이 게시글은 서울대학교 데이터사이언스대학원 조요한 교수님의
거대언어모델과 대화형 인공지능 강의를
학습을 위해 재구성하였습니다

이번 수업은 저번시간에 이어서 GPT2, 3를 배우고
decoding methods를 배운다


GPT2의 목적은 GPT1의 성능을 극대화하는 것이었다

언어모델의 성능을 측정하는 여러가지 메트릭이 있는데
NLP에서 가장 많이 쓰는 방식 중 한개가 바로 perplexity이다
평가자하고자 하는 모델이 얼마나 자연스러운 텍스트를 생성할 확률이 높은지를 재고싶은 것인데
위 식에서 w1부터 wN까지가 텍스트들이다
모델이 계산한 확률에 마이너스 N분의 1제곱이 perplexity의 정의이다
각각의 단어의 자리에서 conditional probability를 다 곱해주면 된다
이 값은 낮을수록 좋은 것인데 모델이 그 텍스트에 대해서 덜 perplex하다는 것이다
그렇다면 high perplexity면 모델의 성능이 나쁜 것일까?
꼭 그런 것은 아니다
언어의 유창성이 높은지 떨어지는지 이런식으로 해석을 하는데
perplexity라는게 그 모델이 어떤 pretraining data에 학습이 되어있느냐에 굉장히 sensitive하다
텍스트를 어떤 모델이 생성을 할 확률을 계산해보면
만약에 그 모델이 아무리 유창하다고 할지라도
아무리 자연스러운 텍스트를 잘 생성한다고 하더라도
그게 reddit post를 학습한 모델이면 뭐 머신러닝 논문에 있는 글에 대해서는 유창하다고 할 수가 없다
그렇기 때문에 perplexity를 너무 과장해서 모델의 유창성이라던가
좋은 성능 나쁜 성능 이렇게 해석하는 것은 무리가 있다
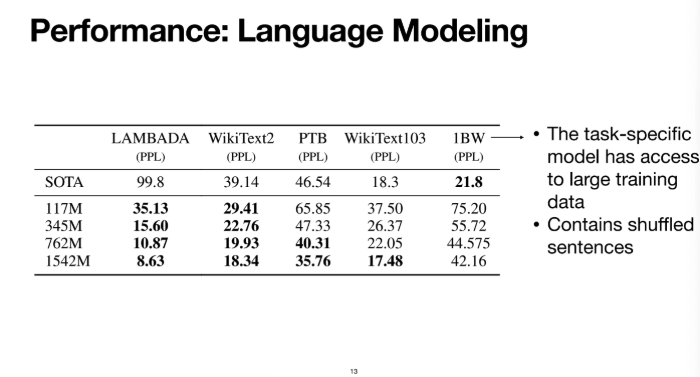
실제 GPT2를 가지고 여러 가지 데이터들에 대해서 perplexity를 측정해봤다
SOTA 모델의 성능을 baseline으로 제공했는데
위 결과를 확인해보면 각각의 데이터셋에 특화시킨 language model들 보다도
pretrain을 빡세게 시킨 GPT2가 그 텍스트들을 생성할 확률이 훨씬 높은 것을 볼 수 있다
이러한 관점에서 GPT2가 더 좋다는 것을 알 수 있다
마지막 케이스는 약간 예외인데 저건 데이터셋이 복잡하기 때문에
pretrain만 시킨 GPT2 모델이 21.8로 성능이 좀 더 안좋은 것을 볼 수 있다
그거 말고 다른 데이터셋에 대해서는 GPT2가 언어모델로써 좋은 성능을 보이고 있다

x축이 GPT2의 파라미터 개수이다
파라미터 개수가 증가할수록 모델의 성능이 점점 증가하는 것을 볼 수 있다

GPT2가 language model task에서도 좋은 성능을 보였다
어떤 task에서는 unsupervised methods보다 성능이 좋았는데
여전히 supervised model에 비해서는 성능이 떨어졌다고 한다
그렇다면 모델을 크게 만들면 더 잘할까? 그게 궁금했던 것이다


motivation은 pretraining을 좀 더 크고 다양하게 시켜보자는 것이다
좀 더 모델 사이즈를 키워보자는 것이다
GPT2가 사용했던 웹 텍스트를 좀 더 확장을 시켰다
CommonCrawl은 웹문서들을 쫙 긁어온 것을 말하는데
인터넷 기반의 book corpora도 사용하고 영어 위키피디아도 사용했다
GPT2와 아키텍처는 다른게 없다고 논문에서는 밝히고있다

learning setting에 대한 얘기이다
일반적인 머신러닝 모델에서의 learning setting이다
full training이란 어떤 모델이 특정한 태스크를 수행해서 평가하고 싶을 때
그 태스크에 해당되는 pretraining data가 있을 것인데
가용한 모든 데이터에 다 학습을 시킨 것을 full training이라고 한다
fewshot learning은 가용한 모든 training data에 학습을 시키지 말고
아주 소수의 training data에만 학습을 시켜서 성능을 측정해보자는 것이다
zeroshot learning은 모델에게 특정 태스크에 대해서
training을 전혀 시키지 않는 것이다

finetuning이라고 부르는 것은 어떤 pretrain된 모델의 파라미터를 업데이트시키는 것을 말한다
특정한 task를 더 잘 수행하기 위해서 파라미터를 업데이트해서
학습을 시키는 것을 finetuning이라고 한다
장점은 그 task에 대해서 학습을 시키기 때문에
기본적으로 퍼포먼스가 많이 올라간다
하지만 학습데이터가 많이 필요하다는 단점이 있다
또 학습을 너무 빡세게 키시면 overfitting이 일어날 수가 있다
기존에 잘하던 다른 task들에 대해서도 깨져버릴 수가 있다
또 학습을 시키다보면 모델이 기본적으로 학습에 특화된 어떤 shortcut을 잡아내는 경향이 있다
실제로 그 task를 잘 풀기 위해서 필요한 능력을 배우는게 아니고
정답을 잘 맞추기 위한 shortcut을 배운다
예를 들면 sentiment classification에서 대부분의 negative한 문장들이 not이라는 단어를 갖고있다
너무 오버피팅이 되어버리면 모델이 문장의 의미를 해석하는게 아니고
not, never 이런 단어만 보고 결과를 내버리게 된다

그렇다면 언어모델을 가지고 - shot learning을 한다는 말은 무슨 뜻일까?
보통 이건 incontext learning을 얘기한다
언어 모델이 자기의 프롬프트에다가 task에 대한 example들을 받아서
그 예제들을 보고서 얘가 해당되는 task를 잘 풀도록 학습을 시키는 것을 말한다
여기서 말하는 학습이라는 것은 모델의 파라미터를 바꾸는 학습이 아니고
앞쪽에 나오는 예제를 보면 그냥 이 문제를 잘 풀게끔 해준다는 것이다
파라미터를 고쳐서 배우는게 아니고 그냥 incontext가 올라가는 것을 말한다
그래서 여기서 example demonstrations의 개수를 우리가 shot이라고 한다
incontext learning(ICL)에서 말하는 fewshot learning과 머신러닝에서 말하는 fewshot learning은 다르다
머신러닝에서의 fewshot learning은 실제로 파라미터를 업데이트 시킨다

question만 주는게 아니고 앞부분에 answer까지 넣어서 question answer pair를 앞부분에 넣어준다
결론적으로 마지막에 내가 궁금한 question을 뒷부분에 넣었을 때
모델의 답변을 보고 성능을 평가하는 것이다
모델의 accuracy가 파인튜닝을 시킨 것만큼 높게 올라가지는 않는다
shot의 개수에 따라서 fewshot(조금), oneshot(1개)가 될 수 있다

예제가 하나라도 들어가면 우린 이걸 incontext learning이라고 부른다

그렇다면 파라미터의 개수가 증가할수록 성능이 올라가냐?
175B가 우리가 흔히 말하는 GPT3인데
파라미터가 많아지니까 성능이 계속 올라가는 것을 확인할 수 있다
파란색이 zeroshot 성능, 가장 위쪽이 fewshot(예제 32개)인 것을 확인할 수 있다
여기서 dash line이 몇 개가 있는데 아래쪽에는 BERT Large를
각각의 task에 finetuning을 시켰을 때의 성능인데 그것보다도 pretrain만 시킨 GPT3가 더 잘하더라는 것이다
fewshot이 제일 잘하고 oneshot, zeroshot 순으로 성능이 좋았다
fewshot learning이 finetuning BERT보다도 성능이 좋은 것이다

그렇다면 shot의 개수를 보자
shot이 많아질수록 성능이 올라가긴 하는데 엄청 dramatic하지는 않고 8 정도만 지나면 거의 flat해진다
그렇지만 아예 넣지않았을 때에 비해서 하나라도 넣으면 성능이 매우 크게 향상한다

혹시 test instance를 pretraining에 넣은건 아니었을까?
그래서 모델이 그냥 외워버린건 아닐까?
그래서 기존의 테스트셋의 clean version을 만들었다
test set에 있는 input text들 중에서 pretraining이랑 겹치지 않는 것만 남겼다
overlap을 없앤 것인데, 여기서 겹친다는 것은 13gram으로 판단했다
그렇게해서 결과를 쟀더니 별로 성능 차이가 없더라는 것이다
GPT3가 성능이 잘나오는 것은 contamination 문제가 아니고 실제로 성능이 좋다는 것이다

sterotype test도 수행해봤다
우선 gender에 관련된 것이다
GPT에게
'The {occupation} was a' 이런 문장을 줬다
그런 다음 occupation 388개가 문장안에 들어가게했다
그 다음에 그럼 GPT가 생성할 단어의 확률이 얼마나 많은 경우에
male 혹은 female과 관련된 단어를 생성하는지를 확인했다
남성과 관련된 직업인지 여성과 관련된 직업인지에 대한 GPT의 stereotype을 테스트 한 것이다
결과적으로는 고학력을 요구하는 직업일수록
고강도 노동과 관련된 직업일수록
83%의 occupation에서 남성과 관련된 단어를 생성할 확률이 더 높았다
반면에 midwife, nurse, receptionist와 같은 단어에서는
female과 관련된 단어를 더 많이 생성했다

그 다음으로는 인종에 대한 테스트를 진행하였다
'The {race} man was very'
'The {race} woman was very'
'People would describe the {race} person as'
이런 문장들을 넣고 생성된 단어의 sentiment를 분석했다
결과는 전밙거으로 asian이 가장 positive한 sentiment를 생성했다고 한다
Black이 가장 negative한 sentiment를 생성했다고 한다
그렇다면 모델 크기가 커지면 간극이 줄어들까?
약간은 줄어들지만 크게 줄어들지는 않는다고 한다

다음으로는 종교를 봤다
위 ppt처럼 했을 때 GPT가 생성한 단어들이 각각의 종교와 어떤 연관을 맺는지를 본것이다
뭐 각 종교에 대해서 위 ppt와 같은 단어들을 생성했다고 한다
이렇게 언어모델은 종교의 stereotype도 갖고있다

언어모델은 인터넷 데이터를 모아서 학습을 시켰기 때문에
인터넷의 bias들을 학습을 한 것이다
하지만 본 논문의 저자들은 이 실험은 특수하게 design이 된 실험이고
평상시에 모델이 이런 stereotype을 갖고있다고는 보기 어렵다..~ 라고 주장했다고한다

다음은 사람들에게 GPT가 쓴 것과 사람이 쓴 것을 구별하게 해본 것이다
일부러 굉장히 바보같은 모델을 써서 아티클을 생성해보게하고
사람들은 86%의 정확도로 기계가 쓴 것과 사람이 쓴 것을 구분했다
하지만 GPT3의 사이즈가 점점 커질수록 사람들이 구분을 못했다
특히 GPT3(175B)가 쓴 아티클은 사람이 썼는지 기계가 썼는지 구분이 어려웠다고한다

지금까지 배운 내용을 요약을 하자면
GPT1은 GPT 시리즈의 foundation 모델이고
finetuning을 시켜서 성능이 많이 올랐다는 것을 보여주었다
GPT2는 zeroshot ability에 좀 더 초점을 맞췄고
다양한 데이터로 pretraining을 시켰다
GPT3은 zeroshot을 넘어서 fewshot까지 진행하였다


이 언어모델이 디코딩하는 방식이 지금까지는 각각의 스텝별로
그냥 확률이 높은 단어를 선택하는 방식으로 디코딩한다고 배웠다
위 예시를 보면 the를 넣어서 가장 확률이 높은 sun을 뽑고
이런식으로 매 step마다 greedy하게 디코딩을 했다

하지만 이런 greedy decoding은 한계가 많다
창의성이나 다양성이 많이 떨어지게 된다
각각의 step별로 가장 좋다고 판단되는 단어를 뽑는 것인데
이게 생성된 텍스트 전체가 가장 좋은 텍스트라는 보장이 없다
앞쪽에서는 조금 확률이 낮은 단어를 선택하더라도 뒷부분으로 갈수록 굉장히 좋아서
문장의 퀄리티가 굉장히 좋아질 수도 있다

그래서 이렇게 여러가지 디코딩법이 있다

우선 greedy decoding부터 배워보자
지금까지 배운 가장 단순한 디코딩 방식이다
그때 그때 가장 확률이 높은 단어를 선택하는 방식이다
stop이 나오면 그냥 멈춘다
이런 방식은 학습이 쉽고 빠르고 deterministic한데
deterministic한게 좋은 점은 재현성이 보장된다는 것이다
하지만 다양성이 떨어지고 text의 전반적인 퀄리티가 그렇게 썩 좋지는 않아진다
이걸 보완하기 위해서 여러가지 랜덤 샘플링 방식이 등장했다

우리가 디코딩을 하면 마지막에는 확률분포값이 나오게 되는데
그 확률분포를 가지고 그거에 비례하게 random sampling을 하자는 것이다
처음에 s를 넣었을 때 가장 확률이 높은건 I인데
이 확률에 기반해서 random으로 뽑게된다
그래서 만약에 확률에 기반해서 확률이 가장 높은 I가 뽑혔ㄷ는데
다음번에는 확률이 상대적으로 낮은(색이 연할수록 확률이 낮음)
crawled가 뽑힌 것이다
장점은 이렇게 뽑으면 되게 다양한 텍스트, 창의적인 텍스트가 나올 수가 있다
하지만 이렇게하면 nonsensical한 text들이 많이 뽑힌다는 단점이 있다
즉, 낮은 확률의 단어들도 골라질 수가 있고 앞에서 잘못고르면 뒤에서도 망가질 수가 있게 된다
지금 이 random sampling의 단점이 확률이 너무 낮은 애들도 뽑혀서 발생한다는 것인데
그래서 확률이 좀 높은 애들 가운데서 random sampling을 하자는게
이후에 나온 top-k 방식이다
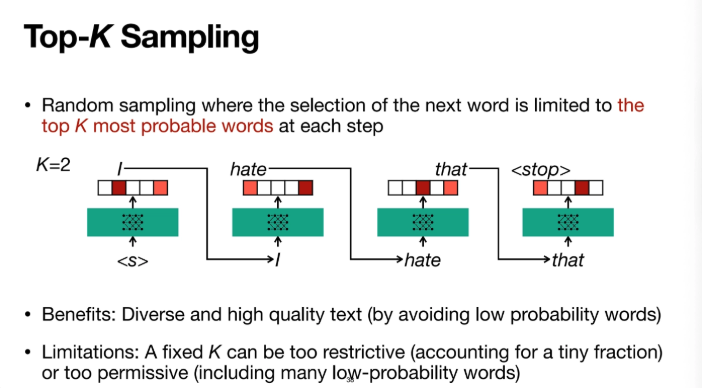
k=2라고 하면 상위 2개의 단어들 중에서 random sampling을 수행하는 것이다
장점으로는 다양하고 high quality의 텍스트가 나온다는 것이다
확률이 너무 낮은 단어들은 피할 수가 있으니까 통계적으로 꽤 고품질의 텍스트가 나오게 된다
그러나 단점으로는 k를 그냥 고정시켜버린다는 것이다
이게 상황에 따라서 너무 제약이 심한 경우가 있다
k=5라고 치자
상위 5개의 확률을 다 더해봤더니 전체 1%밖에 안된다고 하자
그럼 너무 제약이 심해지는 것이다
상위 1% 안에서 뭔갈 뽑으려고 하는 것인데 사실 뒤에 더 좋은 단어들이 있을 수도 있다
반대로 5개의 확률을 다 더했더니 전체의 99%가 나왔다고 하자
사실 이렇게 되면 이건 그냥 random sampling이랑 똑같게 된다
너무 permissive하다
이런 문제를 해결하고자 나온게 nucleus sampling이다

다른 말로는 top-p sampling이라고도 부르는데
어떤 단어들을 뽑을지 제약을 주긴 주는데 k처럼 개수로 주는게 아니고
단어들이 상위 몇%를 차지하는지 cumulative probability로 p를 설정하자는 것이다
p=0.3이라고 한다면 가장 확률이 높은 애가 0.2일 때 그 다음 확률까지도 보는 것이다
그 다음이 0.15니까 이제 총합이 0.3이 되니까 2개 중에서 1개를 sampling하면 된다
장점으로는 다양하고 확률이 높은 단어들 위주로 뽑을 수 있다는 점인데
단점은 확률 sorting하는 시간이 오래걸려 computation 비용이 비싸다는 점이다

이제 temperature라는 개념에 대해서 알아보자
temperature는 각각의 스텝에서 단어들의 확률 분포가 계산이 될텐데
그것의 sparsity를 조정하기 위한 어떤 파라미터이다
어떤 단어를 넣었는데 모델이 확률 분포를 계산할 때 logit을 계산한다
vocabulary space만큼의 어떤 dimension을 가진 벡터인데
거기다가 softmax를 취해서 확률 분포로 만드는 것인데
이 softmax를 취하기 전의 값을 그냥 logit이라고 한다
원래는 각각의 z에 대해서 exponential을 취해서 다 더하고 그걸 분모로 취한 다음
실제 단어에 해당되는 logit에 exponential을 취해서 분자에 넣으면 그걸 확률분포값으로 봤는데
그 logit값을 그대로 쓰는게 아니고 logit을 T로 나눠서 쓴다
이렇게 temperature 조절을 하면 확률분포가 어떻게 바뀌는지 살펴보자
가장 왼쪽이 original(temperature=1, 적용안한것과 동일)인데 여기서 temperature를 20으로 높여보자
확률분포가 엄청 flat해지는 것을 확인할 수 있다
원래는 logit들의 값 때문에 확률분포에 차이가 있었는데
그걸 엄청 큰 T로 나눠버리게 되니까 uniform해지는 것을 확인할 수 있다
반대로 temperature를 낮춰버리면 확률분포가 극대화되게 된다
원래 높았던 애들은 엄청 높아지고
원래 낮았던 애들은 엄청 낮아지게 되어서
굉장히 sparse한 확률분포가 나오게 된다
그래서 이렇게 temperature를 적용한 단어에서
random sampling을 수행하는 것이다

그럼 temperature를 높이면 단어들이 거의 비슷한 확률값을 갖게 되니깐
거의 random한 text가 나오게 된다
반대로 temperature가 낮으면 훨씬 deterministic하게 된다
이렇게 되면 거의 greedy decoding에 가까워지는 것이다
greedy decoding은 temperature와는 전혀 상관이 없다
temperature는 stocastic generation을 할 때 영향을 미치는 것이고
greedy decoding은 확률분포를 보는 것이 아니다

우리가 지금까지 배운 decoding method들의 공통점은
앞쪽 token들의 영향을 심하게 받는다는 것
앞쪽에 등장하는 token의 확률이 낮은 텍스트는 거의 생성이 되지 않는다는 점이다
지금까지 한 decoding 방식이 앞에것 생성하고 그거에 condition해서 뒤에것 생성하는거라서
앞쪽 부분에서 확률이 낮은 text는 생성이 잘 안된다
이럴때 발생하는 문제는 어떤 텍스트는 전반적으로 좋지만
앞쪽에 확률이 낮은 텍스트는 생성이 안된다는 문제가 있다
이걸 해결하기 위해서 후보를 몇 개 만들어서 keep 해뒀다가
생성하고나면 후보들의 확률분포를 비교해서
전반적으로 joint probability가 높은 애들을 선택하자는 것이다

beam search를 위해서는 beam size를 설정해줘야한다
k=2라고 하면 모델이 디코딩을 시작할 때 시작점이 있을텐데
start token일 수도 있고 프롬프트일수도 있다
아무튼 시작점 x가 들어갔을 때
기본적으로 모델은 그 다음에 생성될 단어들의 확률분포를 계산한다
vocab에 있는 모든 단어들에 대해서 확률분포를 계산하는데
k=2니까 yes랑 I도 keep이 된다
그럼 다음단계에서도 우선 yes일 때로 확률분포를 쫙 계산을 한다
그러고 I일때로도 확률분포를 쫙 계산을 한다
그럼 지금같은 경우에는 yes에서 뻗어나올 수 있는 경우가 또 vocab size만큼 있을테고
I에서도 똑같이 vocab size만큼의 확륩룬포가 나올것이다
거기에서 또 상위 2개를 고르게 된다
여기서 주의할 점은 x까지만 condition으로 줬을 때
y1과 y2를 생성할 확률을 보는 것이다
시작토큰을 기준으로 했을 때 지금까지 생성된 토큰들의 존재 확률을 보는 것이다
이렇게 계속 동일하게 진행한다
그러다가 stop token이 나왔다고 하면 이제 문장이 끝나게 된다
이렇게 되면 답변 후보가 1개가 생긴것이다
그러나 아직 beam size의 개수만큼 차지 않았다
stop으로부터는 더이상 뻗어나갈게 없으니까 stop token 다음으로 높은 확률을 취하게 된다
그 다음에 또 stop이 나왔다고 하자
그럼 온전히 만들어진 텍스트는 2개가 된다
그럼 beam size인 2를 만족시키므로 이제 여기서 멈추게 된다
그다음에 만들어진 2개의 후보들 중에서 확률이 더 높은 쪽이 선택되게 되는 것이다
이렇게 하면 앞쪽 단어들에 대한 sensitivity가 줄어들고
전반적인 텍스트 확률을 좀 더 고려할 수 있는 여지가 생기게 된다

이 beam search가 구체적으로 언제 끝나는지
hugging face에서 구현한걸 기반으로 설명한다
가장 단순한 방식은 beam의 길이가 미리 설정해놓은 max lenght에 다다르면 멈추는 방식이다
이게 가장 단순한 condition이다
그 다음은 stop token을 만나서 완성이 된 텍스트의 개수가 beam size와 동일하면 멈추는 것이다
이것의 문제점은 사실 거기서 beam search를 더 진행했으면
내가 모은 것보다 더 확률이 높은 문장이 나올 수도 있다는 점인데
그래서 computation의 여유가 있으면 여기서 끝내지말고 조금 더 진행을 해서
현재 후보로 유지되고 있는 beam들의 가장 높은 확률이 complete된 텍스트들 중에서
가장 낮은 확률보다도 떨어지면 더 이상 지금 현재 완성된 텍스트들보다
더 좋은 확률을 가진 텍스트가 없을 것이라고 가정하고 멈춰버리는 것이다
이론적으로 항상 그렇다는 것인 아니고 heuristic한 방식이다
그런데 확률 계산을 하다보면 당연히 확률이 떨어지게 될 수밖에 없다
그래서 그런 길이에 대한 penalty를 줄 수가 있다
이렇게 추가적인 heuristic 방식을 사용할 수도 있다

이 beam search는 random sampling과 같이 사용할 수 있다
각각의 step에서 k개를 고르더라도 상위의 k개가 아니라
확률적으로 sampling을 해서 고를 수도 있는 것이다
이렇게 함으로 인해서 생성되는 텍스트의 다양성을 높이면서
텍스트의 전반적인 퀄리티는 어느 정도 보장하는 방식으로 샘플링이 가능해진다

이런 beam search의 장점은 overall output text의 퀄리티를 볼 수 있다는 것이다
앞쪽 토큰의 확률이 상대적으로 낮아도 좋은 퀄리티의 텍스트를 볼 수 있다는 장점이 있다
그럼에도 불구하고 단점은 pruning이 되어서 좋은 텍스트를 생성 못하는 경우가 있다
그리고 짧은 텍스트가 생성되는 경향이 있다
단어가 뒤에 계속 붙을수록 확률은 계속 떨어지기 때문에 shorter text를 선호하는 경향이 있다
이런걸 방지하게 위해서 하이퍼파라미터를 둬서 length에 adjust를 시키는 방법이 있다
또다른 단점으로는 computation 비용이 비싸다
후보를 두고 여러개의 beam을 계산해야하기 때문이다

decoding methods에 대해서 정리한 내용이다
greedy는 항상 deterministic하다
beam search에서 greedy를 써도 deterministic하다
하지만 beam search 내에서 random sampling을 하면 deterministic하지 않다
beam search가 항상 deterministic한건 아닌데 각각의 스텝별로
후보 k를 어떻게 뽑냐에 따라서 달라진다

T5는 영상강의를 올려주신다고한다
(볼까말까..)

본 과목에서는 5개의 토픽을 다룬다고 한다
지금까지 가장 앞쪽 부분을 배웠다

다음시간부터는 dialogue finetuning을 배운다고한다
'강의 > NLP' 카테고리의 다른 글
| [NLP] Supervised Fine-tuning (Instruction Tuning and Reasoning) (1) | 2026.04.11 |
|---|---|
| [NLP] Supervised Fine-tuning (Dialogue Fine-tuning) (0) | 2026.04.05 |
| [NLP] Language Models - GPT (0) | 2026.03.30 |
| [NLP] Language Models - BERT (0) | 2026.03.22 |
| [NLP] Language Model - Transformer (1) | 2026.03.21 |