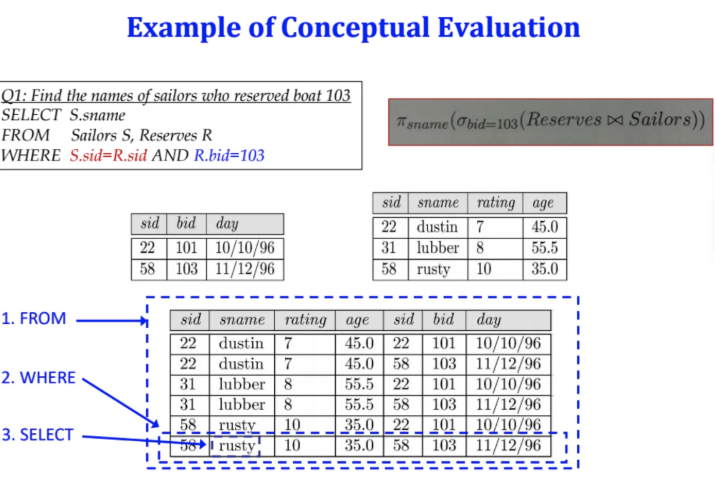
아래와 같은 테이블에서 수행되는
쿼리와 그 쿼리를 수행할 때
DBMS 내부에서 수행되늰 관계대수를 표현한 것이다

where과 join의 비교이다
위 쿼리는 WHERE을 사용해서 join 조건을 명시했고
아래 쿼리는 join시에 조건을 명시했다
내부적으로는 그냥 두 쿼리 모두
동일하다고 한다
원래는 위처럼 where을 사용했는데
세월이 지나면서 명시적으로
join을 시키는 syntax를 지원하고 있다고 한다
그래서 join을 할 때는 join만 사용하고
where은 순수 selection시에만 사용한다고한다

tuple variable에 대해서 잠깐 살펴보자
위 ppt 예시처럼 FROM Sailors S, Reserves R과 같이
테이블에 variable을 명시해주는 것을 tuple variable이라고 한다
사실 tuple variable(혹은 range variable)은
관계대수에는 없는 개념이고 굳이 사용하지 않아도 상관없다
하지만 사용하면 훨씬 더 쿼리가 간결해진다

저번시간에는 관계대수로 배웠던 쿼리질의를
SQL로 바꿔보자
103번 보트를 예약한 sailor의 이름을 찾으라는 쿼리는
SQL로 위 노란색 박스처럼 나타낸다
우리가 저렇게 SQL의 syntax로 작성하면
DBMS 내부에서는 해당 쿼리를
어떻게 수행할지 관계 대수 연산을 결정하는데
가장 무식하게 수행하는건 1번이고
가장 효율적인건 2번인데
두 가지 방식 모두 고려하지만 2번이 비용이 덜 들기 때문에
내부적으로 옵티마이저가 2번과 같이 쿼리를 수행한다고한다
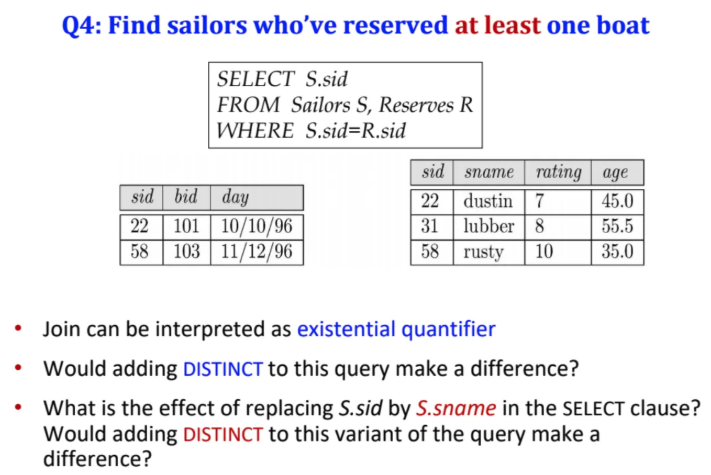
위와 같은 질문에 대해서 해결하려고
쿼리를 작성했다고 가정하자
저렇게 쿼리를 수행하면 sid에서 22가
중복값으로 결과가 나온다고 한다
원래 SQL은 중복을 허용하기 때문에 22가 여러번 나올 수 있지만
이게 싫다면 DISTINCT를 붙여주면 된다

DB에서 string을 표현하는 방식이다
SELECT 뒤에 표기할 column을 명시한뒤
AS 하고 이름을 설정해주면
해당 column은 설정해준 이름으로 나온다
또한 LIKE라는 SQL syntax가 있는데
string matching을 위해 사용하는 구문이다
LIKE syntax에서 _는 아무 한 개의 글자를 표현하고
%는 0개 이상의 임의의 글자를 표현한다

훨씬 더 복잡한 syntax를 표현하고 싶다면
정규식을 사용하면 된다
'강의 > database' 카테고리의 다른 글
| [database] benchbase를 이용한 TPC-C postgreSQL 실습 (1) | 2025.04.04 |
|---|---|
| [database] SQL representation (group by와 having, aggregation, null values 처리) (0) | 2025.03.31 |
| [database] Relational Algebra (selection, projection, cross-product, set-difference, union) (0) | 2025.03.24 |
| [database] View와 Materialized View (0) | 2025.03.24 |
| [database] Relational Database(Primary key와 Foreign key) (0) | 2025.03.16 |