이 게시글은 서울대학교 데이터사이언스대학원 조요한 교수님의
거대언어모델과 대화형 인공지능 강의를
학습을 위해 재구성하였습니다

오늘 배울 내용은 alignment에서 advanced algorithm

위 부분에 대한 내용이다

우리가 지금까지 배운 RLHF와 DPO가 성공적인 알고리즘이었다
특히 DPO같은 경우는 preference learning algorithm의 대명사인데
단순하고 간단하면서도 효과가 좋기 때문이다
그런데 이런 DPO와 같은 방법들도 문제점이 있다
그래서 이를 해결하는 방법들이 나오기 시작했다

그중 첫 번째는 IPO이다

실제로 우리가 preference data를 이용해서 학습을 할 때
현실세계에서는 preference data가 충분히 많지가 않다
이 학습 데이터가 작고 finite하다는 문제가 있었다
기본적으로 RLHF와 DPO는 학습을 할 때
wining y가 losing y보다 선호될 확률을 기반으로 학습을 하는데
데이터가 작으면 observed probability가 1이 되어버린다
데이터 sparsity 때문인 것이다
그럼 이런 경우에는 기본적으로 데이터 자체가 특정한 샘플들에 대해서
over confidence를 갖게 되는 것이다
그래서 이러한 경우에 preference learning algorithm이
확률을 제대로 학습을 할 수가 없다
RLHF나 DPO같은 모델에는 regularization term(KL Divergence)가 들어가 있음에도 불구하고
제대로 작동하지 않는다고 한다
이렇게 데이터가 sparse할 때는 모델이 너무 overconfidence하지 않고 SFT에 가깝게 하고싶은데
이게 잘 안된다는 것이다

우리가 지난시간에 봤던 저 식이 DPO의 Loss function이다
저 둘의 margin을 최대화하도록 하는 알고리즘이다
reference policy는 초기의 SFT 모델에 이미 보정이 되어있는 값이라서 상수이다
결국 DPO는 앞의 값을 최대한 올리도록 학습하는 것이다
그렇기 위해서는 분자를 분모보다 높아지도록 계속해서 학습을 시켜야 한다
이 과정에서 x, y , w, l이 데이터에 많이 등장하지 않으면
특정한 인스턴스에 대해서 yw를 1로, yl를 0으로 보내려고해서 이게 문제가 된다
이런 sample이 preference data에 많이 등장하지 않기 때문에
이 경우에 어떤 특정한 텍스트들의 확률을 극단적으로 올리거나 극단적으로 낮추려는 경향이 생겨버림
위 loss function에서 베타는 KL Divergence의 weight인데
이걸 높이면 SFT의 모델에서 크게 변하지 않도록 regularize를 시켜준다
그런데 데이터가 sparse하면 이 beta effect가 거의 무시가 된다고 한다
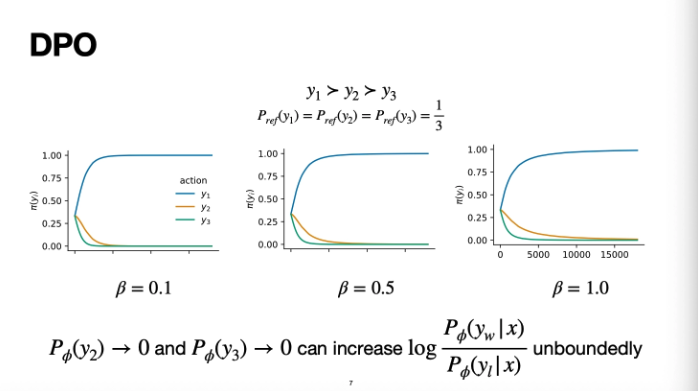
y1, y2, y3라는 text가 있고 y3이 꼴찌인 toy example이 있다고 해보자
모델이 y1, y2, y3를 생성할 확률이 3분의 1인 uniform distribution이다
이게 학습이 진행됨에 따라서 어떻게 진행되는지 확인해보자
가장 선호되는 response의 확률을 1로 밀어넣어버리고 나머지를 0으로 맞춰버린다
베타값을 올리면 조금 나아질까?
그렇지 않다
변하는 속도에는 영향을 미치긴 하는데 결국 학습을 계속 시키다보면 1과 0으로 극단적으로 나누어진다
우리의 preference data가 굉장히 작을 때 발생하는 문제이다

그래서 이 문제를 해결하기위해 등장한 방식이 IPO이다
위는 IPO의 loss function인데
SFT 모델에 대해서 yw의 확률을 y1의 확률에 대해서 나눈 것 분에
학습시킨 모델에 대해서 yw의 확률을 나눈 것분에
베타분의 1을 뺀 것의 제곱이다
이 loss를 최소화하려면 0에 가까워야한다
왼쪽과 오른쪽이 최대한 비슷해지도록 학습해야하는 것이다
그 말은 베타를 이용한 regularization이 빡세게 들어가길 기대하는 것이다
베타가 커지면 오른쪽이 0에 가까워지고 그럼 왼쪽도 0에 가까워져야한다
그렇게 되려면 학습시키는 모델의 분포가 SFT 모델의 분포와 최대한 가까워지도록 학습을 시켜야한다
그럼 반대로 베타가 작다면?
오른쪽 term이 무한대에 가까워지고
그렇게 되면 왼쪽도 무한대가 되어야하기 때문에
분모는 고정이니 분자가 최대한 가까워지도록 학습시켜야한다
그래서 이 경우에 low regularizatin effect를 얻을 수 있도록 학습이 되는 것이다
결론적으로 IPO는 현실에 preference data라는게 그렇게 많지 않기 때문에
모델이 over confidence를 가지는 경우가 있었다
그래서 모델이 너무 극단적인 확률을 갖지않게 하기 위해서 regularization을 넣고 싶은 것인데
문제는 regularization effect가 제대로 안들어간다는 것이다
그래서 IPO를 도입을 해서 베타값에 따라서 원하는 정도의 regularization effect를 넣을 수 있도록 하고싶은 것이다

evaluation을 살펴보자
앞에서 봤던 동일한 예제이다
DPO를 할 경우에는 가장 선호되는 확률의 답변을 무조건 1로 몰아넣고
나머지를 다 그냥 0으로 몰아넣어버렸었다
베타값이 커져도 이런 현상이 고쳐지지않는다는게 DPO의 문제였는데
반면에 IPO를 썼을 때 베타값이 작을 때는 여전히 y1의 확률이 1로는 올라간다
하지만 베타값을 높이면 높일수록 reference policy가 3분의 1에 가까워지는 것을 볼 수 있다
regularization 효과가 생기게 되는 것이다

두번째 케이스를 살펴보자
지금 y1이 y2보다 선호되는 preference instance가 하나 있고
y2가 y1보다 선호되는 instance가 하나 있다고 해보자
IPO같은 경우는 베타값이 작으면 DPO와 비슷한 양상이 나타나지만
베타값이 커질수록 regularization 양상이 나타나면서 reference policy인 3분의 1정도로 유지를 시키는 것을 확인할 수 있다
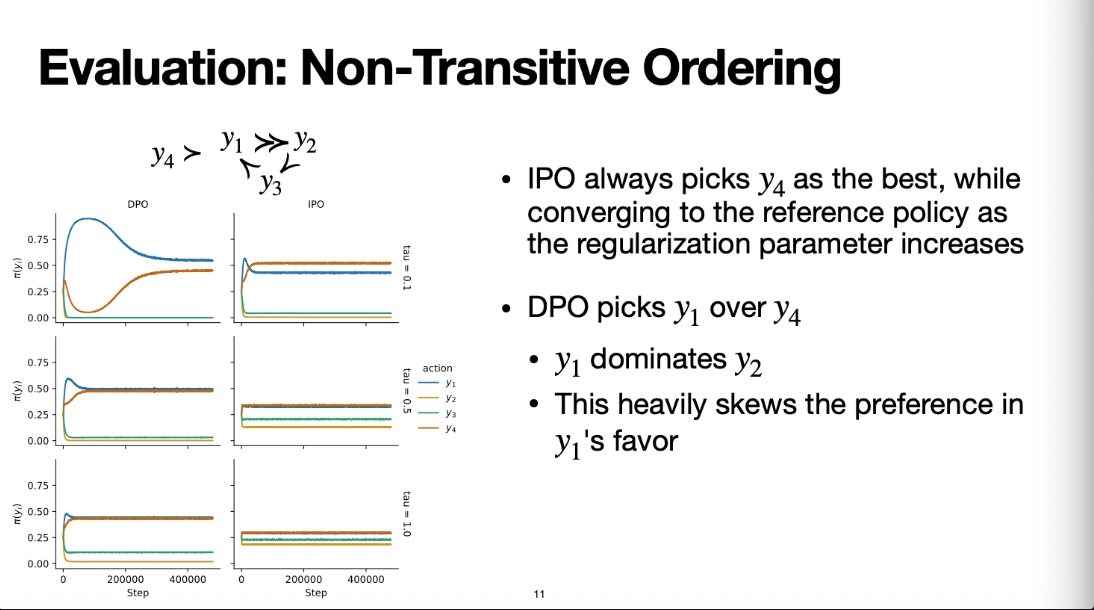
y4는 y1, y2, y3에 비해서 확연하게 선호가 되는 답변이고
나머지는 서로 약간의 상성관계가 있는 경우라고 해보자
이런 non transitive ordering이 있을 때는 학습이 어떻게 되는지 살펴보자
직관적으로 봤을 때는 IPO는 y4의 확률을 가장 높아지도록 학습될 것이다
그리고 실제로도 그렇게 학습이 된다
y2는 y1보다 극단적으로 낮은 선호를 갖고있기 때문에 y2를 가장 낮게 학습한다
그런데 베타값이 증가함에 따라서 그 차이가 점점 줄면서
4분의 1 uniform distribution으로 학습이 된다
그런데 DPO는 y1의 확률을 가장 높아지도록 학습이 된다
이 부분이 직관적이지가 않은데
모델은 y2를 낮추고 y1을 높이는 극단적이니 방식으로 학습을 진행한다

정리해보자
preference learning algorithm들이 reference policy를 무시하는 경향이 생겼다
reward가 unbound가 되어서 극단적으로 wining의 확률을 높이고
losing을 낮추는 방식이 되는 것이다
deterministic한 확률이 되어버릴 때 알고리즘은 wining을 1로 losing을 0으로 보내도록 학습한다
그래서 그걸 개선한게 IPO이다


RLHF와 DPO 2개의 objective를 한 번 잘 살펴보자
어떤 특정한 y가 나왔을 때 그 outcome y를 어떤 가치로 볼 수 있지않을까?
결국에 우리의 goal은 이 language model이 생성하는 outcome들의 기대가치를
최대한 생성하도록 하는 것이다
여기서 가치라는 말은 reinforcement learning에서 나오는 가치와는 전혀 상관이 없다
진짜 그 가치있다 할 때의 추상적 의미의 가치이다
결국 RLHF와 DPO는 어떤 outcome의 가치는 이런식으로 될 것이라고 정의를 한 것이고
우리는 그 기댓값을 최대화 시키도록 학습을 시키고 싶은 것인데
이렇게 했을 때 사람이 느끼는 가치와 얼마나 일치를 하는지 학습을 시키고 싶은 것이다
모델이 뱉는 가치랑 사람이 느끼는 가치는 다르기 때문이다

그래서 모델이 뱉는 outcome을 사람이 느끼는 가치와 비슷하도록
시스템적으로 만들면 좋지 않을까라는 것이다
그렇다면 사람이 모델에 대해서 어떤 가치 분포를 갖고 있는지를 알아야한다
그래서 심리학에서 아주 유명하다는 prospect theory를 가져온다고 한다
u(z)가 어떤 확률 시스템에 대해서 사람이 느끼는 효용성 값이다
이 이론에서는 gambling machine을 예시로 들었는데
사실 언어모델도 확률 시스템이다
텍스트가 생성이 되면서 각각 확률에 대해 나타나는 outcome이다
그래서 어떤 확률 시스템에서 사람이 느끼는 효용성을
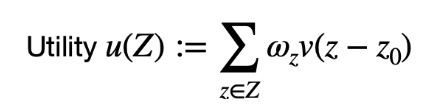
위와 같이 정의한다고 한다
이 z에 대해서 이렇게 계산을 할 수가 있다고 가정해보자
그렇다면 z가 무엇이냐
z는 이 system에서 나올 수 있는 outcome이다
여기서는 예시가 gambling인데 한 번 돌렸을 때 만원을 땄다, 오천원을 땄따 이런 것들이 각각의 outcome이 되는 것이다
그럼 사람이 gambling machine을 돌렸을 때 만원을 땄으면
그 사람이 이 만원의 가치를 정확히 만원이라고 판단하고
오천원을 잃었으면 그 가치를 -5000원이라고 판단하나?
그렇지가 않다
사람에게는 항상 baseline이란 것이 존재한다
사람은 내가 딴 이득이 올라가면 처음엔 그에 비례해서 만족도가 함께 올라가지만
젖멈점점 커지면 무한히 증가하는게 아니다
그리고 돈을 잃을때에도 계속해서 가치가 떨어지다가 어느 순간 무뎌지는 구간이 온다
결국 사람의 가치 쳬계는 s shape를 갖는다
이익과 손해에 대해서 무한히 정비례 발산하는 것이 아니라는 것이다
이 앞에 나온 것들은 결국 기댓값이라는 것을 계산하고 싶은 것인데
오메가 z가 z가 나올 확률이기때문에
이 확률에 summation을 해서 기댓값을 구하고 싶은 것이다
저 오메가z는 수학적으로 계산해서 z가 나올 확률은 아니라고한다
왜냐하면 사람은 왜곡된 확률을 갖고잇기 때문이다

그래서 이러한 가치 체계를 언어모델에 한 번 넣어보자는 것이다
이거러 Human-Aware Loss(HALO)로 정의한다

위 값이 가치의 기댓값이다
왼쪽의 오메가 식과 최대한 맞춰주려고 한 것이다
그래서 저 오메가를 곱한 다음에 summation하는 부분을 기댓값으로 대체했고
뭐 이런식으로 만들어주면 prospect theory에서의 인간 가치체계랑
비슷한 형태로 만들 수 있을 것이라고 하는 것이다
각각의 term을 한 번 살펴보자
왼쪽의 r(x, y)는 실제로 x, y에 대한 outcome이다
모델이 주어진 x에 대해서 y를 생성했을 때의 outcome이다
그런데 사람이 느끼는 가치는 다른 sample들을 보고 상대적으로 결정되는 경향이 있다
그래서 지금 여기서 baseline을 이루는 기대 outcome은 r(x', y')이 된다
그 다음에 이 차이에다가 value shape를 고려한다
정비례해서 무한히 발산하는게 아닌 curve 형태이다
앞에서는 이게 s shape이라고 가정을 했는데
여기에서는 음수 부분을 좀 relax 시켜서 그 부분에 대해서는 제약을 두지 않고
0보다 클 때에 concave형태를 갖는다고만 정의한다
원래는 음수일때도 이런 모양을 가져야하는데 일단은 그건 무시하고
양수부분에서 concave하다고 가정한다
그래서 이런 조건들을 다 만족하는 알고리즘들을 우리가 다 HALO의 일종으로 보겠다는 것이다
그럼 DPO loss는 HALO인가?
그렇다
그래서 이 경우에는 expectation의 Q가 x, y, l을 그냥 deterministic하게 생성하는
Q라고 볼 수 있는 것이다
그리고 value shape을 결정하는 부분이 로그 시그마가 된다
PPO도 HALO의 일종으로 볼 수 있다고 한다

그런데 DPO와 RLHF 얘네들은 사람이 느끼는 가치체계와는 잘 align이 되지 않는다고 한다
그래서 DPO RLHF보다 더 align이 잘되는 loss function을 디자인을 할 것이고
이것을 Kahneman-Tversky Optimization(KTO)라고 부른다
DPO와 PPO에서 문제가 될 수 있는 shape의 부분이 있는데
사람은 마이너스일때 계속 떨어지다가 무뎌지는 구간이 있는데
DPO는 마이너스로 계속해서 떨어진다
그래서 이런 부분이 miss align이 생기는 것이다

KTO의 특징은 무한대로 떨어지는 것이 아니고 less sensitive하게 바뀐다는 것이다
loss에 대한 sensitivity와 개인에 대한 sensitivity가 다른데
똑같이 만원이라 하더라도 사람이 만원을 땄을 때랑 만원을 잃었을 때 magnitidue가 방향만 바뀐 형태가 아니라는 것이다
결국 이게 s-shape이라고 하더라도 손실의 기울기와 증가의 기울기는 다를 수가 있다
기본적으로 KTO는 binary reward를 가정한다
이게 바로 preference data와의 차이점이다
preference data의 가정을 relax 시켜서 어떤 outcome은 desirable, undesirable로 할 수 있다고 가정한다

y가 desirable한 경우와 그렇지 않은 경우를 나눠서 생각해보자
y가 desirable한 경우는 아래와 같이 생겼는데

어떤 시그모이드 안에 묶여있다
s-shape로 만들고싶기 때문에 시그모이드로 묶어준것이다
그리고 그 안에 뭐 expectation이 있고 또 그 안에는 KL Divergence가 있고.. 그렇다
기본적으로 어떻게 outcome을 정의를 할 것인가
ref 모델 대비 현재 학습 중인 모델이 훨씬 더 높은 확률로 할 수 있으면
그건 기본적으로 좋은 outcome으로 보겠다는 것이다
그런데 우리는 baseline이 있어야 한다
현재 학습 중인 모델이 여러 가지 질의들에 대해서 reference 모델보다
distribution이 얼마나 멀어지는지를 baseline으로 삼겠다는 것이다
현재 학습 중인 모델이 reference model보다 멀어져있는 정도 대비
outcome이 더 크면 우리는 그걸 이득으로 보겠다는 뜻이다
가장 왼쪽에 있는 람다 D는 앞에서 말했던것처럼
얼마나 desirable한 y의 sensitivity를 줄일 것인지에 대한 정도이다
그래서 이 식을 다시 쓰면
y를 기댓값으로 빼고 로그를 상대 확률로 나타낼 수가 있다

그럼 y가 undesirable 한건?
저 안쪽 term에 마이너스만 붙여서 y의 확률을 낮추도록 학습을 한다
결국에는 비슷한 방식으로 r이라는 것은 마이너스 베타의 log확률이다
그리고 desirable한 것과 또 한 가지 차이점은
위에서 쓰이는 람다u는 desirable과는 다르다
undesirable에서는 y에 대해서 조금 더 다른 sensitivity를 가진다고 생각하는 것이다

다시 한 번 정리해보자
이 HALO라고 하는 일반화된 식에서 KTO가 어떤식으로 정의를 내렸냐하면
y가 desirable한 경우에 대해서는 이렇게

여기서 람다D는 desirable한 경우의 sensitivity이다
그리고 undesirable한 경우는 학습의 방향을 바꾼다

Q라는 것은 어떤 확률분포를 나타내는지인데
주어진 x, y에 대해서 x', y'를 뽑아내서 estimation을 하는데
x'은 뒤에서 나온다고 가정하고 y'은 현재 학습 중인 모델에게 x'를 줬을 때 나오는 답변의 확률분포이다
그리고 실제로 실험을 돌리려면 람다D와 람다U가 하이퍼파라미터라서 정의를 해줘야하는데
이거에 대해서 가이드라인도 제시해준다
실험을 많이 해봤더니 nd는 desirable한 instance의 개수이고
nu는 undesirable한 instance의 개수라고 한다

위 비율이 1에 가까운 경우 대체로 좋은 성능이 나온다고 한다
그래서 만약에 desirable한 sample이 undesirable sample보다 적게 들어있으면
람다D의 값을 람다U의 값보다 높여줘서
desirable에 대한 sensitivity를 높여주면 훨씬 더 학즙이 잘된다

KTO에서 실험을 위해 사용한 데이터를 살펴보자
기존에 했던 여러 가지 데이터셋들을 가져와서 활용했는데
기존의 많은 데이터셋들은 preference set의 형태를 갖고있다
그런데 KTO는 binary를 가정하고 있어서
이 preference dataset을 binary로 바꾼다
굉장히 단ㄷ순하게 yw면 desirable, yl면 undesirable로 한다
이렇게 되면 결국 training instance의 개수는 2배가 되는 효과도 있다
대신에 preference data가 갖고있는 풍성한 정보는 잊어버린다

첫 번째 task를 수행했다
모델이 human value에 얼만큼 align이 잘되는지를 봤다
학습하려는 모델이 생성한 답변과 실제로 이 학습데이터에 있는 사람이 만들어놓은 모범답안을
GPT4에게 보여주고 둘 중에 뭐가 더 좋은 답변인지를 물어보는 식으로 평가했다
사실 이 task자체가 굉장히 이기기가 어려운 태스크이다
사람이 만들어놓은 모범답안을 이긴다는게 힘들기 때문이다
그래서 이 winrate는 대부분 마이너스인데 이걸 감안하고 봐야한다
그래도 이 winrate가 얼마나 더 위쪽에 있는지를 보면 된다
주황색은 Pythia라는 모델이고 파란색은 Llama이다
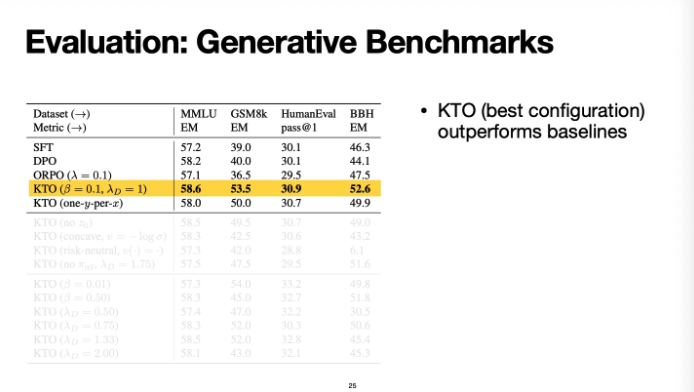
이렇게 했을 때 여기서 주장하는 것은 KTO가 DPO보다 낫다는 것을 주장하는데
몇몇 모델에 대해서 KTO가 조금 더 유의미한 성능을 보였다고 한다
그리고 또 저자들이 주장하는 것 중 하나는
DPO는 preference data라는 rich한 데이터를 씀에도 불구하고
binary를 사용하는 KTO가 특정 부분에서 더 좋은 성능을 보이고있음을 강조한다
또한 Llama같이 큰 모델들에서는
KTO가 SFT를 하지 않아도 꽤 compatative하다는 것을 강조한다
기존의 preference learning algorithm들은 SFT를 시키지 않으면 성능이 안좋았는데
KTO같은 경우는 SFT를 먼저 시키지 않아도 꽤 좋은 성능이 나온다

SFT의 중요성에 대해서 보여주는 그림이다
유독 튀는게 DPO만 학습을 시켰을 때 굉장히 길이가 길어진다
이건 학습이 제대로 잘 안되었다는 것인데
이 모델을 SFT를 시키지 않고 DPO만 시키면 답변 자체가 rambling하거나 hallucination을 해서
이상한 답변들이 생성된다
그래서 DPO를 할 때 SFT를 먼저 시킨 다음 DPO를 해준다
그런데 KTO같은 경우는 SFT를 시키지 않아도 좋았다고 한다

desirable 데이터와 undesirable 데이터의 balance가 맞지 않을 때 학습이 어떻게 되는지 살펴보자
x축은 positive 대비 negative의 개수이다
빨간색은 KTo가 DPO보다 잘한 비율이다
0에 가까울수록 negative sample의 개수가 훨씬 많은 것이고
1이 되면 1:1이 된다
1:1을 했을 때는 KTO가 DPO보다 훨씬 잘했고
점점 unbalance하더라도 DPO보다는 좋았다는 것이다
여러 가지 generative task에 대한 benchmark이다
baseline model들 대비 KTO가 얼마나 잘했는지를 보여주는 부분이다

preference data라는게 하나의 x에 대해서 여러 개의 학습 instance들이 존재한다
이 하나의 x에 대해서 여러 y들 중에서 하나만 뽑아
그걸 x에 대한 유일한 학습데이터로 구성한다
그럼 학습데이터가 많이 줄어들지만, 그래도 KTO가 상당히 안정적이라고 한다
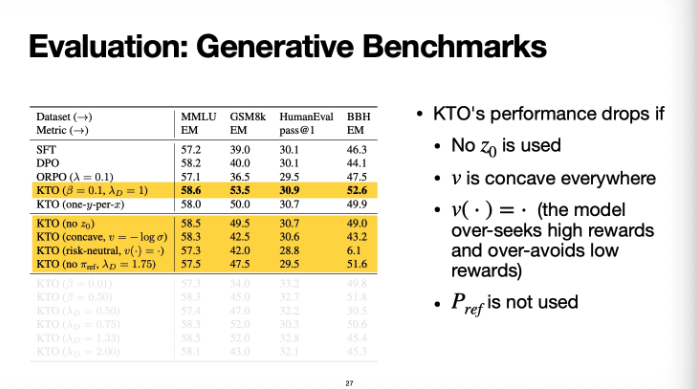
그 다음은 ablation study이다
첫 번째는 z0을 안썼을 때이고
v가 s shape이 아니고 concave 일 때 이다
세 번째는 value mapping function이 그냥 identity일때(무한히 증가하거나 감소)이고
마지막은 Pref을 아예 쓰지 않는 것이다

이건 베타값과 여러 람다D값을 바꿔서 실험해본 것이다

요약을 해보자
많은 preference method들이 가정하는 모델의 outcome에 대한 가치가
사람이 느끼는 가치와 miss align 된 부분이 있었다
그래서 KTO는 사람이 느끼는 가치와 align된 가치를 도입한다
이를 심리학의 prospect theory에서 가져온다
그리고 이걸 loss function에 넣는다
KTO의 강점은 performance가 좋다는 점이다
binary reward를 쓰 ㅁ에도 불구하고
데이터가 imbalance하더라도 SFT를 쓰지 않아도
안정적인 성능을 보인다
그러나 한계점으로는
얘가 결국에는 1 또는 -1 이라는 단순한 binary signal을 쓰기 떄문에
preference data는 풍성한 시그널을 쓸 수가 없다
또한, 하이퍼파라미터 람다D, 람다U가 도입이 되어서 좋은 하이퍼파라미터를 서치하는 과정이
다 computation이기 때문에 최적의 operation을 찾는 것이 힘들다
마지막으로 이 KTO가 모든 모델에서 좋은 성능이 나왔냐?
그렇지 않다는 점이다
모델에 따라서 제일 좋은 configuration이 다르기 때문에
universal한 솔루션이 없다는 한계점이 있다

오늘 강의 내용을 정리해보자
기존의 preference learning algorithm들이 갖고 있던 inductive bias들이
사람이랑 잘 align이 되지 않는 문제들이 있어서 그걸 해결하고자 나온 방법들이다
첫번째 IPO는 regularization이 작동하지 않는 문제를 해결하고자 나온 방법이고
두번째 KTO는 인간 심리학을 융합시켜서 개선을 하고자 나온 방법이었다
'강의 > NLP' 카테고리의 다른 글
| [NLP] Interpretability - Mechanistic Interpretability (1) | 2026.04.26 |
|---|---|
| [NLP] Alignment - Learning from AI Feedback (1) | 2026.04.26 |
| [NLP] Alignment - Direct Preference Optimization (1) | 2026.04.12 |
| [NLP] Alignment - Reinforcement Learning from Human Feedback (InstructGPT) (1) | 2026.04.11 |
| [NLP] Supervised Fine-tuning (Instruction Tuning and Reasoning) (1) | 2026.04.11 |