본 게시글은 Stanford 대학교 Jure Leskovec 교수님의
Stanford CS224W: Machine Learning with Graphs(2021) 강의를 듣고
학습을 목적으로 재구성한 글입니다
스스로 정리한 내용이라 오류가 있을 수 있습니다
https://web.stanford.edu/class/cs224w/
CS224W | Home
Content What is this course about? Complex data can be represented as a graph of relationships between objects. Such networks are a fundamental tool for modeling social, technological, and biological systems. This course focuses on the computational, algor
web.stanford.edu
https://www.youtube.com/watch?v=6g9vtxUmfwM&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=15
전반부의 전체적인 GNN framework 부분은 끝이나고
이제 좀 더 나아가 이기종의 그래프들을 다뤄본다

우선 Heterogenous Graph가 무엇이냐?
우리가 지금까지는 그냥 node, link 1개의 type만 있는 그래프를 배웠는데
사실 node나 link의 type은 여러 개인 경우가 대부분이다
따라서 이렇게 Node나 Link의 타입이 여러개인 경우에 대해서
어떻게 다뤄야하는지를 살펴보자
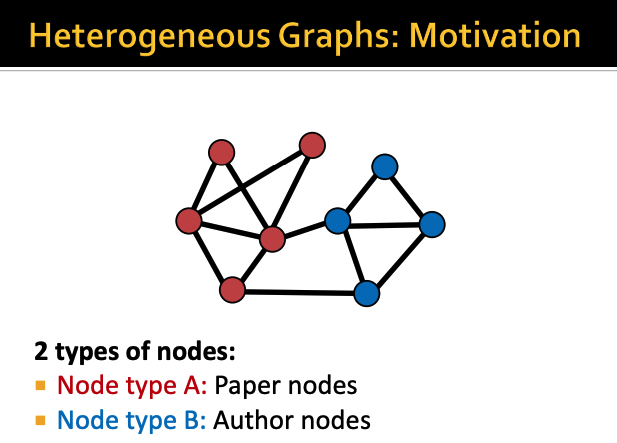
타입이 여러 개라는 것의 대표적인 예시는 위와 같다
node의 type이 2개인 예시인데
type A는 논문 데이터를 나타내는 노드이고
type B는 저자 데이터를 나타내는 노드이다
이 2가지 타입을 구분해서 graph를 다뤄야한다
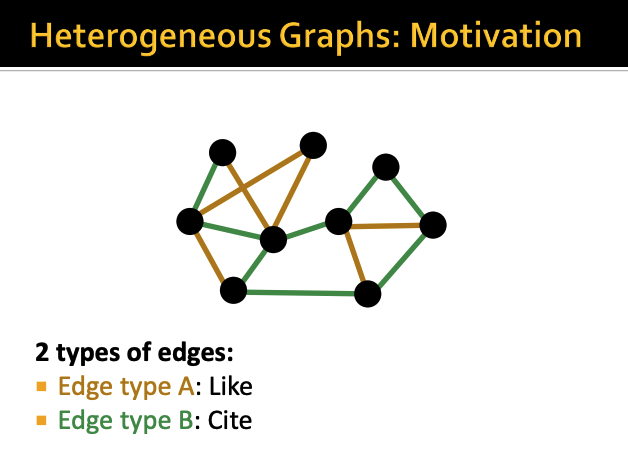
이건 link에 type이 2개인 경우이다
노란색 link는 좋아요를 누른 link이고
초록색 link는 인용을 한 link이다
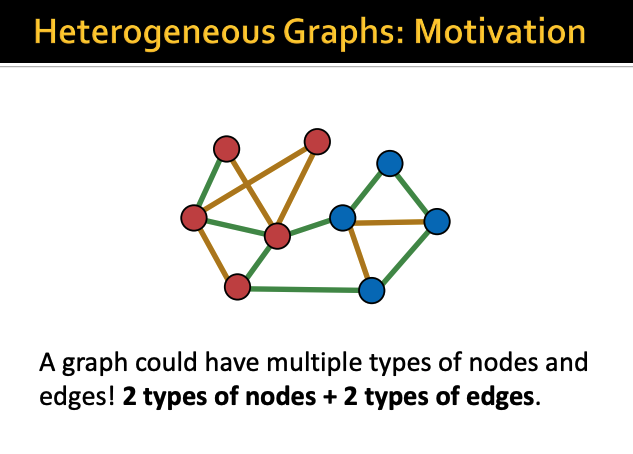
따라서 많은 그래프들은 이렇게
node도 2개 이상의 type을 갖고 있고
link도 2개 이상의 type을 갖고 있다
이런 그래프를 Heterogeneous Graphs라고 부른다

그럼 위 예시에서 type들 때문에 총 나올 수 있는
relation의 개수는 8개 된다

그렇다면 이 Heterogeneous Graph의
수학적인 정의를 한 번 살펴보자
노드의 집합은 V인데
노드 타입은

이렇게 표현할 수 있다
edge들도 마찬가지로

위와 같이 타입을 표현할 수 있어서
relation의 type은 결론적으로

이렇게 표현할 수 있다
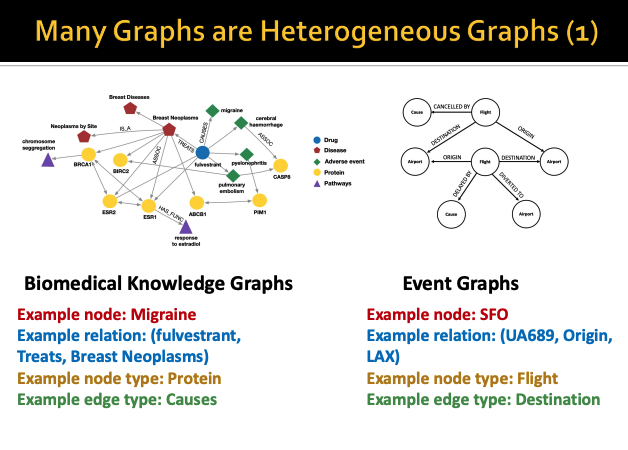
Heterogeneous Graph의 예시를 한 번 살펴보자
우리가 본 수업에서 이후에 Knowledge Graph에 대해서
자세하게 다루는데
각 도메인별로 정보들을 graph구조로 생성한 것을 Knowledge Graph라고 한다
따라서 이러한 knowledge graph도 heterogeneous graph이고
위 ppt에서 예시는 biomedical 분야에서의 Knowledge Graph이다
또한 오른쪽처럼 비행 스케줄을 그래프로 표현한 것도
heterogeneous graph라고 할 수 있다

하지만 우리는 이전에 각 그래프에서 노드와 엣지들의
feature들을 따로 다뤘었다
그럼 사실 이 type이라는 것을 feature로 표현하면 안되는 것일까?
one-hot encoding으로 위 ppt slide처럼
author node면 [1, 0]
paper node면 [0, 1]로 나타내면 안되는 것일까?

우선 type과 feature는 다른 개념이다
type이 다르면 당연히 feature도 달라진다
위 ppt slide의 예시에서
author type의 Node는 4-dim feature가 있고
paper type의 Node에는 5-dim feature가 있다고 한다

이러한 Heterogeneous Graph를 바탕으로
Relational GCN(RGCN)에 대해서 알아보자

우리가 앞에서 배운 GCN을
Heterogenous Graph에 확장한 개념이다
우리가 지금까지 배운 GCN 개념은
target node A가 있으면
A와 연결되어있는 다른 노드들에서
정보를 합쳐서 update하는 방식으로 진행했다

그렇다면 이 relation의 type이 여러개라면 어떻게 처리할 수 있을까?
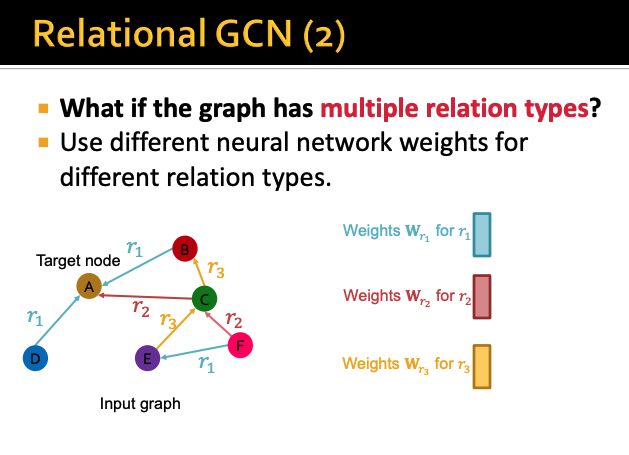
relation type이 여러개라면
각 type별 Relation마다 서로 다른 weight를 가져야한다

각 relation마다 서로 다른 weight를 곱한다음
aggregation function을 통해서 각각의 계산된 정보들을 합치면된다
GCN의 경우 aggregation function이 평균이기 때문에
모두 다 더한 다음 이웃의 개수로 나눠주는 방식으로
update를 진행할 것이다

그렇다면 이제 RGCN에서 message를 aggregation하는 방법을 알아보자
위 식에서 Cv,r은 노드 v로 들어오는 type r의 차수를 뜻한다
또한 Wr은 type r에 대한 가중치를 뜻한다
그다음 두번째 W0(l) 항은
노드 자기 자신에 대한 가중치를 더해주는 것이다
따라서 한마디로 요약하면
각 relation type별로 다른 가중치를 곱해준 것을 다 합한 것과
자기 자신 노드를 더한 것이
최종적으로 노드의 다음 레이어의 message가 되는 것이다

따라서 relation type r은 전체 layer의 개수 L개만큼
가중치 행렬을 갖고있다
그리고 각 가중치 행렬의 차수는
다음 layer의 dimension * 이번 layer의 dimension이 된다
이렇게 파라미터 개수가 많아지게되면
overfitting의 가능성이 증가하게된다
따라서 이러한 문제를 해결하기 위한 방법으로는
(1) block diagonal matrices를 사용하는 것
(2) basis/dictionary learning을 수행하는 것
2가지가 있는데 각각에 대해서 천천히 살펴보도록하자

우선 Block Diagonal Matrices부터 살펴보자
이 방법의 key insights는 weight matrix를 sparse하게 만들자는 것이다
여기서 matrix Wr은 대각행렬인데
대각원소들은 또 다른 하나의 submatrix가 된다
따라서 전체 행렬이 여러 개의 작은 sub행렬로 나뉘게 되고
서로 다른 block들이 독립적으로 존재한다
이렇게 되면 파라미터의 개수가 B(block의 개수)만큼 준다고 한다
결론적으로 연산량이 감소하고 overfitting을 방지할 수 있지만
블록간 연결이 없어서 표현력이 떨어진다는 단점이 있다고 한다

두 번째로는 Basis Learning을 한 번 살펴보자
이 방법의 key insight는 다른 relation들 간에 weight를 공유하자는 것이다
각 관계들의 가중치 행렬을 공통된 몇 개의 기저행렬을 사용해서
linear combination으로 결합시킨다
여기서 B는 기저행렬의 개수이고
위와 관련한 내용은 선형대수학을 공부하면 더 자세하게 공부할 수 있다
이렇게 각 가중치 행렬을 linear combination으로
여러 개의 행렬식으로 나타내면
이 가중치는 각 기저행렬에 곱해지는 importance weight a만 학습하면되고
이게 총 B개가 되는 것이다
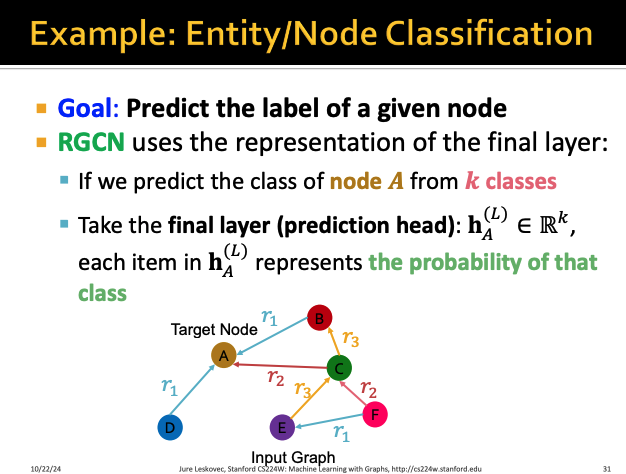
그렇다면 노드 라벨 예측은 어떻게 할 수 있을까?
RGCN에서는 node의 class가 k개 있다고 하면
최종 layer의 값인 h(L)이 해당 노드가 어떤 class일 확률을 나타내고
따라서 최종 레이어의 output을 보고 해당 노드의 label을 판단한다
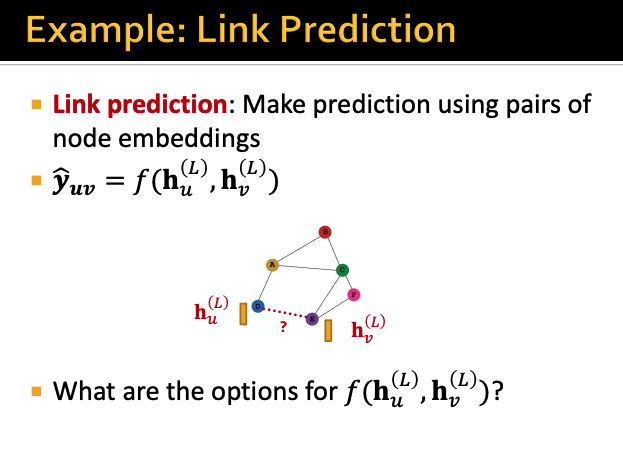
이번엔 link prediction에 대해서 알아보자
어떤 노드 u와 v 사이에 link가 있는지 없는지 판별하기 위해서는
각각 노드 u와 v의 최종 Layer의 output을 이용해야한다
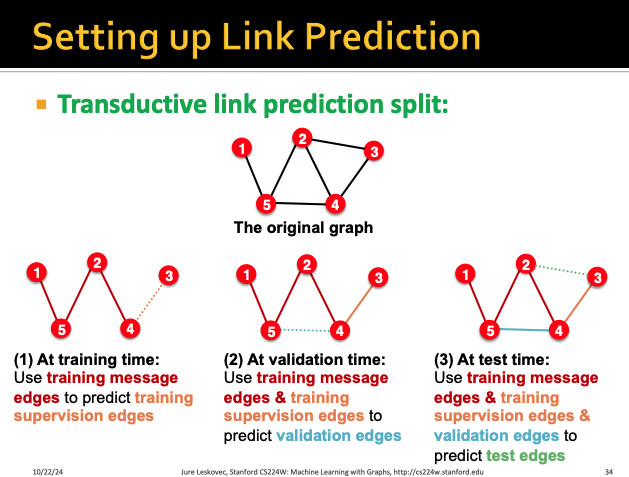
우리가 이전에 그냥 link prediction을 위해서
link들을 각각 split 해야한다고 배웠었다
그냥 1개의 type밖에 없을 때는 random으로 split해서
각각 training, supervision, validation, test로 구분하면 됐었는데
이제는 link마다 type이 달라지기 때문에 random으로 구분해서는 안된다
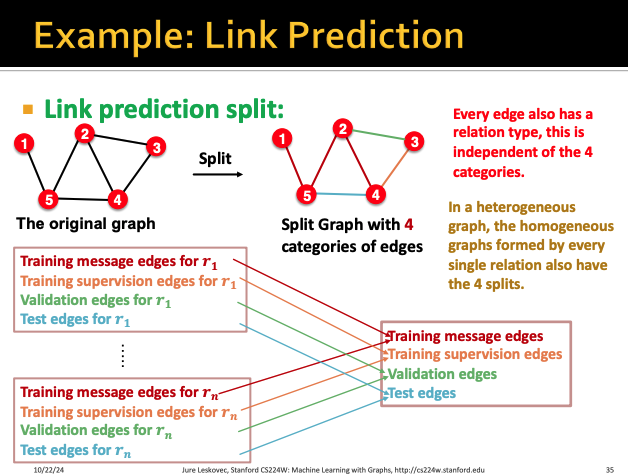
따라서 이렇게 type이 n개인 link에 대해서는
각 type별로 training, supervision, validation, test 4개씩 split을 한다
그렇게 되면 4개씩 n개의 set에 대해서 나눠질 것이고
이걸 다 merge를 해서 각 bucket의 내용들이 골고루 분포하도록 해준다

위 예시 그래프에서 E와 A의 링크 (E, r3, A)이
training supervison edge라고 해보자
그런 다음 이제 RGCN을 이용해서 (E, r3, A)의 score을 계산해보자
그렇다면 nodeE와 nodeA의 최종 output 값을
relation-specific score function인 fr에 넣어서 점수를 계산한다

그렇다면 학습은 어떻게 시킬까?
(E, r3, A)만 supervision용 edge이고 나머지들을
train으로 학습시켜야한다
이를 위해서 우리는 perturbing(동요시키는) negative edge들을 만들어보자
negative edge들은 이미 존재하는 link들이면 안되고
존재하지 않는 link들이어야한다
따라서 위 예시에서는 (E, r3, B), (E, r3, D)만이 negative edge가 될 것이고
(E, r3, C)와 같은 link는 이미 존재하기 때문에
negative edge가 될 수 없다
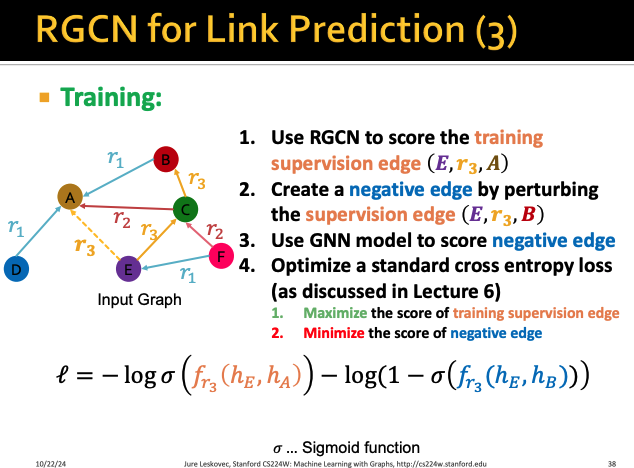
따라서 앞에서 만든 negative edge들은
training data도 supervision data도 아닌데
loss 함수를 corr entropy로 계산한다
이 과정에서 실제 training supervision들은 maximize가 되도록(첫번째항)
negative edge들은 minimize가 되도록 (두번째항) 최적화시킨다

그렇다면 이번에는 Evaluation을 살펴보자
위 동일한 예시에서 validation edge가 (E, r3, D)라고 가정해보자
그렇다면 우린 training message edges랑 training supervison edges를 이용해서
(E, r3, D)를 predict 해야한다
우선 우리가 앞에서 구해준 Negative edge들의 score를 우선 계산한다
그런 다음 negative edge들과 (E, r3, D)의 score를 계산한 다음
각각의 score들로 rank를 매긴다
그렇게 rank를 매긴 것에서

이건 우리가 evaluate하고 싶은 edge가 top-k 내에
들었는지 안들었는지를 평가하는 지표이다
포함되었으면 1, 포함되지 않았으면 0이 되고
당연히 1일수록 좋은 지표가 된다

이건 실제 edge의 순위로
순위가 높으면 Reciprocal Rank의 값 자체가 커지기 때문에
이것도 클수록 좋은 값이 된다