외주로 작업하고있는 개발 프로젝트에서
영어 문단이 있으면
그 문단의 단어별로 녹음파일을
재생해야하는 기능이 있었다
처음에는 모든 녹음파일들을
Google Cloud text-to-speech
기능을 사용해서
front쪽 public 폴더에
넣어놓고 재생해달라고 요청을 받았지만
Google 클라우드 플랫폼
로그인 Google 클라우드 플랫폼으로 이동
accounts.google.com
그렇게하면
단어별로 하나하나 녹음파일을
다운받아야한다는 수작업이 발생하고..
나중에 영어 문단이 바뀌었을 때
새로 작업하기가 꽤나 까다로울 것이라는
생각이 들었다
또, 메모리 용량 측면에서도
문단이 50개나 되는데
너무 무거워지지않을까 하는 생각이들어
API를 검색해보다
Google Cloud에서 text-to-speech
API를 제공하고있다는 것을
찾게되었다
https://cloud.google.com/text-to-speech?hl=ko
https://cloud.google.com/text-to-speech?hl=ko
cloud.google.com
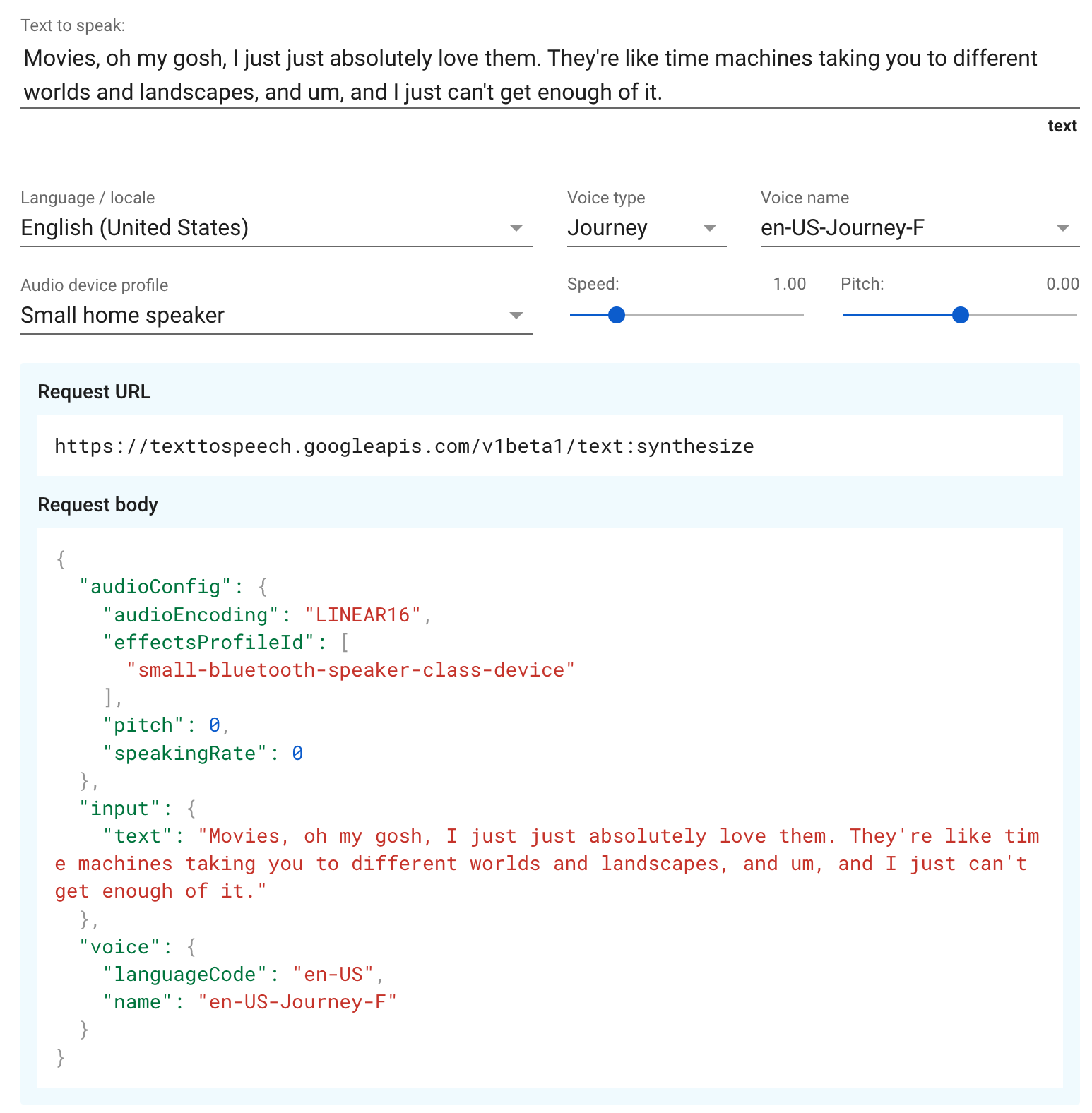
위와같이 body를 담아
요청을 날리면
response로
base64로 인코딩 된
audioText 받게된다
이를 frontend에서
audioURL로 바꾸어서
재생시켜주면 될 것 같았다
가격도 생각보다 합리적인 것 같았고
단어별로 음성을 받아서
재생할 것이기 때문에
그렇게 가격이 부담되는 느낌은 아니었다
아무튼 고용주(?)분의
컨펌을 받아 API_KEY를 발급받아
단어를 클릭할 때 마다
API 요청을 보내 음성을 받아와
재생해주기로 하였다
그 내용을 한 번 정리해보려한다
단계는 크게 3가지이다
1. Google Cloud API KEY 발급받기
2. 문단의 단어를 클릭했을 때
text-to-speech API 요청보내기
3. response로 받아온 base64
URL로 생성해 재생시켜주기
1. Google Cloud API KEY 발급받기
이 부분은
https://blerang055.tistory.com/56
구글 text-to-speech(TTS) API 적용 (feat. Javascript)
TTS (Text to Speech) 란? TTS (Text to Speech)는 오디오 표현을 위해 텍스트 단위를 음성 단위로 변경해야하는 자연스러운 언어 모델링 프로세스입니다. 이는 기술이 구어를 받아 텍스트로 정확하게 기록
blerang055.tistory.com
이 분의 글을 보고 도움을 많이 받았다
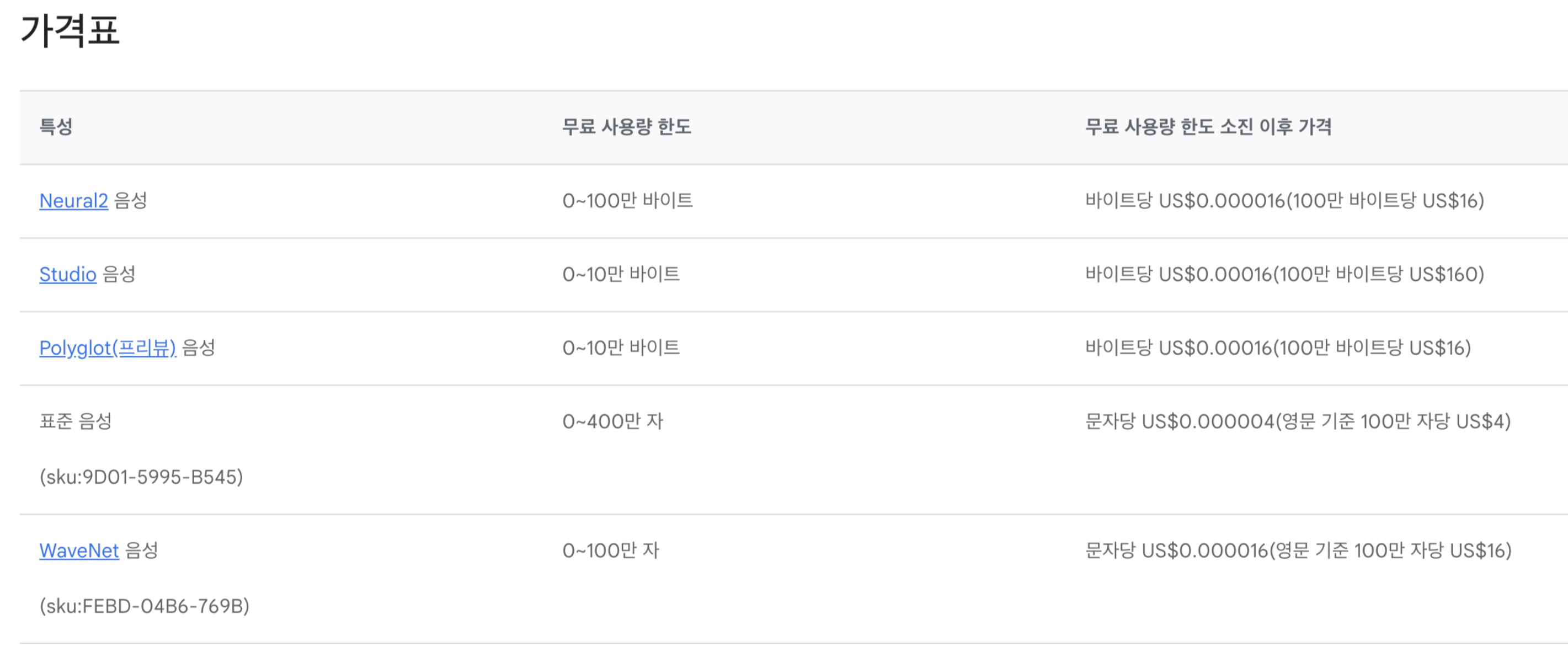
참고로 이 API를 사용하려면
Google Cloud에서
Free Trial을 해주거나
아니면 실제로 계정을 activate해야한다
Free Trial을 하면
3개월동안 40만원의 credit을 준다
1. Google Cloud 로그인 한 후 새 프로젝트 생성
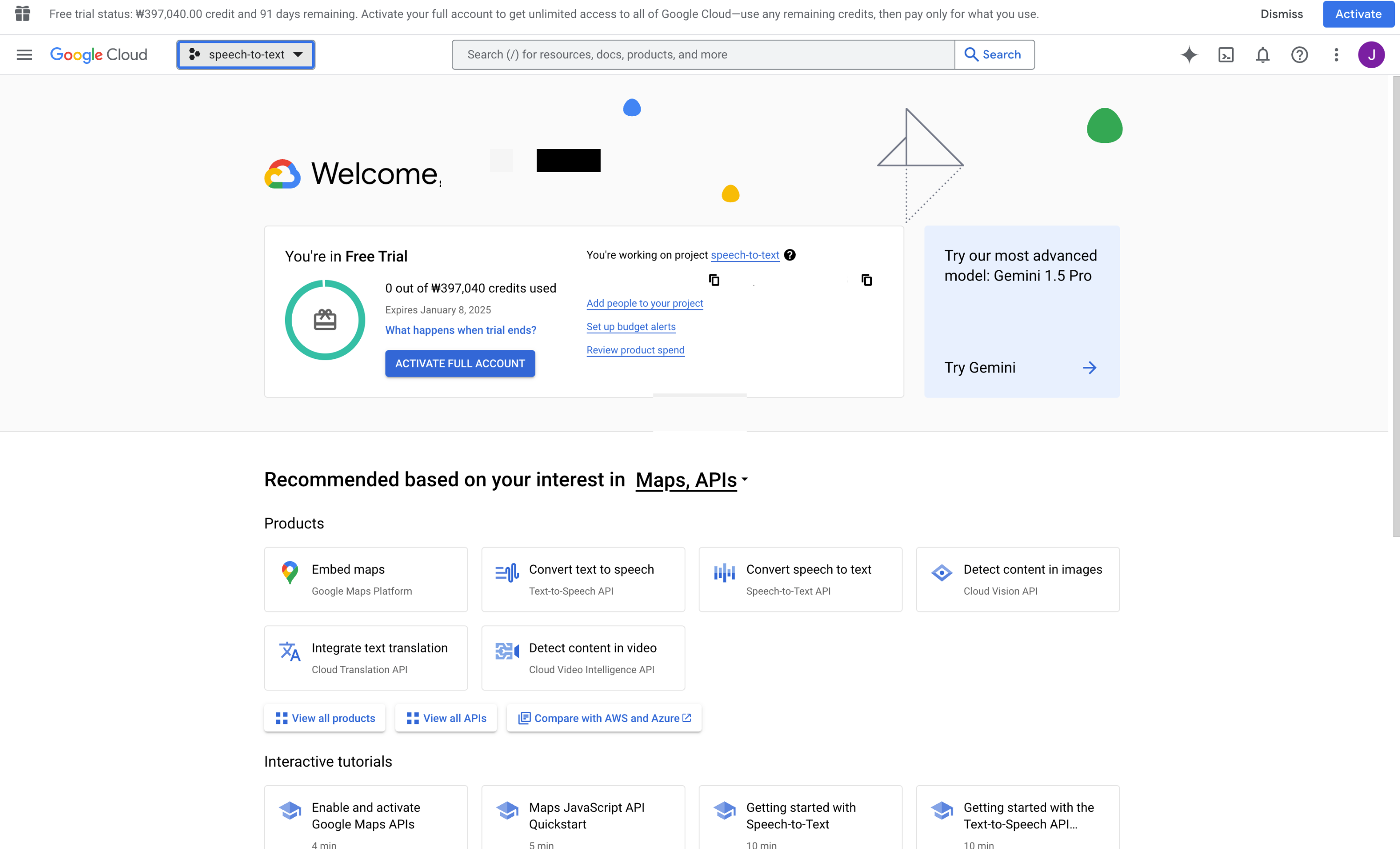
가장 위의 GoogleCloud 오른쪽의
projects dropdown을 클릭한다
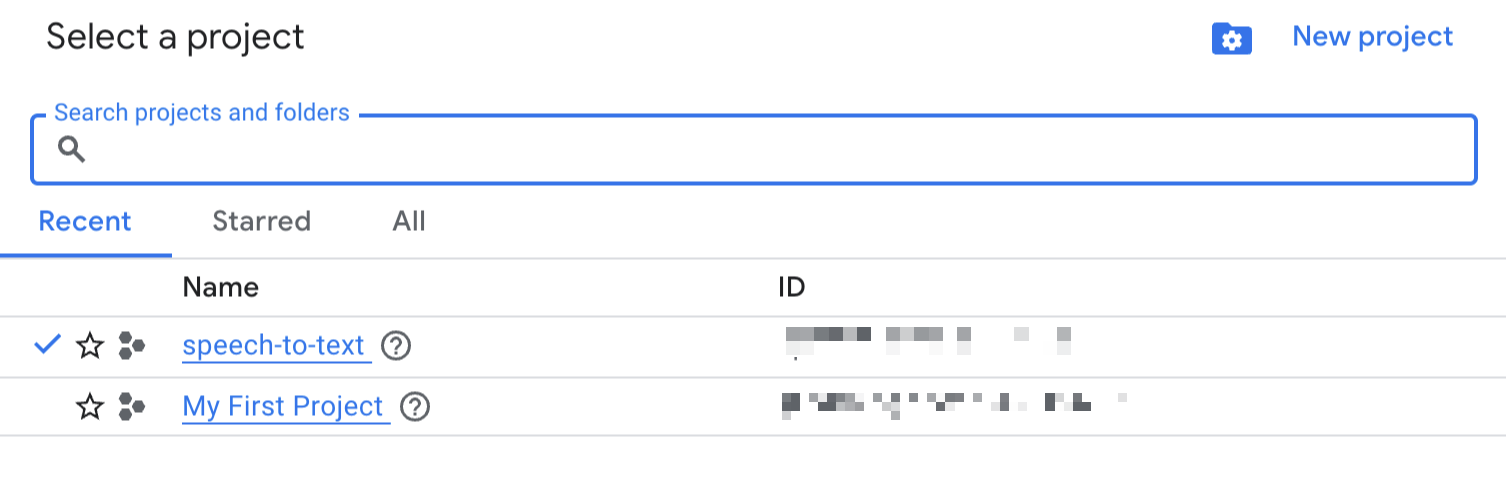
그럼 아래와 같은
모달이 뜨는데
기존에 프로젝트가 있다면
사용해줘도되고
New Project를 눌러
새로 생성해줘도된다
나는 깔끔하게 새로 생성해줬다
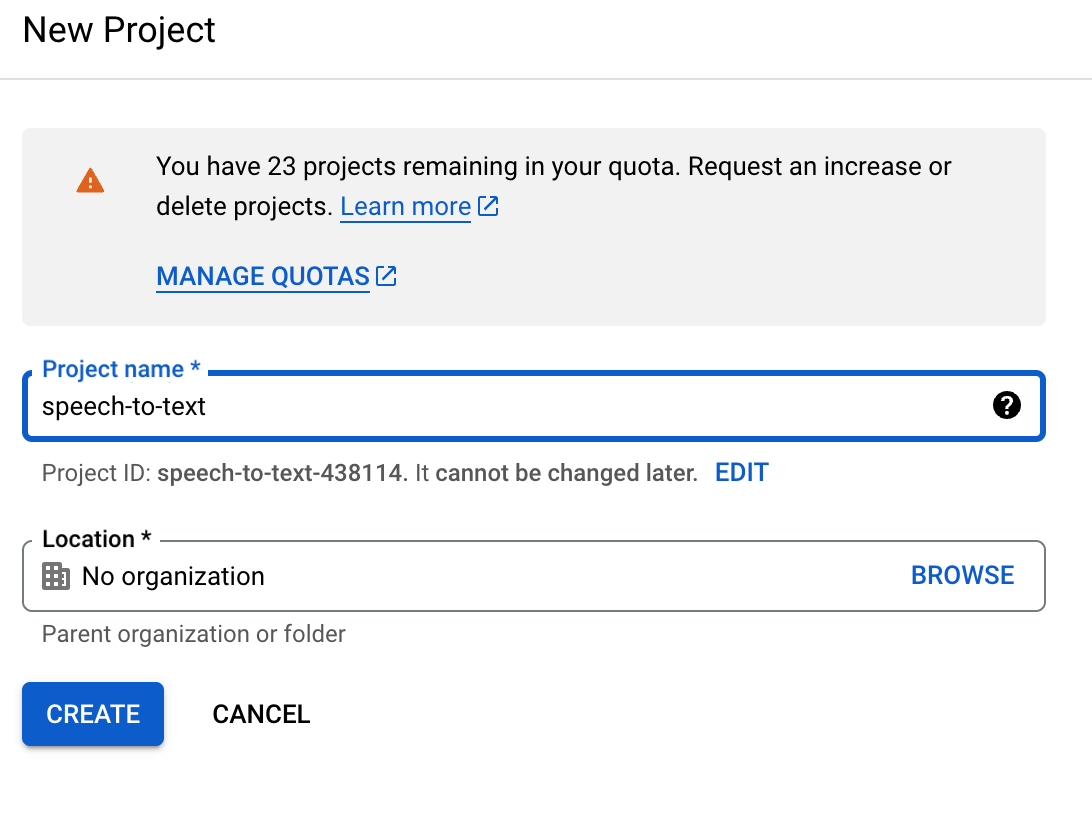
이렇게 한 다음 CREATE를
눌러준다
2. Google Cloud CLI로 Access Token 등록
내가 소개한 게시글에는
Google Cloud SDK를
로컬에 다운받아서
gcloud 설정을 해주라고 나와있었기에
그대로 따라하긴했는데
https://codelabs.developers.google.com/codelabs/cloud-text-speech-python3?hl=ko#1
Python에 Text-to-Speech API 사용 | Google Codelabs
이 튜토리얼에서는 Text-to-Speech API를 Python과 함께 사용하는 방법을 알아봅니다.
codelabs.developers.google.com
이 게시글을 참고하면
google cloud에서

저 Activate Cloud Shell을 누르면
shell을 통해서 접속할 수 있는데
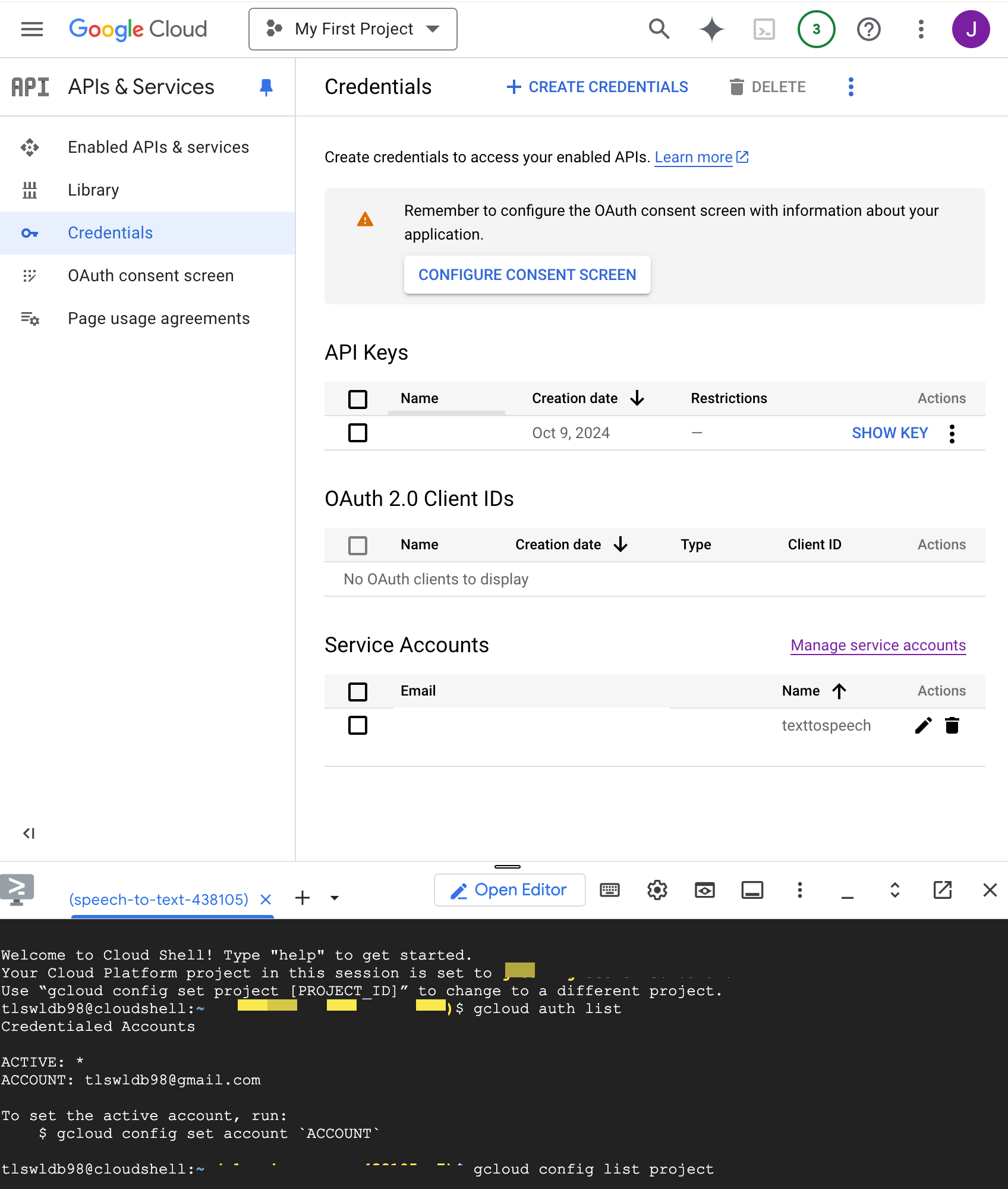
이렇게 아래에 shell로 접속해서
google cloud SDK로
gcloud를 설정해줄 수가 있는데
로컬에서 SDK 다운안받고
저렇게 해도 되지않을까싶다
(나도 안해봐서
되는지 안되는진 모르겠다)
아무튼
저렇게 shell에 접속해서하든
로컬에 SDK를 다운받아주든
https://cloud.google.com/sdk/docs/install-sdk?hl=ko
빠른 시작: Google Cloud CLI 설치 | Google Cloud CLI Documentation
Google Cloud CLI를 설치하고 몇 가지 핵심 gcloud CLI 명령어를 실행하는 방법을 알아봅니다.
cloud.google.com
어떻게는 gcloud 설정을 해준다
만약 로컬에 다운받았다면
google-cloud-sdk/bin/gcloud
실행파일이 있을텐데
./google-cloud-sdk/bin/gcloud gcloud init
이런 방식으로 명령어를 입력해주면
정상적으로 실행된다
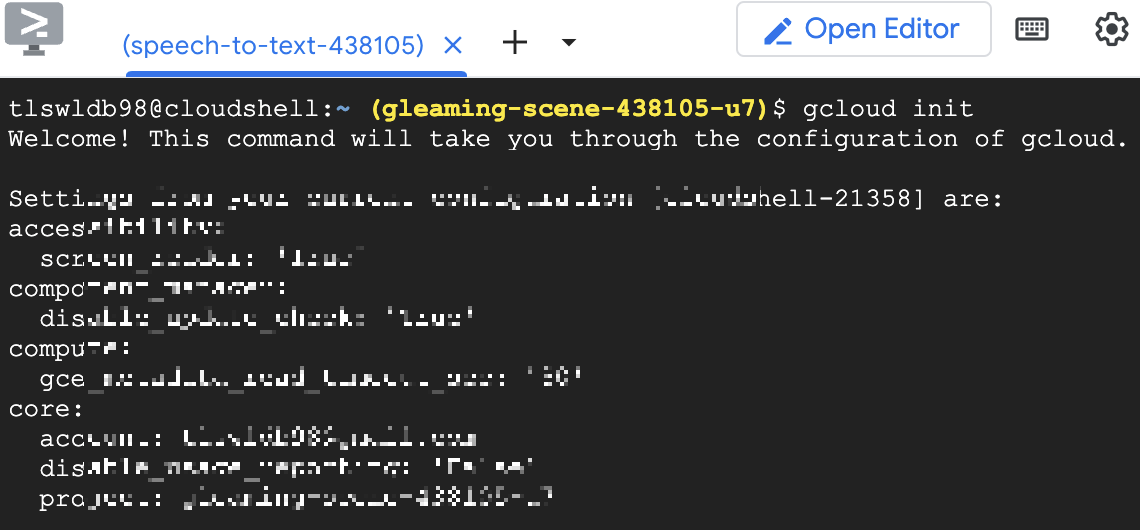
처음에는 gcloud init
을 입력해준다
아마 처음이면 로그인하라고 할 텐데
y를 누른다음 뜨는 창에서
아까 프로젝트를 생성했던 계정으로
로그인을 하면 된다
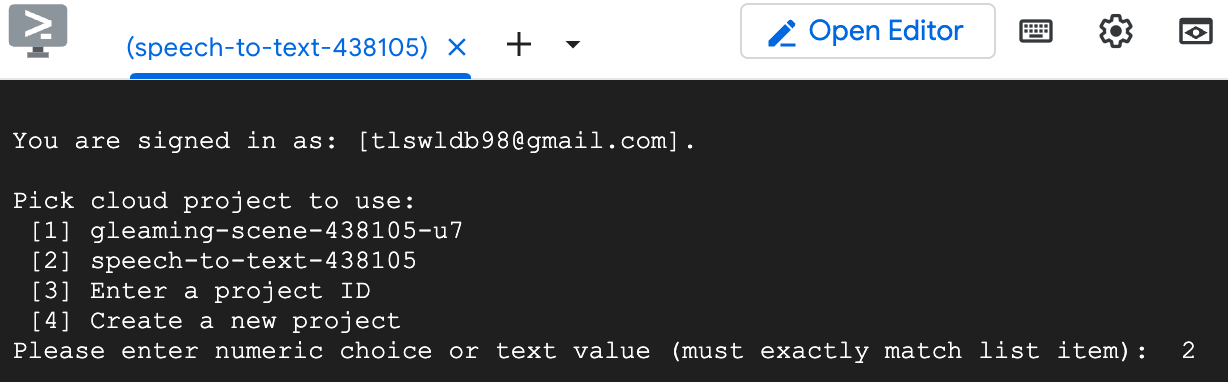
그 다음에 사용할 프로젝트를
선택하라고 뜰텐데
아까 새로 만들었던
프로젝트를 선택해줬다
번호를 입력하면돼서
2를 입력해줬다
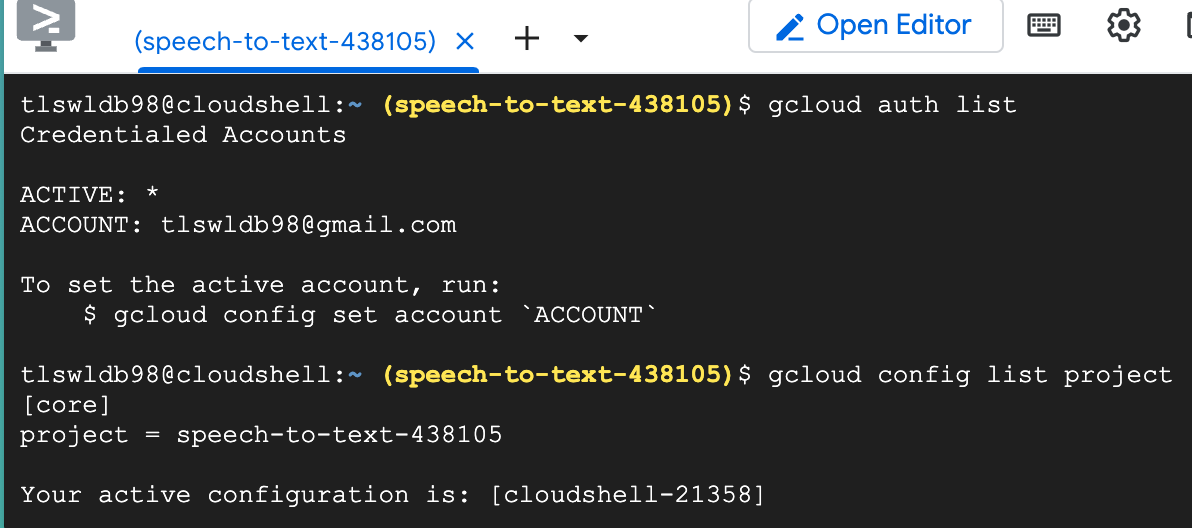
그다음
gcloud auth list
명령어를 입력해서
내 Account가 잘 나오고
gcloud config list project
명령어를 입력해서
아까 앞에서 선택해줬던 프로젝트가
잘 나오는걸 확인하면
초기 환경설정은 끝
이제 API KEY를 받아와줘야한다
3. API KEY 받아오기
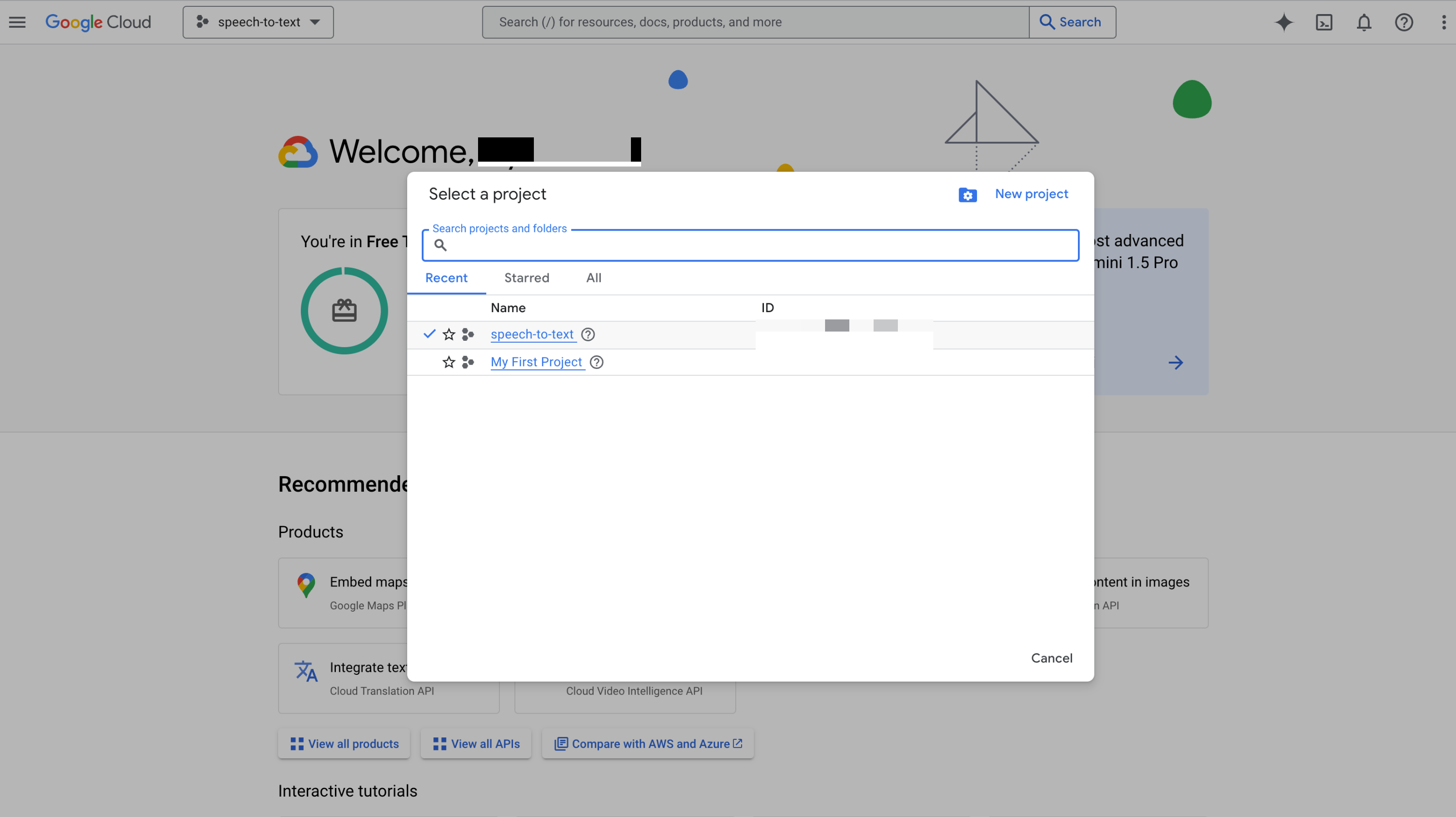
아까 프로젝트 리스트에서
설정해준 프로젝트로 접속한다
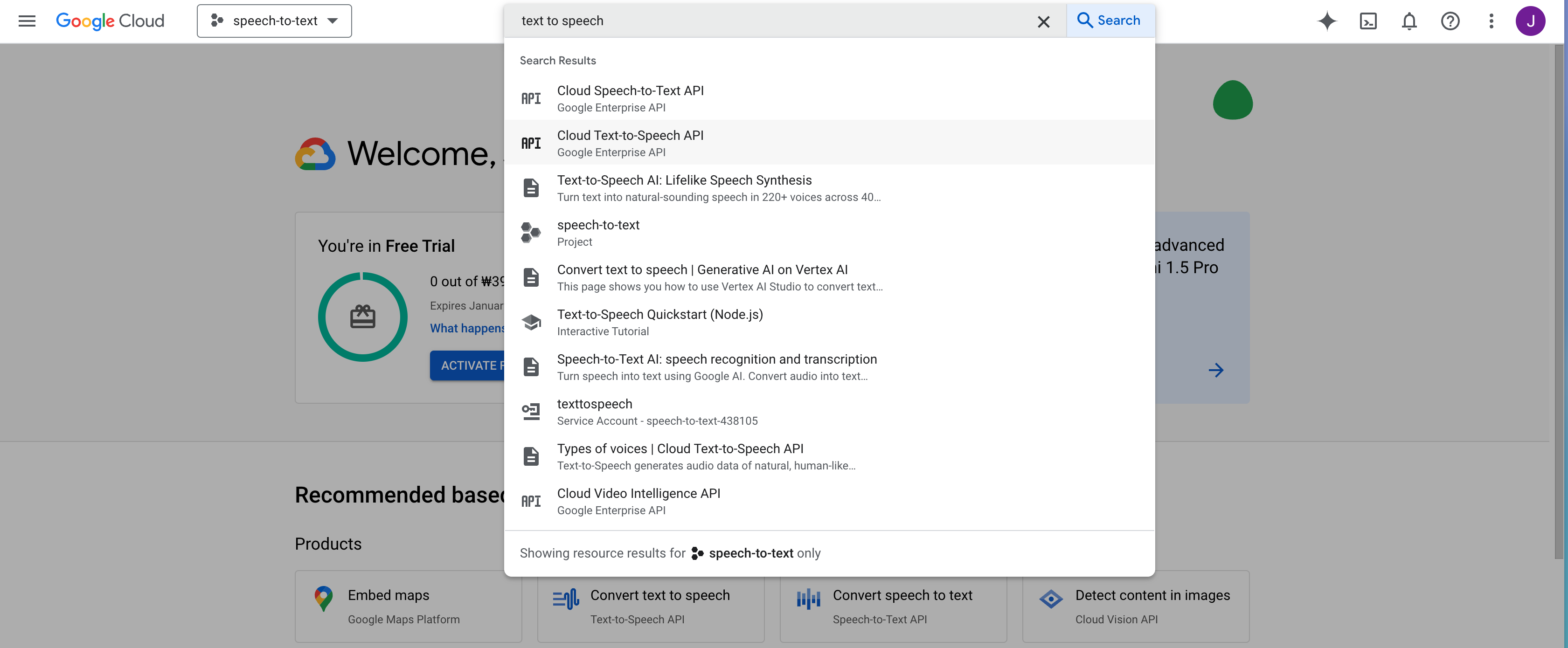
그 다음 검색창을 켜서
text to speech를 검색한 뒤
Cloud Text-to-Speech API에
들어간다
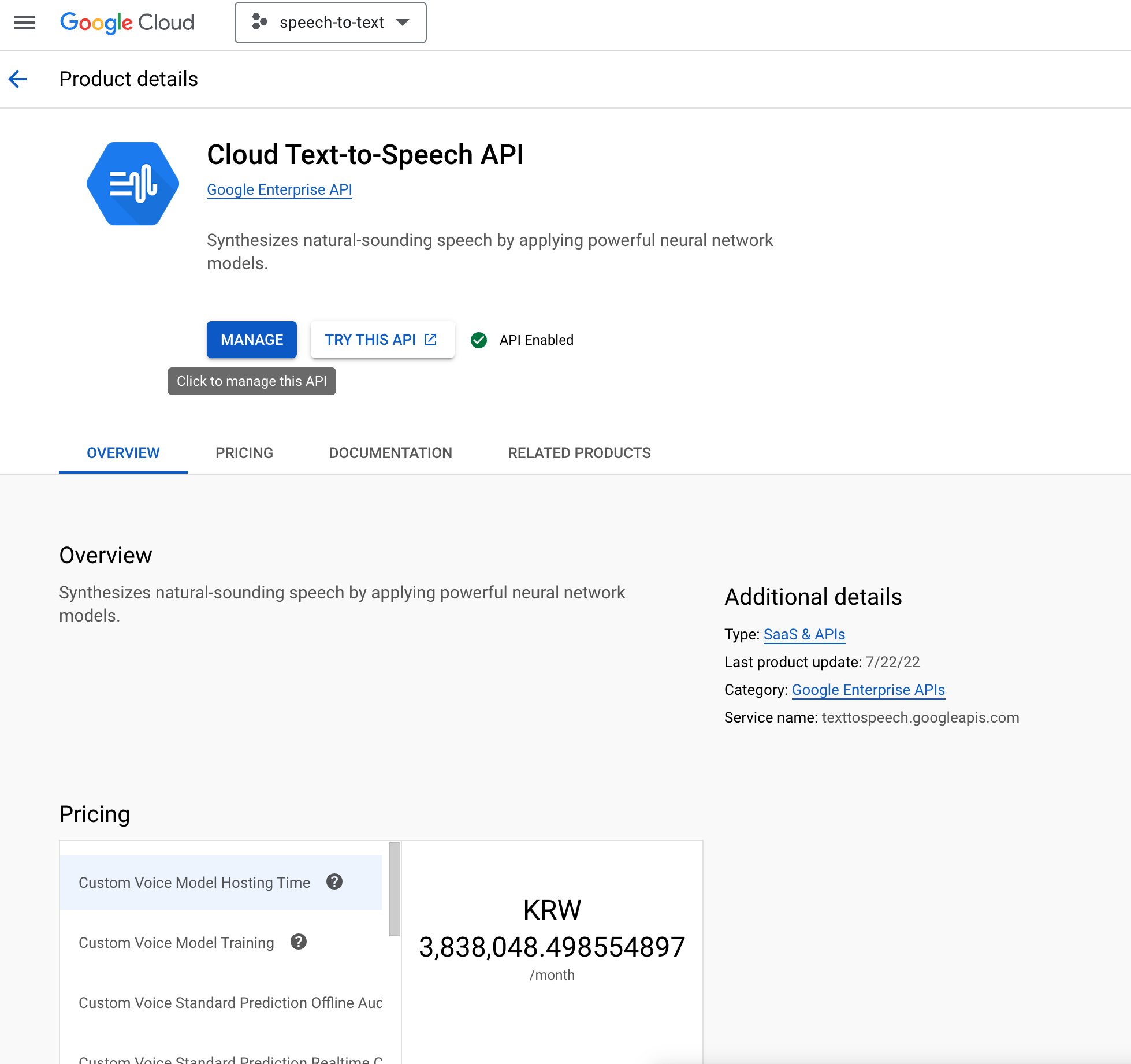
그럼 이런 화면이 뜨는데
처음 접속하면
MANAGE가 아닌
ENABLE이 뜬다
거기서 ENABLE을 시켜줘야
API를 사용할 수 있다
아무튼 활성화 시켜준다음
MANAGE 화면으로 이동
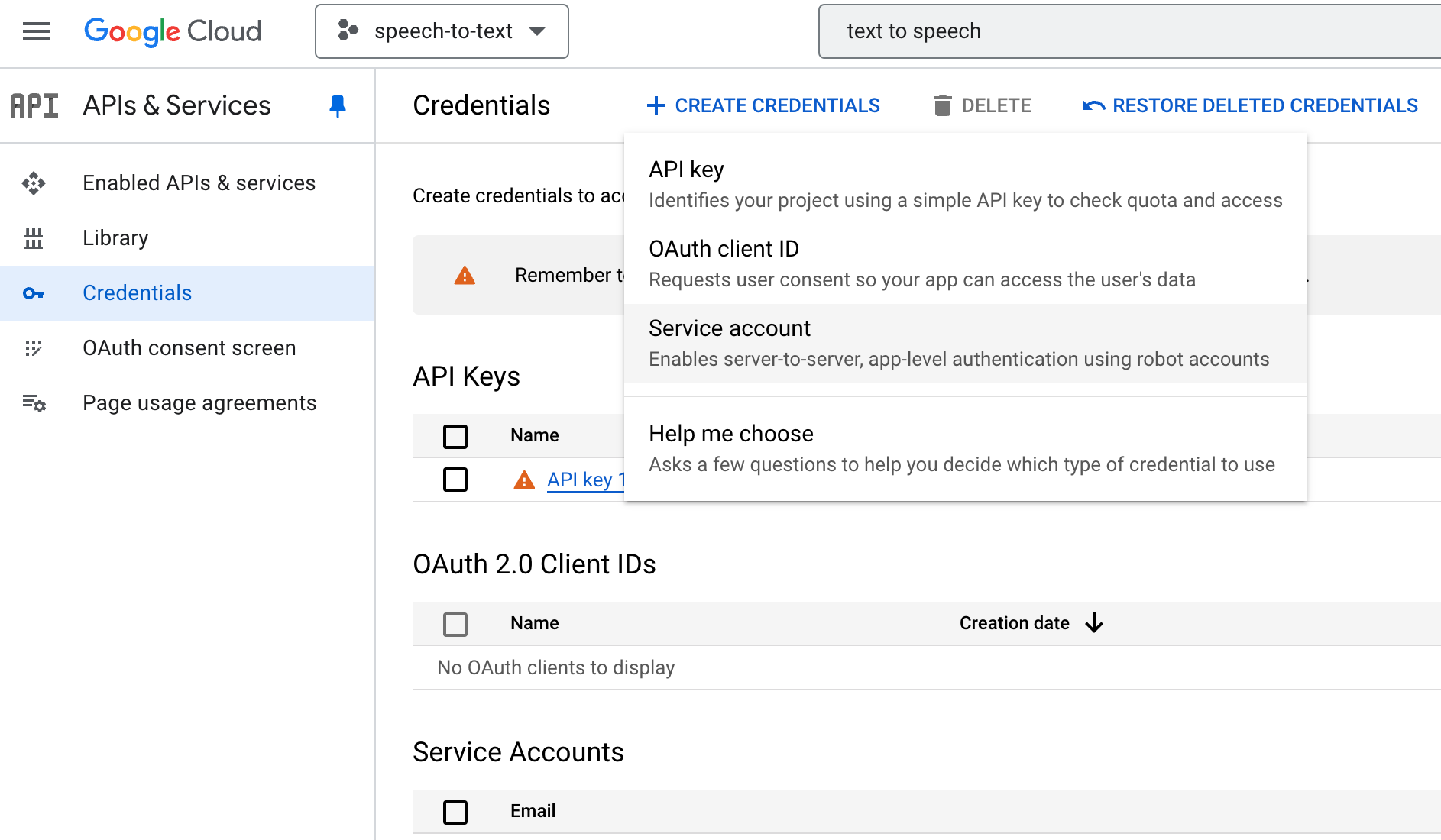
그런 다음 Credentials에 들어가
CREATE CREDENTIALS를 클릭
Service account를 만들어준다
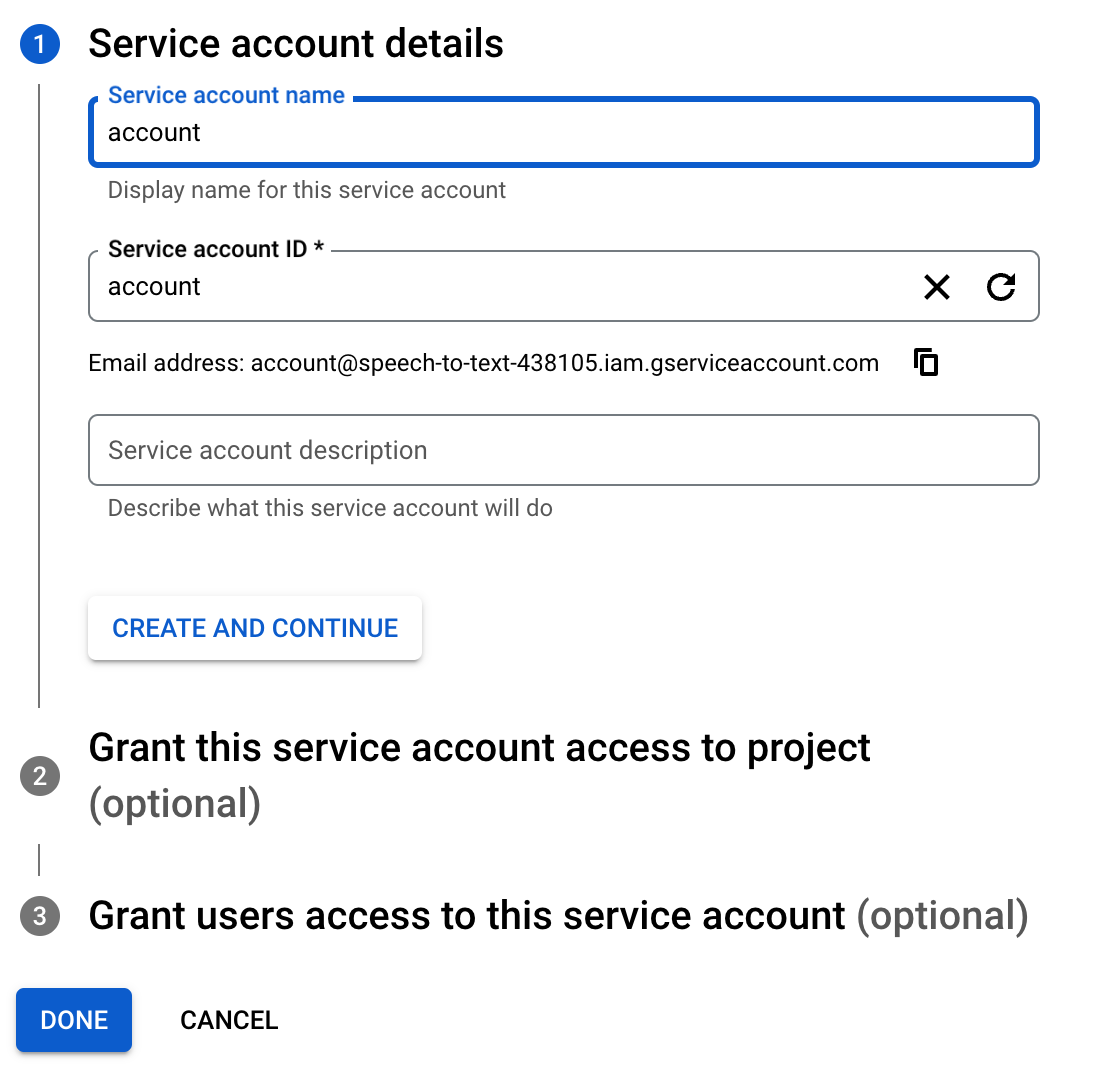
이름을 입력해준 뒤
CREATE AND CONTINUE를 클릭
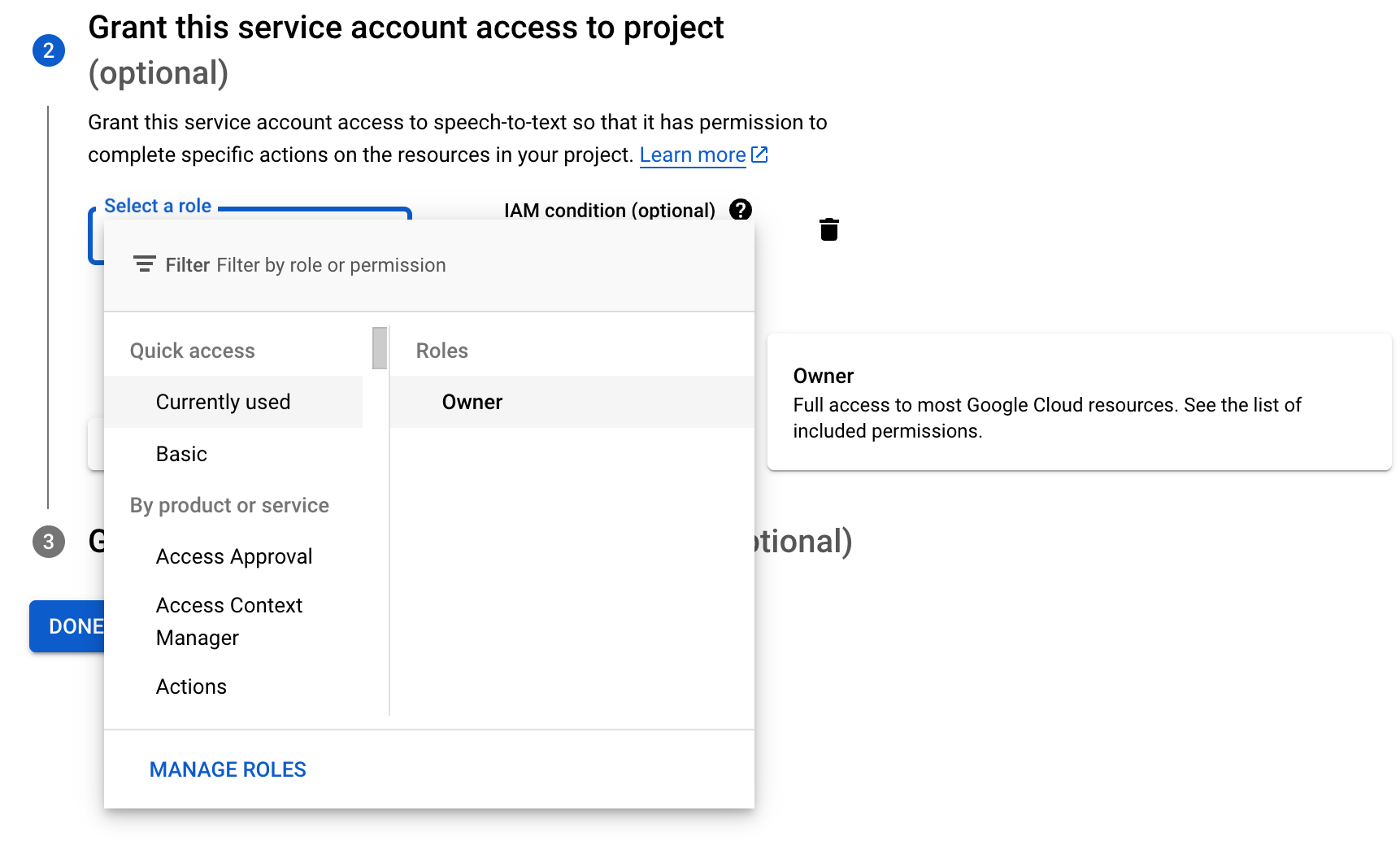
여기서 반드시 Roles를
Owner로 해야한다고한다
그런다음 DONE을 눌러주면
계정 생성 완료
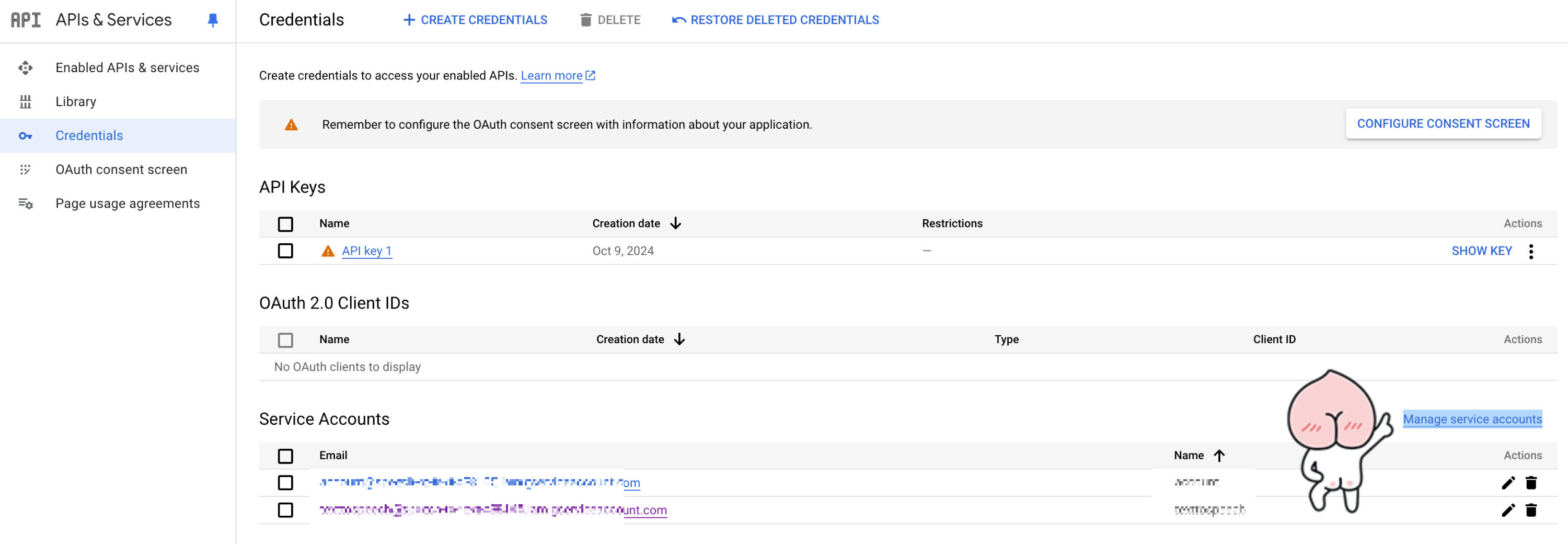
그럼 생성된 계정이
Service Accounts에 뜰테고
오른쪽에 어피치가 가리키고있는
Manage service accounts를
클릭해준다
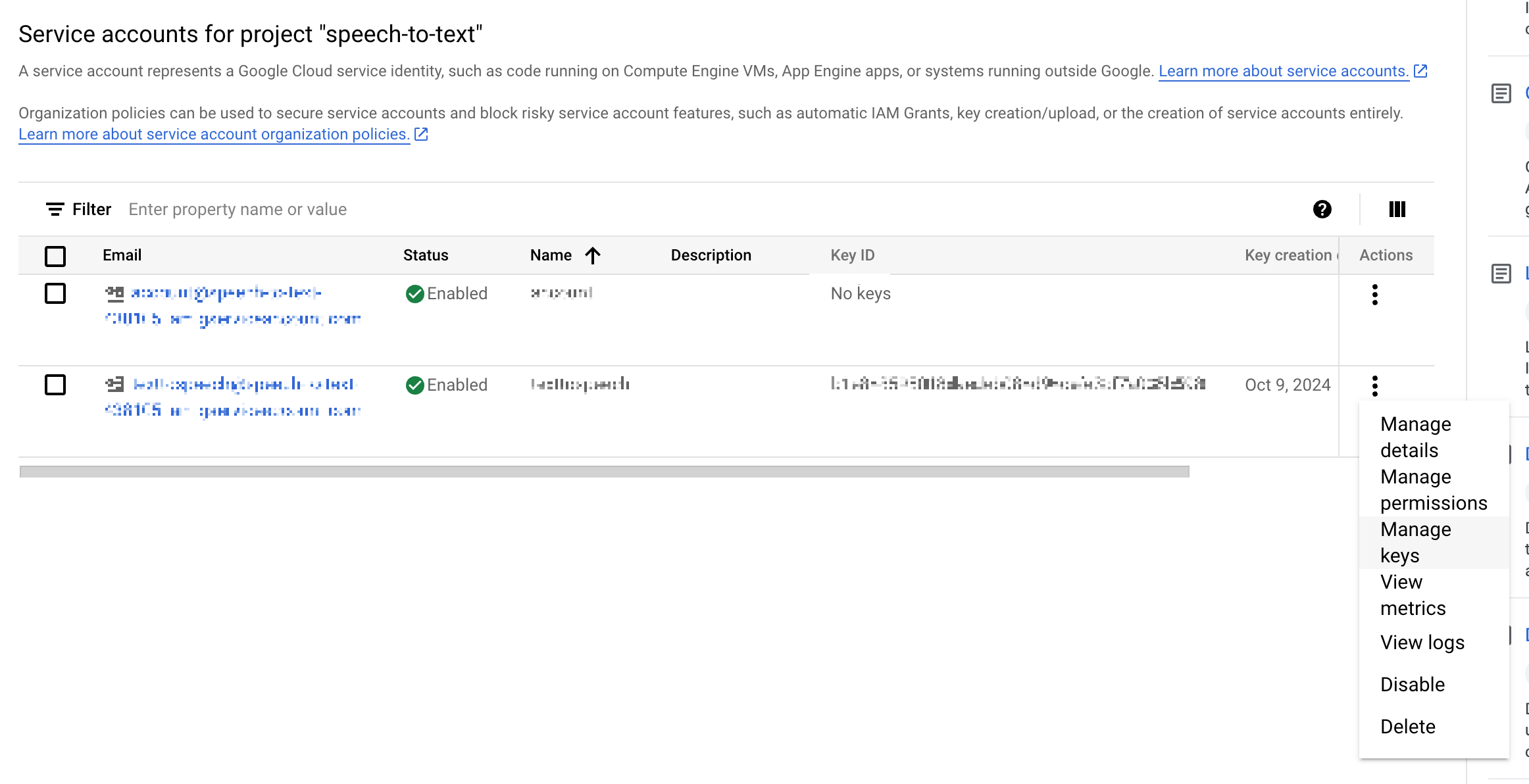
그럼 이렇게 account list가 뜰텐데
아까 생성한 account에서 actions를
클릭한 다음
Manage keys를 클릭
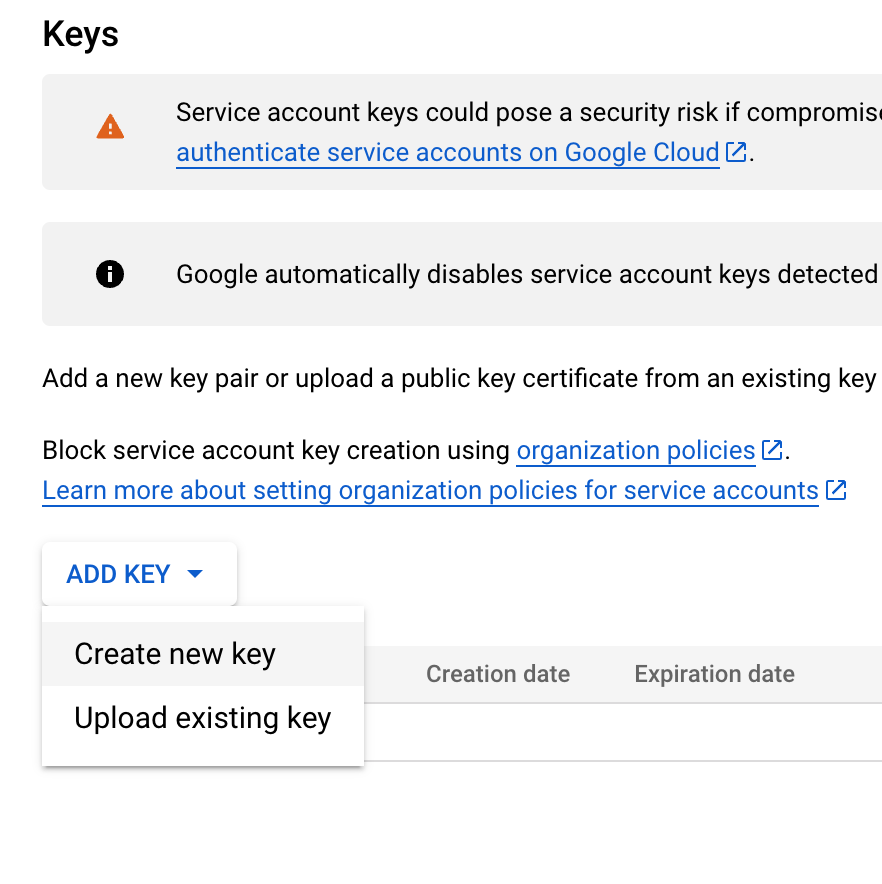
여기서 ADD KEY를 누른 뒤
Create new key 클릭

json으로 선택한다음
CREATE를 누르면
JSON으로 된 private key 파일이
로컬에 Downloads 경로에 저장된다
윈도우 환경에서는
다운받아진 JSON파일을
환경변수로 설정해서
넘겨줘야하는 모양이었는데
난 .. Mac OS였는데
환경변수 설정하는법
찾아보기 귀찮아서
설정해주지않고
그냥 진행했는데 어찌됐건 되긴했다(..?)
아무튼 이제 처음 다시
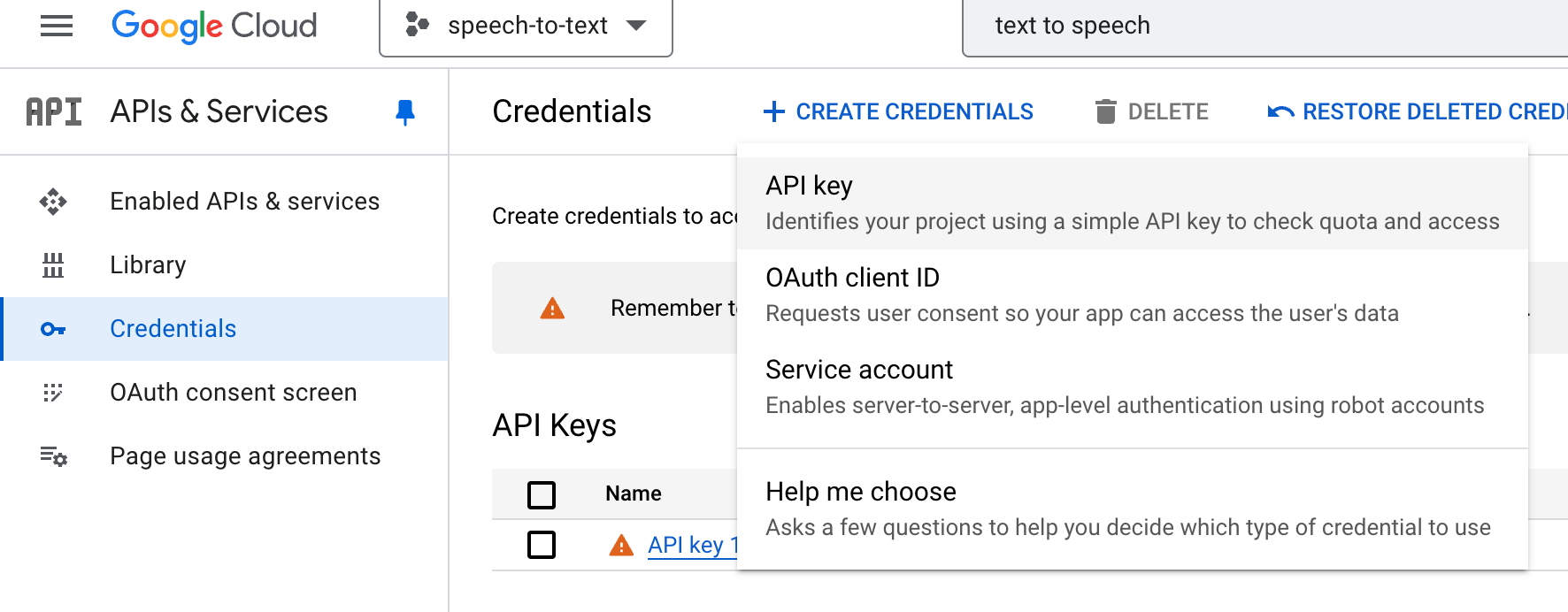
그 프로젝트 관리화면으로 돌아와서
CREATE CREDENTIALS에서
API key를 클릭
API key가 생성중이라며
로딩화면이 나타난다
그러고 생성이 완료되면
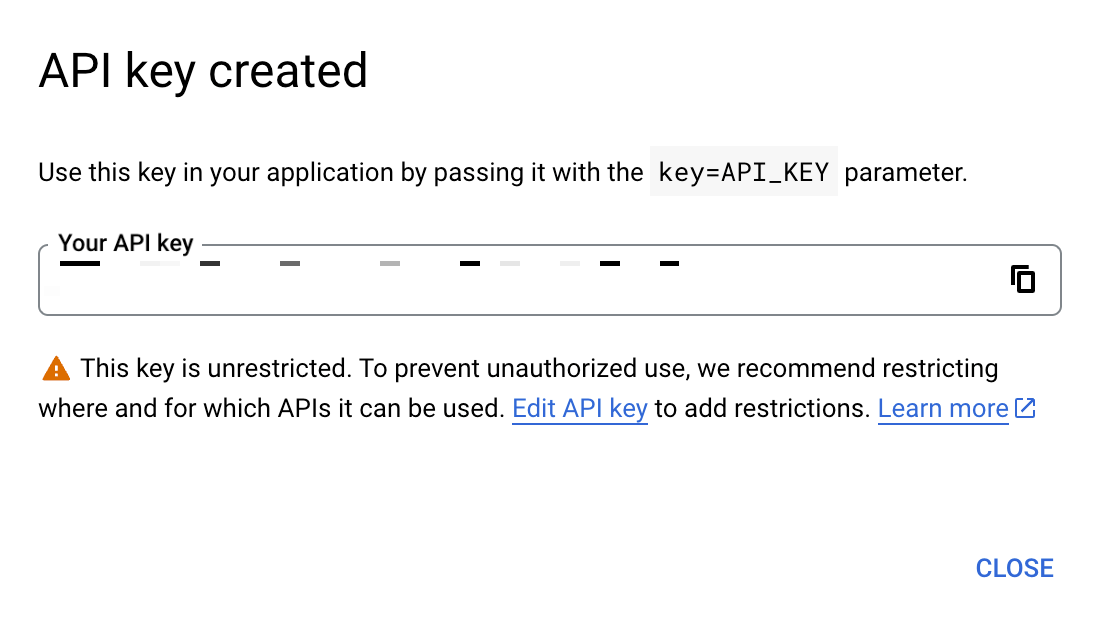
이렇게 생성된 API KEY가 나타난다
위에도 말했지만 중간에
private key JSON 파일을
환경변수 설정해주라는
설명이 있었는데
나는 그냥 skip했는데
정상적으로 잘 되긴했다
만약 API KEY 생성에 문제가있다면
해당부분 검색해서 하면 될 것 같다
아무튼 이렇게 해주면 이제
요청 url 끝에
key = API_KEY
이렇게 붙여서 요청을 날릴 수 있다
요청 url은
https://texttospeech.googleapis.com/v1/text:synthesize?key={API_KEY}
이렇게해서 날렸고
key = 이후로
앞에서 만들어준 API KEY를
넣어주면 된다
body에는 google에서
예시를 사용해서
아래와 같이 json을 날려줬다
{
"audioConfig": {
"audioEncoding": "LINEAR16",
"effectsProfileId": [
"small-bluetooth-speaker-class-device"
],
"pitch": 0,
"speakingRate": 0
},
"input": {
"text": "Hello My name is Xinchao"
},
"voice": {
"languageCode": "en-US",
"name": "en-US-Journey-F"
}
}
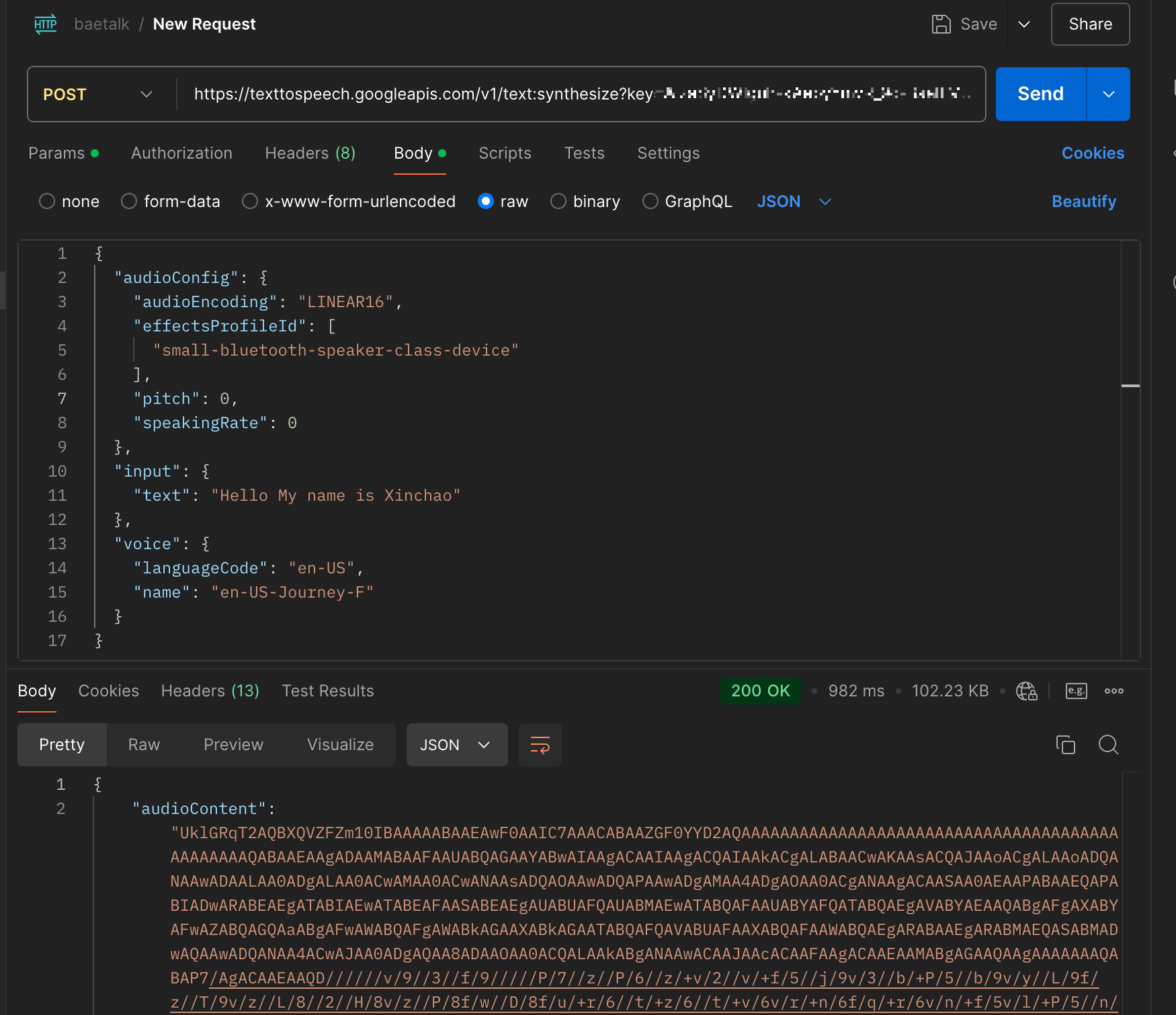
postman으로 테스트해보니
결과가 잘 나오는 것을
확인해줄 수 있었다
이후 frontend에 넣어줄 때는
option을 따로 지정해줄 필요는 없어서
request body를
간단하게만 넣어줬다
{
"audioConfig":{
"audioEncoding":"mp3"
},
"input": {
"text": "Hello My name is Xinchao"
},
"voice": {
"languageCode": "en-US"
}
}
이제 API KEY를 통해서
요청을 성공적으로 받아온다는 것을
확인했으면
프로젝트에 이식해주자
4. frontend에서 API 요청하기
응답으로 받아오는 base64를
byte로 바꾼 다음 Blob으로 변환시켜줬다
function base64ToBlob(base64Data, contentType) {
const byteCharacters = atob(base64Data);
const byteArrays = [];
for (let offset = 0; offset < byteCharacters.length; offset += 512) {
const slice = byteCharacters.slice(offset, offset + 512);
const byteNumbers = new Array(slice.length);
for (let i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
const byteArray = new Uint8Array(byteNumbers);
byteArrays.push(byteArray);
}
return new Blob(byteArrays, { type: contentType });
}
함수는 이렇게 작성해줬다
그런 다음
useEffect를 사용해서
speech로 변환할 단어인
word가 들어올 때만
API를 요청하도록
코드를 작성해줬다
나같은 경우는
요청을 보낸 다음
base64를 Blob으로 만들어
그 Blob이 src로 들어간
Audio Player를
렌더링해줘야했으므로
await을 사용해서
응답이 받아온 뒤에
화면에 렌더링되도록 해줬다
useEffect(() => {
async function fetchAudio() {
try {
const response = await axios.post(`https://texttospeech.googleapis.com/v1/text:synthesize?key=${apiKey}`, {
voice: {
languageCode: "en-US"
},
input: {
text: word
},
audioConfig: {
audioEncoding: "mp3"
}
});
const base64AudioContent = response.data.audioContent;
const audioBlob = base64ToBlob(base64AudioContent, 'audio/mp3');
setAudioBlob(audioBlob);
setLoading(false);
} catch (error) {
console.error('Error fetching audio:', error);
setError(true);
setLoading(false);
}
}
fetchAudio();
}, [word]);
그런 다음
Loading일 때는
로딩중이라는 text가 보이도록
모든 과정을 성공했으면
Audio Player 컴포넌트가 보이고
만약 실패했으면
실패를 알리는 text가 뜨도록 해줬다
전체코드는 아래와같다
CustomAudioPlayer는
내가 직접 만들어준 AudioPlayer다
function WordAudioPlayer({ word }) {
const [audioBlob, setAudioBlob] = useState(null);
const [audioDuration, setAudioDuration] = useState(null);
const [loading, setLoading] = useState(true);
const [error, setError] = useState(false);
const apiKey = process.env.REACT_APP_GOOGLE_API_KEY;
useEffect(() => {
async function fetchAudio() {
try {
const response = await axios.post(`https://texttospeech.googleapis.com/v1/text:synthesize?key=${apiKey}`, {
voice: {
languageCode: "en-US"
},
input: {
text: word
},
audioConfig: {
audioEncoding: "mp3"
}
});
const base64AudioContent = response.data.audioContent;
const audioBlob = base64ToBlob(base64AudioContent, 'audio/mp3');
setAudioBlob(audioBlob);
setLoading(false);
} catch (error) {
console.error('Error fetching audio:', error);
setError(true);
setLoading(false);
}
}
fetchAudio();
}, [word]);
function base64ToBlob(base64Data, contentType) {
const byteCharacters = atob(base64Data);
const byteArrays = [];
for (let offset = 0; offset < byteCharacters.length; offset += 512) {
const slice = byteCharacters.slice(offset, offset + 512);
const byteNumbers = new Array(slice.length);
for (let i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
const byteArray = new Uint8Array(byteNumbers);
byteArrays.push(byteArray);
}
return new Blob(byteArrays, { type: contentType });
}
if (loading) {
return <p className='text-sm text-gray-300'>Loading audio...</p>;
}
if (error) {
return <p className='text-sm text-gray-300'>오디오를 불러오는데 실패했습니다.</p>;
}
return (
<CustomAudioPlayer audioBlob={audioBlob} id={word}/>
);
}
아무튼 이렇게 해준 다음
단어를 클릭할 때마다
위 함수를 실행하게 해줬더니
소리도 기깔나게 잘나오고
AudioPlayer도 기깔나게 잘 렌더링됐다
이렇게 오늘도
이리치이고 저리치이며 시도해보는
개발일지 마무리-!
'기술 > 웹 개발' 카테고리의 다른 글
| [react/tailwind css] 자체적으로 audio player 구현하기 (1) | 2024.10.06 |
|---|---|
| [react] client단에서 마이크를 이용해 녹음한 파일 API로 전송하기(multipart 전송) (2) | 2024.09.05 |
| [FastAPI/python] 파이썬 FastAPI로 정말 간단하게 API 만들기(CORS) (0) | 2024.08.31 |
| [PortOne/react] 통합 결제 연동 솔루션 포트원 react 프로젝트에 이식하기 (2) | 2024.08.30 |
| [node.js/express/react] 새로운 endpoint로 새로운 화면 띄우기 (1) | 2024.08.29 |