이 게시글은 서울대학교 데이터사이언스대학원 조요한 교수님의
거대언어모델과 대화형 인공지능 강의를
학습을 위해 재구성하였습니다


현재 우리 수업에서 와 있는 부분이다
alignment와 관련되어 있는 알고리즘은 이제 끝이났고
이제부터는 학습이 된 모델을 어떻게 해석할수있는지를 다루는 interpretability이다

Motivation이다
언어모델에는 black box라고 하는 특징이 있는데
언어모델이 잘 작동을 하는건 알고있는데 왜 작동을 하고있는건지
그 내부의 로직을 알기가 굉장히 어렵다
그래서 나온 분야가 mechanistic interpretability이다
언어모델을 reverse engineering하는 과학의 영역이다
언어모델에게 task를 주었을 때 이 언어모델이 task를 풀어나가기 위해서
내부적으로 벡터를 만들고하는 그 neural pathways가 있을 텐데 그걸 분석하는 연구의 영역이다
hidden state가 계속해서 만들어지고 결국 이 hidden state가 단어를 생성하는건데
이 hidden representation을 어떻게 해석하는지이다
이런 task를 푸는 과정을 사람이 이해할 수 있는 메커니즘으로 이해해보자는 것이다
그래서 goal은 black box라고 여겨지던 언어모델을
투명하고 trustworthy하조 제어가 가능한 툴로 만들고 싶다는 것이다

트랜스포머 디코더의 아키텍처에 대해서 조금 깊게 들어가보자
각각의 단어가 들어오면 다음 단어를 생성하고
그 다음 단어를 넣으면 또 다음 단어를 생성하는
그렇게 단어를 생성해나가는 디코더 모델이 있다
특정한 단어가 들어오면 크게 2가지 모듈이 작동하는데
문맥에 등장하는 다른 단어들의 정보를 합치는 역할을 하는
self attention과
feedforward network에서 한 번 업데이트가 되어서
이 아웃풋을 바탕으로 다음 단어를 예측하게 된다
각각의 Module의 output 부분이 residual connection으로 연결되어있다
즉 attention module로 들어가는 input 자체가 attention output으로 더해지는데
이는 feedforward network에서도 마찬가지이다
이렇게 input과 output을 direct하게 연결하는 connection이 residual connection이다
그런데 이 트랜스포머 디코더의 아키텍처를 mechanistic interpretability 분야에서는 조금 다른 관점으로 본다

이걸 reisudal stream을 중심으로 본다
이 hidden state가 계속해서 업데이트가 되고 최종적으로 다음 단어가 업데이트된다
결국 이 각각을 residual stream이라고 부른다
hidden state가 업데이트가 되어 가는데 이 업데이트를 시키는 주체가
attention과 feedforward module이다
이런걸 residual stream-centered viewpoint라고 부른다

그렇다면 보통 이 RS state는 보통 다음 단어의 state를 담고있다
이 attention module은 문맥정보를 더해주는 식으로 업데이트를 하고
feedforward는 hidden state 안에 있는 정보를
조금 더 풍성하게 만드는 식으로 업데이트한다

그렇다면 크게 2가지에 대해서 살펴보자
첫 번째는 hidden state이다
이 hidden state에는 도대체 어떤 정보들이 들어있는지?
그리고 그걸 우리가 어떻게 해석할 수 있는지?
그리고 두번째는 FFNs와 ATTNs이다
hidden state들을 업데이트시키는 주체들이다


hidden state의 해석 기법을 보기 전에 몇 가지 개념을 정리해보자
linear representation hypothesis라는 개념이 있다
어떤 단어가 있고 그 단어의 dense vector를 구하고 싶은게 Word2vec이었다
그래서 그 단어 주위에 어떤 단어가 나타날까를 중심으로 학습을 수행했다
아무튼 네트워크가 이 단어의 vector representation을 만들었다
그 벡터 안에는 이 단어의 identity를 결정하는 중요한 정보들이 들어가게 된다
그래서 품사정보라던지 여성형인지 남성형인지에 대한 정보들이 들어가게 된다
각각이 하나의 direction으로 표현되며
하나의 dimenstion이 하나의 feature를 나타내는 식으로 학습하게된다
단어의 feature들이 방향을 이루고 있다
그렇기 때문에 단어의 의미라는 것은 그 단어의 의미를 구성하는 조금 더 low level의
feature들의 linear combination으로 표현이 가능하다
그래서 word2vec으로 학습시킨 벡터들로는 linear 연산이 가능해지는 것이다
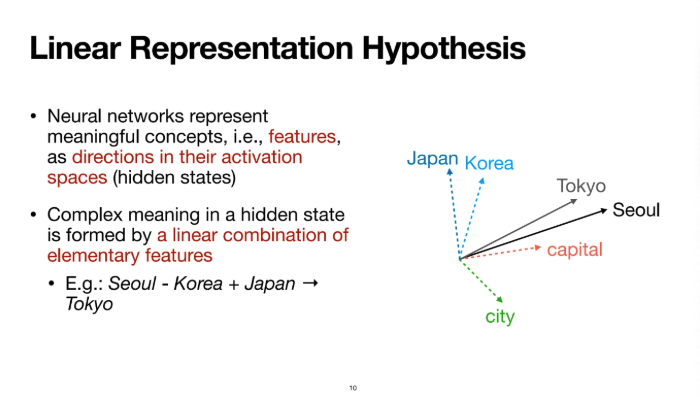
위 내용을 좀 더 general하게 살펴보자
neural network(transformer)들이 이 세상의 해석 가능한 feature들을
그 activation spaces 안에서 방향으로 갖고있다는 것이 linear representation hypothesis이다
Llama를 예시로 들어보자
1000 dimension의 hidden state를 갖고있다고 해보자
이걸 단순하게 위 ppt처럼 2D로 표현을 해본다고 하면 저렇게 나타낼 수 있을 것이다
Korea를 나타내는 방향도 있고 capital을 나타내는 디렉션도 있고..
아무튼 굉장히 많은 feature를 나타내는 direction들이 그 공간에 존재한다는 것이다
조금 더 elementary한 feature들의 sum으로 조금 더 복잡한 feature들을 표현할 수가 있다
의미가 조금 더 작은 feature들의 linear combination으로 쪼개질 수가 있다
각각의 feature는 또 combination 안에서 방향성을 갖고있다
서울에서 Korea를 빼고 거기에다가 japan을 더하면
그 결과값이 도쿄를 나타내는 식으로 공간이 구성되는 것이다

hidden state의 어떤 dimension이 정말 꼭 한 가지의 feature와 정확하게 align이 되어있다
그럼 이 basis를 priviledge basis라고 부른다
오른쪽은 hidden state를 2차원으로 축소시킨 것이고
1번과 2번 dimension이 있는데
1번 dimension이 어떤 feature와 매핑이 되어있고 2번 dimension이 어떤 feature와 매핑이 되어있다면
이건 priviledge basis이다
그래고 1개의 feature와만 연결이 되어있으니까 이건 monosemanticity하다고 한다
그런데 transformer의 hidden state들은 non-priviledge basis이다
하나의 dimension이 여러 개의 feature에 관여를 하는 형태로 학습이 된다
이런 케이스를 polysemanticity라고 한다
하나의 dimension이 여러 개의 feature를 의미할 수 있다
그럼 이 세상에 몇 가지 feature가 있고 우리가 학습시킨 모델이 몇 가지 feature를 표현할 수 있을까?
서로 orthogonal한 feature들이 많잖아
hidden state의 공간이 mono든 poly든 정말로 이 orthogonal한 feature들을
이 space 안에서 orthogonal하게 표현하고 싶다고하면 그게 이 space의 bound가 될 것이다
그런데 실제로 학습된 언어모델을 보면 당연히 1000개보다 훨씬 더 많은
feature들을 학습하고 있다
그런데도 이게 가능해지는 이유가 무엇일까

이게 가능해지는 이유는 바로 이 superposition이라는 개념 때문이다
정확하게는 orthogonal이 아니고 almost orthgonal하게 표현하는 것이다
그래서 hidden state의 dimension보다 훨씬 더 많은 것을 표현할 수 있는 것이다
이게 2D hidden state라고 한다면 3개까지도 almost-orthogonal 하게 표현할 수 있다

그럼 residual stream에 있는 feature들은 어떤 의미를 갖고 있는지 살펴보자
중간에 만들어지는 hidden state가 있다
이 hidden state 안에 어떠어떠한 feature들이 표현이 가능한지를 탐색해보고 싶은 것이다
그래서 이 hidden state에 해당되는 모든 state들의 dictionary를 만들어보게 되었다
그리고 이건 hidden state의 dimension 개수보다는 많을 것이다
어떠한 feature가 어떤 basis들과 관련이 되어있고 어떠한 정도로 관련이 있는지까지도 분석을 하고싶었던 것이다
그래서 이 sparse autoencoder라는 것을 학습시킨다
이 hidden state가 x로 autoencoder의 input으로 들어간다
그리고 얘가 Wenc를 거쳐서 중간 벡터를 만들어내는데 이게 우리가 구하고싶은
feature dictionary이다 이건 벡터 형태이다
이걸 ReLU에 넣어서 0보다 작은 값들은 다 0으로 만들어버리고
최종 output인 x hat을 구하게 된다
그럼 autoencoder는 기본적으로 xhat이 x를 거의 복구해낼수있다라는 목적으로
학습이 되는 네트워크인 것이다
input이 들어가고 그 input과 관련된 몇몇의 정보만 살아남아서
그 중요하다고 생각되는 몇몇의 정보만 가지고
x를 원복가능하도록 하는게 autoencoder이고
보통 압축에 많이 쓰이는 방식이다
loss function에서 input으로 들어가는 x와 output의 xhat이 최대한 비슷해지도록 학습한다
중간에서 살아남은 정보의 개수를 최소화하기 위해서
f에 L1 norm을 걸었다
가능하면 f에서 덜 중요한 애들은 0으로 만들고
더 중요한 애들은 minimum이 되도록 학습을 수행하는 것이다
그래서 이 f가 최대한 sparse되었으면 좋겠는 것이다
그럼 여기서 우리가 학습을 했을 때 왜 interpretabble한 것을 할 수가 있었을까?
굉장히 많은 text input을 다 저기다 집어넣으면 각가의 단어별로 hidden state가 나올텐데
이 sparse autoencoder를 학습시키기 위해서는 많은 단어들을 쓰지만 레이블링을 할 필요가 없다
각각의 token 자리에서 hidden state가 계산이 되고
그 hidden state를 sparse autoencoder를 태웠을 때 x와 최대한 비슷해지도록 학습을 시킨다
그렇다면 왜 이렇게 학습을 시키면 우리가 기대하는 feature들을 구할 수가 있을까?
이 task를 비유로 들자면 서울이라는 의미가 있다고 해보자
그런데 다른 사람들은 우리가 서울을 생각하고있다는 것을 모르니까
이를 맞추게 하기 위해서 2개의 정보만 준다
그렇다면 어떤 2개의 정보를 주어야 다른 사람들이 서울을 맞출 수 있을까?
이 모델은 이걸 수행하는 것이다
아주 적은 수의 정보만 가지고 이 의미를 맞추려고 학습을 하는 것이다
그래서 궁극적으로 세상 만물을 표현하는 여러가지 feature들을
각각의 dimension에 매핑하는 식으로 학습을 수행하게 된다
정리하자면 sparse autoencoder를 학습을 시키면
들어온 x에 대해서 이 x를 최종적으로 우리가 잘 맞출 수 있게 두 세가지 정보만 선택을 한다
얼마나 sparsity한가는 뒤의 alpha에 의해서 결정이 된다
아무튼 최대한 적은 수의 feature를 통해서 그 의미를 복구하도록 학습을 한다
그러다보니 중간 벡터에서 dimension들이 의미하는 것이
뭔가 세상의 여러 가지 의미들의 기저가 되는 elementry feature들을 학습이 되도록 하는 경향이 생긴다
동시에 각각의 feature는 feature를 activation 시키는 dimension들과 와이어링이 생긴다
그래서 결국에 korea라는 feature가 x안에 인코딩이 된다고 한다면
네트워크는 activation이 되면서 korea feature를 더욱 강하게 하는 작용을 한다
우리가 예시를 들 때는 korea와 capitial이 뭔지 알고있는 것처럼 가정을 했는데
실제로 모델이 학습을 할 때는 각각의 dimension이 무엇을 의미하는지까지는 알지 못한다
어쨌든 각각의 dimension이 elementry한 feature임을 나타낸다
그리고 이게 hidden state의 feature와 어느 정도로 관련이 있는지를 학습한다
기존의 hidden state 자체를 해석하는게 되게 어려웠었는데
이런식으로 매핑을 시켜놓으면 훨씬 해석하기가 쉬워진다

LM자체는 Claude3 Sonnet이라는
이미 학습이 되어있는 모델을 기반으로 실험을 진행하였다
해석을 위한 sparse autoencoder는 3개를 학습을 시켰는데
중간에 나오는 feature dictionary의 feature의 개수의 차이이다(1M, 4M, 34M)
이 sparse autoencoder 부분을 학습을 시키기위해서 쓴 데이터가
Sonnet의 pretrain data와 비슷하다고 한다

feature interpretation 부분을 위해서 그렇다면 어떤 기법을 쓰느냐
이렇게 학습된 sparse autoencoder에다가 굉장히 많은 텍스트를 집어넣어봤다
그럼 계중에 우리가 3번 feature가 무슨 뜻인지 해석을 하고싶다하면
이 3번 feature를 굉장히 크게 activation 시키는 text가 있을 것이다
그럼 우리는 그 text가 feature와 관련이 있다고 생각할 수가 있는 것이다
이 feature의 의미를 강하게 담고있는 토큰이기 때문에
그 토큰이 들어오면 강하게 actiavation이 일어나는 것이다
그래서 해석하고있는 각각의 feature에 대해서 20개의 text를 모았다
그래서 그 텍스트를 바탕으로 이 feature가 이런 것을 의미하는 것 같다~라는 것을 살펴보았다

첫 번째 예시는 Golden Gate Bridge이다
34M으로 학습시킨 SAE에서 31164353 dimension을 해석을 했을 때
이게 Golden Gate Bridge를 나타내는 것 같더라는 것이다
이걸 강하게 activate 하는 top 20을 모아봤더니
이게 전부다 golden gate bridgee였다

Brain Sciences라는 단어의 예시도 있다


이런 여러 가지 예시들이 나와있다고 한다

그리고 이 feature들이 단순히 영어에만 반응하는 것은 아니었다
이 golden gate bridge가 다른 언어의 텍스트에도 반응을 하더라는 것이었다
영어에 종속되어있는 feature가 아닌
golden gate bridge라는 의미를 담고있는 feature인 것이다
그런데 여기서는 사실 잘 되는 예제만 보여준 것이고
34million개가 다 해석이 잘 되는 것은 아니다

이 3가지를 기준으로 평가를 진행했다

어떤 feature가 정말로 highly interpretable 하다면
interpretation에 대한 텍스트만 주어졌을 때
어떤 text가 이 feature를 activation 시킬 것인지 아닐 것인지를 정확하게 맞출 수 있어야 한다
만약에 이 description을 보고서 내가 activation을 시킬지 안시킬지를
정확하게 알 수가 없으면 이 feature는 interpretability하지 않다고 전제한다
그래서 각각의 feature 별로 description을 GPT4에게 만들라고 한다
즉, 이 feature를 강하게 시킨 text를 GPT4에 주고선 feature description을 만드는 것이다
실제로 각각의 feature가 얼마나 interpretable 한지를 측정하기 위해서
그 feature를 highly activate하는 5개의 text를 뽑았다
이렇게 뽑은 5개를 GPT 3.5의 prompt에 넣어주고 위에서 만든 feature description을 같이 넣어줘서
각각의 토큰이 이 feature를 activation 시킬 수 있을지 못시킬지를 물어봤다고 한다
correlation이 높으면 결국 GPT가 feature description만 보고서 예측할 수 있기 때문에
이 feature는 interpretable하다고 판단한다

x축은 몇 번째 레이어인지를 나타내고
y축은 interpretability score를 나타낸다
5개의 방식을 비교하는데
빨간색이 sparse autoencoder를 사용한 것이다
다른 방식에 비해서 훨씬 더 높은 interpretability를 보였다
interpretability가 높지 않은 feature들은
하나의 feature가 여러가지에 반응을 한다던지하는 것들이다

target으로 하는 feature가 있는데 그 feature가 input text에 의해서 activation이 되었다
그럼 실제로 그 text와 관련된 concept이 text에 들어있냐는 것이다
golden gate bridge feature가 들어있으면 진짜로 그 text에 진짜로
golden gate bridge가 있는지 점수를 매겨보겠다는 것이다
이것은 Claude3 opus로 점수를 매겼고
그 feature의 description이 text와 얼마나 관련이 있는지 0점에서 3점으로 점수를 매겼다

점수 통계의 분포이다
activation이 0.9정도 된 text들에 대해서 0점에서 3점 사이의 점수분포가
어느정도 되었는지를 보는 것이다
activation이 0.1정도 되는 텍스트들에 대해서도 점수분포가 어느정도 되는지를 보고 분석하는 것이다
우리가 기대한 것처럼 실제로 activation을 적게 시키는 텍스트들 같은 경우에는
golden gate bridge에 대해서 관계없는 텍스트들이 많다
3점의 비율이 낮다
그래서 이 feature가 굉장히 유의미한 feature구나..하는 것이다

0.1점 정도를 한 번 살펴보자
bridge긴 한데 golden gate bridge가 아니다
강하게 activation을 시킨 것을 보면 훨씬 더 명확하게 golden gate bridge에 대해서 얘기하고있다
그리고 이걸 텍스트에만 반응하는게 아니다
이미지에도 반응을 한다
여기서 테스트했던 Claude Opus가 멀티모달이라서
text 해석이 끝난 다음 image도 넣어보면서
이 feature를 얼마나 더 강하게 activation 시키는지를 봤는데
결국 이 이미지들도 residual stream을 통과하도록 되어있기때문에
똑같은 결과가 나오더라는 것이다

각각의 feature가 어떤 의미를 갖고있는지는 알겠는데
그렇다면 이게 그냥 correlate 된 것인지 아니면 실제로 모델의 Output에 관여를 하는
causal effect를 갖고있는 것인지 궁금한 것이다
그렇다면 이런 causality를 어떻게 증명을 할 것인가
어떤 token이 들어왔을 때
3번 dimension을 억지로 강화시켜보는 것이다
그랬을 때 이 모델의 아웃풋이 어떻게 바뀌는지를 살펴보는 것이다
만약에 아웃풋이 우리가 기대한대로 바뀐다면 이 feature는 causal한 영향이 있다고 생각하는 것이다
우리가 관심이 있는 feature를한 5-10배 정도로 강하게 확대를 해서
이걸 다음 레이어로 넘겨봤다

왼쪽은 강화시키지 않은 것이고 오른쪽은 강화를 시킨 것인데
억지로 golden gate bridge feature를 강화시키면 답변이 오른쪽처럼 되는 것을 확인할 수 있었다

이것도 마찬가지

이 예시도 마찬가지인데
code error와 관련된 feature도 있는 것 같다는 것이다

문제가 없는 코드를 주고 코드를 실행 시키면 나름대로 왼쪽처럼 코드를 수행을 한다
그런데 이 모델에서 code error의 feature를 강화하면
이 코드에 에러가 없는데도 파이썬 에러메세지를 반환하는 것을 확인할 수 있었다
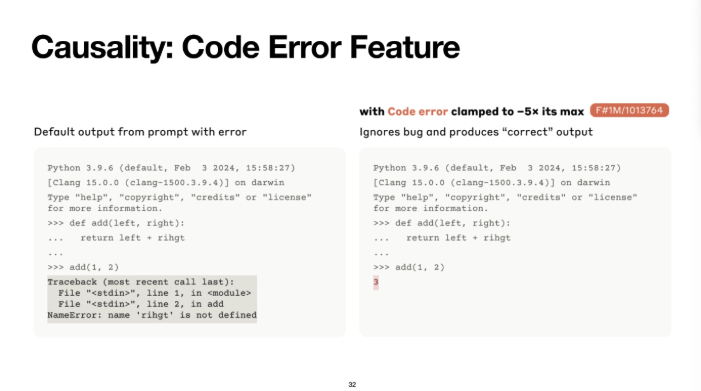
이것도 실제로 에러가 있는 코드를 넣었을 때
아무것도 하지 않으면 모델이 파이썬 에러를 내뱉는데
반대로 code error feature를 약화시키니 에러메세지를 안뱉고 답변을 뱉는 것을 확인할 수 있엇다

오늘 배운 내용을 한 번 정리해보자
hidden state에 있는 dimension들을 더 잘게 쪼개서 feature dictionary에 넣어보자는 것이다
이 feature들을 그럼 어떻게 해석할 수 있는지 .. 그런것들을 확인해볼 수 있었다
하지만 이러한 방법의 한계점은
SAE를 학습하는데에 시간이 너무 많이 걸린다는 것이고
많은 dimension들이 interpretable하지 않았다는 것이다
'강의 > NLP' 카테고리의 다른 글
| [NLP] Alignment - Learning from AI Feedback (1) | 2026.04.26 |
|---|---|
| [NLP] Alignment - Advanced Algorithms (0) | 2026.04.13 |
| [NLP] Alignment - Direct Preference Optimization (1) | 2026.04.12 |
| [NLP] Alignment - Reinforcement Learning from Human Feedback (InstructGPT) (1) | 2026.04.11 |
| [NLP] Supervised Fine-tuning (Instruction Tuning and Reasoning) (1) | 2026.04.11 |