이 게시글은 서울대학교 데이터사이언스대학원 조요한 교수님의
거대언어모델과 대화형 인공지능 강의를
학습을 위해 재구성하였습니다

이번에 정리해 볼 내용은 GPT이다

지난 시간에 배운 내용을 살짝 복습해보자
지난 시간에는 transformer의 encoder와 decoder를 배웠고
좋은 foundation model로 거듭나기위한 pretraining 과정을 배웠다
그리고 BERT를 배웠는데
이 BERT에서 transformer 구조를 잘 활용하기 위해 2가지 pretraining을 수행한다
첫 번째가 Masked Language Modeling과
Next Sentence Prediction이었다

그 결과로 각각의 attention head가 linguistic property를 담당하는 역할을 수행하게 됐다
attention head는 각각의 단어에 대해서 주변에 있는 단어의 정보들을 끌어와서
그 단어의 embedding에 집어넣는 그런 역할을 수행했다

그리고 주로 FFN에서는 world knowledge를 파라미터에 저장하는 경향이 있었다
이 FFN에 들어있는 파라미터에는 세상에 대한 지식이 있었다
이것이 나중에 downstream task를 수행할 때 유용하게 쓰인다

오늘 배울 내용은 GPT에 대한 내용이다


지피티는 대표적인 decoder model 중 하나이다

decoder와 encoder의 차이는 무엇일까
decoder는 기본적으로 텍스트 생성을 하는 과정이다
그냥 텍스트의 시작을 의미하는 <S>라는 special token을 집어넣고 디코닝을 시작한다
decoding도 multihead attention을 수행한다
<S>랑 initial embedding이 들어오면 Q, K, V를 만들어낸다
이걸 가지고 self-attention을 수행한다
어차피 S 하나밖에 없기때문에 자기 자신에 대해서만 처음에는 self attention을 수행할 것이다
이렇게 하면 output vector가 하나 나오고
두 번째 multihead attention에 대해서도 동일하게 수행하게된다
그 다음에 이걸 가지고 원래의 vector의 dimension으로 맞춰주기위해서
linear transform을 한 번 수행하고
residual + layer norm을 수행한다
그런 다음 FFN을 거치게 된다
마지막 FFN을 거친 다음에 거기서 끝이 나는게 아니고
다음 단어를 생성하는 과정 하나가 더 들어가는데
이걸 우리가 unembedding layer라고 부른다
embedding layer는 단어를 dense vector로 바꿔주는 것이었는데
unembedding layer는 그 반대라고 보면 된다
즉 dense vector를 다음 단어로 바꿔주는 것이다
이 vector에 대해서 vocabularly size만큼의 dimension을 갖도록
linear transform을 한 다음 softmax를 취해서 가장 확률이 높은 인덱스의 단어를
다음 단어로 선택하게 하는 것이다
FFN에서 계산된 x를 1*d 차원이라고 한다면
unembedding layer 같은 경우는 d*V 사이즈의 matrix가 된다
그리고 그렇게 나온 결과는 logit이라서 z이고
x'의 unembedding을 곱하면 1*V가 된다
p(wi)는 z로 softmax를 취해준다

이번에는 self attention을 할 토큰이 2개가 되었다
똑같이 Q, K, V를 구하고 2개의 토큰에 대해서 attention을 수행한다
이걸로 aggregation을 구하고 두 번째 헤드, 세번째 헤드에 대해서도 동일하게 수행한다
linear transform을 거치고 FFN도 거치고 unembedding layer도 거쳐서
vocab size의 벡터로 변환하고 softmax를 취해서 다음 단어를 예측한다

이런 과정을 보통 masked attention이라고 한다
각각의 token에서 attention은 자기보다 앞에 등장하는 단어에만 줄 수 있다
the와 <S>는 자기 자신에 대해서만 attention을 할 수 있고
미래에 나올 단어 cat에 대해서는 attention을 할 수가 없다
그래서 인코더에서는 bidirection이었는데 decoder에서는 한 쪽 방향만 가능하고 나머지는 mask가 되어있다
그래서 이걸 masked attention이라고 한다

일단 one hot vector로 시작해서 initial embedding을 계산한다
position도 같이 계산한다
1번만 1이고 나머지는 0인 position embedding과 vocab인 one hot vector를 합쳐서
initial embedding을 만들어서 레이어로 들어간다
레이어를 거쳐서 output으로 단어를 뱉어내고 그 단어가 다음 번에 들어간다
inference를 할 때도 계속해서 생성을 하다가
stop을 하면 거기서 멈추게 되고
지금까지 생성된 것만을 반환하게 된다

인코더와 디코더의 공통점과 차이점을 살펴보자
인코더와 디코더 모두
multi-head attention, feed forward, residual layer norm을 수행한다
차이점으로는 decoder는 앞에 있는 token들에 대해서만 attention을 수행한다
encoder는 bidirectional이다

디코더는 인코더와 다르게 마지막에 레이어가 하나가 더있다
unembedding layer인데 다음 단어를 예측하기 위한 레이어이다
cross attention layer라는 것도 갖고있는데
디코더가 처음에 masked attention을 할 때는
현재 디코딩 된 단어들끼리 attention을 하는건데
cross attention은 인코더에 있던 단어들과도 attention을 수행한다
사실은 이게 원래 original architecture인데
이 cross attention layer가 각각의 input token들 과의 attention도 계산을 해서 embedding을 하겠다는 것인데
GPT같은 경우는 인코더가 아예 없기 때문에
cross attention layer가 아예 없다

결국에는 이 디코더를 이용해서 pretraining을 잘 해야하는 것인데
수행해주는 pretraining은 NextWordPrediction이다
저렇게 문장이 하나가 주어지면 이걸 가지고 다음 단어를 예측하도록 학습시킨다
처음에 시작 토큰이 들어가면 그 다음 단어인 the를 예측하도록 학습시키는 것이다
그 다음자리 the 다음에 cat을 집어넣도록 학습시키고
이렇게 쭉쭉해서 door을 집어넣었을 때 stop을 예측하도록 학습시킨다
그림은 이게 이렇게 여러 개를 그렸지만 쟤네는 다 같은 모델이다
하나의 모델을 그냥 여러개 그려놓은 것이고
그래서 각 토큰끼리 파라미터는 서로 공유된다
각각의 자리에서 학습할 때마다 동일한 파라미터들이 학습된다
이 학습과정은 masked language model과 비슷한데
masked language model은 문장의 중간중간에 뚫어놓는것이고
이건 마지막 자리에만 구멍을 뚫어놓는 것이다
꽤나 비슷한 spirit을 갖고있다고 보면 된다

이런 문장이 있다고 해보자
token이 레이어에 들어가서 마지막에 unembedding layer를 통해서 vocab size로 projection을 수행한다
그렇다면 <S>의 다음 단어인 the의 확률이 높도록 해야한다
우리가 확률은 softmax를 취해서 그 중에서 the라는 단어의 자리의 확률이 the의 확률이 될 것이고
그렇게해서 output이 the가 나온다면 그걸 다음 레이어에 넣어서 다음 단어가 cat이 나오게 하고싶은 것이다
그래서 두번째에서의 확률은 the랑 독립적인게 아니고 the를 given으로 했을 때의 확률이다
attention을 준다는 것은 the 자신에게도 attention을 주는 것이다
지금까지 학습된 맥락을 바탕으로 계속 임베딩을 하면서 올라가기 때문에
저기서 생성된 확률은 the에 conditioinal하다고 할 수 밖에 없다
왜냐하면 앞에서 the가 생성되지 않았다면 계산된 확률이 달라졌을 것이기 때문이다
문맥에 의존하고 conditional하기 때문에 최종적으로 생성된 확률은 conditional probability이다
뒤에 있는 부분도 마찬가지이다
세번쨰도 cat을 집어넣었을 때 나오는 probability는 the와 cat에 집어넣었을 때 walks가 나올 확률을 계산해야한다
하지만 계산 자체는 z3에 softmax를 취해서 구한다
그렇다면 joint probability를 한 번 계산을 해보자
이 전체 단어가 생성될 probability를 계산을 해보면
P(the) * P(cat|the) ... 이런식으로 쭈욱 joint probability를 구할 수 있다
그럼 이걸 학습시키려면 loss를 계산해야한다
각각의 자리의 token의 레벨에서 cross entropy를 수행해준다
i가 각각의 자리인데 각각의 자리에서 -log softmax를 하는 것인데
이게 token level에서의 cross entropy이다
그래서 이 next word prediction의 최종적인 loss는 joint probability의 log에
마이너스를 씌운 값과 동일하고 이것을 최적화하는 것이다

그렇다면 이게 왜 좋은 task일까?
next word prediction이 된다는 것은 해당 언어에 대한 완벽한 이해와
이 말을 하는 사람에 대한 완벽한 이해를 필요로하는 아주 어려운 task이다
이걸 잘하기 위해서 결국에 몯레은 굉장히 많은 정보를 학습해야한다
대표적이 linguistic information, syntatic semantic 등등.. 이런것들을 잘 학습을 해야한다

이러한 pretraining 과정을 통해서 얻는 한 가지 좋은 부산물이 생긴다
결국 모델이 다음 단어를 맞출 수 있다는 것은 그 텍스트를 외웠다는 것이다
그 텍스트를 외웠고 다음 단어를 정확하게 예측할 수 있으면
그 텍스트를 reproduce 할 수 있게 된다
그래서 언어모델이 세상의 굉장히 많은 지식들을 알 고 있는 것처럼 느껴지는 것이다
이 디코더의 구조를 보면 follow up text의 conditional probability를 계산할 수가 있다
이걸 바탕으로 가장 그럴싸한 text를 답변할 수 있다
이런건 dialogue system에서 매우 유용하다

GPT1은 book corpus라는 데이터셋을 사용한다
모델이 long range information에 condition을 해서
다음 단어를 생성하는 것을 학습하게 되는 것이다

모델이 자유롭게 문장을 생성하게 하고 싶으면 start token을 우선 넣어주면된다

우리가 보통 언어모델에 프롬프트를 넣는다는 표현을 자주 쓴다
그렇다면 프롬프트란 무엇일까
모델에게 어떤 response를 elicit하기 위해서 사람이 넣어주는 initial text이다
어떤 지시문이 될 수도 있고 dialogue history 자체가 될 수도 있다
위 예제에서 우리가 프롬프트가 the sun이라고 가정하자
그냥 앞에 <s>랑 the, sun을 넣어주면 된다
그럼 모델은 sun 자리에서부터 그 다음에 이어질법한 텍스트를 token by token으로 생성하게 된다
그래서 저 뒷부분을 prompt에 대한 response라고 얘기한다

프롬프트의 길이를 k라고 해보자
response는 k+1부터 N까지이다
그럼 우리가 궁금한건 어떤 프롬프트가 주어졌을 때
어떤 특정한 response가 생성될 확률이다
그래서 given prompt에 대한 conditional probability는

이렇게 된다

GPT1에 대해서 잠깐 보자
12개의 layer와 12개의 attention head가 있다
Wemb와 Wunemb는 사실상 같은 matrix를 사용한다
이게 직관적으로 비슷한 역할을 수행한다고 볼 수 있다
그래서 GPT 계열의 모델 같은 경우는 하나를 transpose 시키는 방식으로 학습을 시킨다
tokenization 방식으로는 byte pair encoding이라는 방식을 쓰는데
이건 오늘날에 많이 사용하는 방식이다
L2 regularization이 변형이 있었고
activation function으로는 GELU같은 함수를 사용했다고 한다
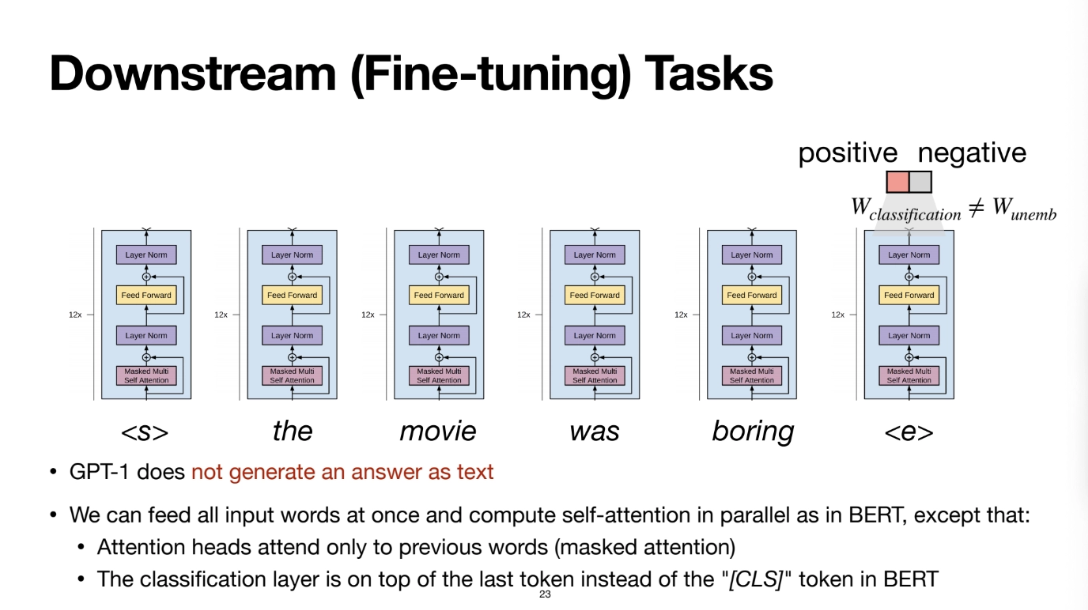
이렇게 pretraining이 끝났으면 finetuning을 시켜야한다
오늘나라 GPT를 쓸 떄 우리가 어떤 질문을 던지는데
GPT1은 그런식으로 하지는 않는다
위처럼 문장을 주고 이걸 classification을 하고싶다고 하면
그 head를 줘서 그걸 학습을 시켰다
task마다 head가 존재한다
Wunemb를 치우고 그 task를 위한 매트릭스를 달아서
classification이라고 하면 2차원으로 projection시키는
그런 Wclassification을 달아서 학습을 시킨다
BERT는 cls라는 토큰을 가장 앞자리에 넣어줬는데
여기서는 classification이 일어나는 extract token<e>를 제일 마지막에 넣어준다
얘를 젤 앞에 붙이면 attention을 할 수가 없기 때문에
뒤에다가 붙여주면 앞에 있는 모든 단어들을 다 attention을 수행해서
그 정보들을 다 모아서 embedding이 가능해지게된다

그래서 몇 가지 task를 수행을 시켰다
저번 시간에도 나왔던 natural langugae inference를 수행했는데
이게 GPT1에는 입력으로 어떻게 들어가고 output으로 어떻게 나올까
토큰이 start, premise, delim, hypothesis, extract 이렇게 들거간다
트랜스포머 레이어에 들어가서 거기서 나온 값을
linear transformation을 해서 3 dimension에 projection을 시켜서 학습한다
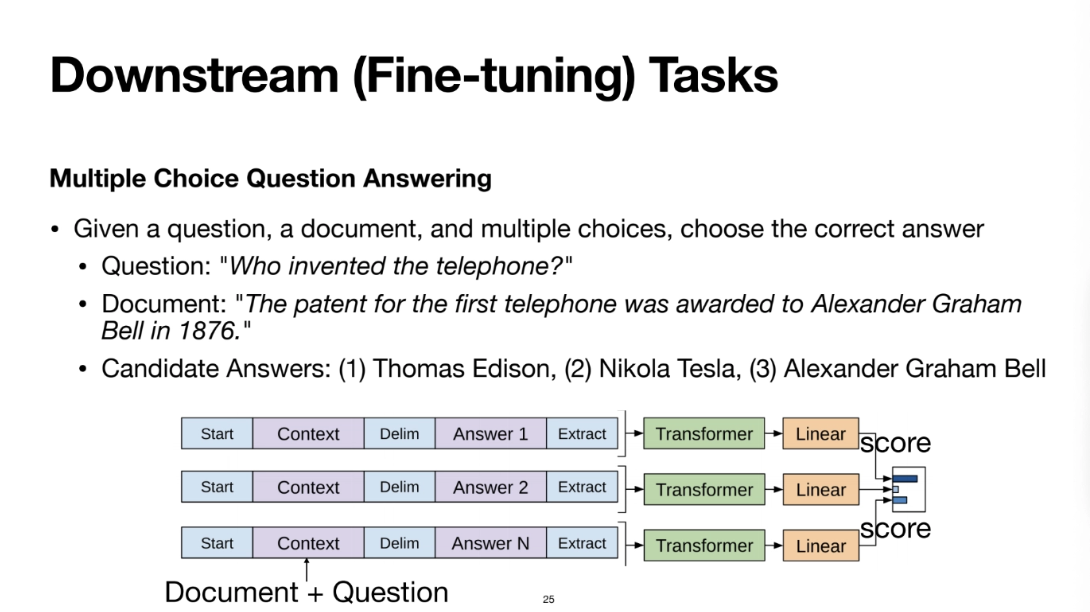
두 번쨰는 question과 document가 들어갔을 때 정답을 구하는 task이다
각각의 보기에 대해서 text를 따로따로 넣어준다
context와 answer를 첫번째 보기로(context는 document와 text를 합친것)
linear는 dimension이 1이 되도록 linear transformation을 시킨다
이걸 보기2, 보기3에 대해서도 수행을 한다
그럼 각각의 보기에 해당되는 score가 나오게 된다
그럼 그걸 가지고 softmax를 계산해서 확률 분포로 만들어서
그 중에 가장 확률에 높은 보기를 만들어서 정답이라고 하는 것이다

이제 classification task이다
binary classification을 수행하는 것인데
여기서 사용된 데이터셋은 CoLA이다

다음으로는 22개의 문장이 주어지면 두 개가 같은 의미인지
다른 의미인지를 맞추도록 하는 semantic similarity task이다
text1을 앞에 넣고 text2를 뒤에 넣은 input에 대해서
transformation을 거쳐서 나온 임베딩이 있고
순서에 민감할 수가 있어서 텍스트의 순서를 바꿔서 한 번 더 수정한다
그렇게 해서 나온 2개의 vector가 있으면 걔를 더해서 transformation을 수행해서 예측한다
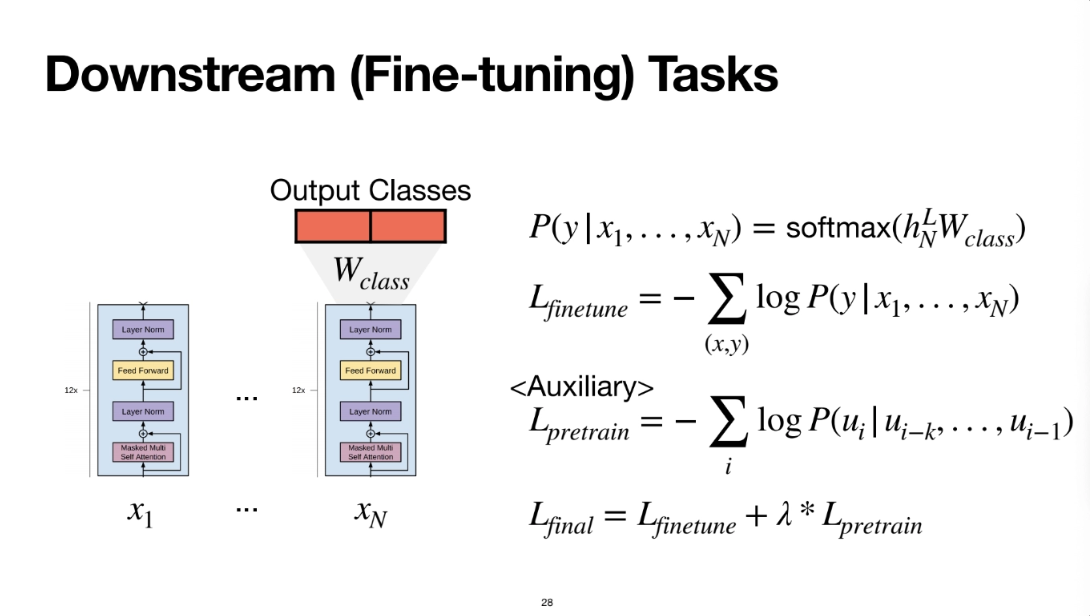
결국 최종적으로 마지막 token에 들어간 애에 대해서 classification을 수행한다
y는 정답 레이블이고 x는 입력이 된다
정답 레이블의 확률은 결국 저 자리에서 나온 마지막 토큰의(N) 레이어에서 나온 hidden state에(L)
softmax를 취한 값이기때문에
저 확률에 대해서 log를 씌운 값에 대한게 funetuning의 loss function이다
그런데 이렇게 하니까 pretraining 때 배웠떤 지식들을 까먹는 경향이 있었다
그래서 finetuning을 진행하면서 pretraining 때 했던 것들을 조금씩 수행해준다
이게 auxiliary인 것이다
그래서 마지막에 저런 식이 나오게 되는 것이고
저게 최종 로스가 된다

그래서 그렇게 해봤더니 지피티가 잘하더라~ 하는 것이다

얘네도 다 잘햇더라~

이런식으로 ablation study도 수행했다
pretraining을 시키지 않았떠니 성능이 굉장히 많이 떨어지는 것을 확인할 수 있었다

지금까지 우리가 배운 것은 파인튜닝이었다
zero shot ability에 ㄷㅐ해서 알아보자
zero shot이란건 파인튜닝을 시키지 않고 pretraining이 된 것만 가지고 얼마나 잘되는지가 궁금한 것이다
sentiment analysis같은 경우에는 문장이 있으면 원래 여기다가 classification을 달아서 학습을 시켰는데
그러지 말고 very를 붙여준 다음 very 다음에 모델이 생성할 확률을 보고
positive를 생성할 확률과 negative라는 단어를 생성할 확률을 비교해서
둘 중에 더 높은 걸 모델의 선택이라고 보겠다는 것이다
CoLA도 모델이 생성할 확률에 로그를 취해서 N분의 1을 해서
토큰별로 average 확률을 보았을 때, 이게 어떤 threshold를 넘으면
gramatical하다고 판단을 하고 아니면 ungramatical하다고 판단을 하는 것이다
왜냐하면 사람도 저런 문장을 생성할 확률이 굉장히 적기 때문에
이는 모델도 마찬가지가 될 것이다
모델이 학습이 잘 됐으면 ungramatical한 텍스트는 생성될 확률이 굉장히 낮아진다
question answering도 비슷하다
document와 question을 주고서 그 다음에 나오는 확률을 계산할건데
보기를 줘가면서 확률 계산을 해서
모델이 정답을 알고 있다면 실제 정답에 대해서 확률이 가장 높을 것이라는 것이다
Winograd Schema Resolution이라는 것도 있는데
이건 it이 가리키는게 his suitcase인지 the car인지를 맞추는 것이다
위 ppt의 경우에는 the car이다
사람은 이런 태스크를 잘 수행하는데 언어모델에게는 굉장히 어려운 태스크이다
그래서 저렇게 저 it에 둘다 넣어서 둘다의 확률을 봐서
모델이 둘 중에 뭘 더 자연스럽다고 생각하는지를 보겠다는 것이다
이건 그래서 학습을 하지않고 pretraining 된 것만 가지고 보는 것이다

각각의 색이 각각의 태스크이다
x축은 pretraining을 얼마나 많이 시키는지이고
y축은 performance를 나타낸다
pretraining은 많이 시키면 시킬수록 잘하게되고
결국 모델이 사람이 어떤 식으로 얘기할지 더 잘 학습을 한다는 것이다
그것으로 인해서 이런 NLP task도 더 잘하게 되는 것이다
human language에서 자연스러운게 뭘까를 더 잘 이해하면
그게 굉장히 많은 NLP task에 도움이 된다는 것이다
그래서 corpus가 큰 데에다가 학습을 시키는 것이 이 당시의 트렌드가 되었다
GPT2에 대해서 간단하게 살펴보자

우리가 위에서 봤던 zero shot ability가 GPT1이 꽤나 좋았다
아무튼 계속해서 밝혀진게 이 language modeling을 잘하는 모델들이
downstream task도 잘한다는 것이다
이 GPT2의 motivation은 GPT1의 zero shot ability를 끌어보자 하는 것이었다
학습데이터도 좀 좋은것으로 하고 모델 사이즈도 늘렸다

GPT1에 비해서 크게 변화한건 없다
위 ppt의 내용에 나와있는 것 정도로 변화했다

그렇다면 pretrainig data는 어떻게 더 좋은것을 쓴것일까
web text를 사용했는데
reddit이라는 웹 사이트를 활용했다
post가 있으면 거기에 댓글들이 달려있는데
좋아요를 많이 받은 코멘트와 포스트에 달려있는 하이퍼링크는
퀄리티가 좋은 것일거라고 가정하는 것이다
사람들이 재밌다고 생각하는 웹페이지거나 교육적이거나 웃긴 웹페이지일 가능성이 높다는 것이다
그래서 그 하이퍼링크가 걸린 웹페이지들을 다 모아서
중복을 제거하고 cleaning을 좀 하니까 8M개의 다큐먼트가 나왔다
당연히 wikipedia가 많았는데 이것들은 다 없앴따고 한다
GPT2를 개발한 메인 목적은 zero shot ability가 얼마나 좋은지를 보고싶었던것인데
NLP task들은 위키피디아 데이터로 한 것들이 많기 때문에
pretraining dataset에 이 위키피디아가 많이 들어있으면 정보의 leakage가 발생할 수 있었다
그래서 이 위키피디아 데이터를 원천차단 한 것이다
그리고 이런 트레이닝 과정에서 테스트하는걸 외워버리면 contamination이 발생하기 때문이다

GPT2는 이렇게 4개의 모델 사이즈가 있다
제일 큰 extra-large가 1.5B짜리고 이게 보통 우리가 말하는 GPT2이다

그래서 성능 측정을 했는데 여기서 측정한 성능 중에 하나가 language modeling이다
여기서 중요한 메트릭 중에 하나가 Perplexity이다
굉장히 많이 사용되는 메트릭 중에 하나인데
모델이 자연스러운 텍스트를 생성할 확률을 계산하는 메트릭이다

주어진 자연스러운 텍스트에 대해서 모델이 이 텍스트를 계산할 확률에
-N분의 1승을 해주는 것이다
이 perplexity를 해석을 하면 이 텍스트를 생성할 average likelihood가 나온다
N분의 1승을 하기 때문에 텍스트 전체의 확률이 아니고 단어별로의 확률이다
근데 마이너스가 붙었으니 그의 inverse가 된다
그래서 inverse of the average likelihood가 되는 것이고
이는 작을 수록 좋은 것이다
이 값이 작을수록 모델이 이 문장을 생성할 확률이 높다는 것이다
어떤 텍스트의 perplexity 값은 텍스트 하나가 있다고 주어지는 것이 아니라
모델이 어떤 사전학습 데이터가 주어지냐에 따라서 크게 왔다갔다 할 수 있다
이 텍스트의 perplexity를 계산을 할 때 내가 계산하려고 하는 모델이
reddit을 보고 학습을 했는지 아니면 ML paper를 보고 학습을 했는지에 따라 굉장히 달라질 수 있다
아무튼 perplexity가 기본적으로 재고자 하는 것은 모델이 natural text를 얼마나 잘 생성하는지 보고싶었던 것인데
그렇다고 perplexity가 높다고해서 이 text가 unnatural하냐? 그럴 수도 없는 것이다
굉장히 자연스러운 텍스트라고 하더라도 모델이 그 도메인에 대해서 학습이 안되어있으면
perplexity가 굉장히 높게 나온다
'강의 > NLP' 카테고리의 다른 글
| [NLP] Supervised Fine-tuning (Dialogue Fine-tuning) (0) | 2026.04.05 |
|---|---|
| [NLP] Language Models - GPT2, GPT3 and Decoding Methods (0) | 2026.03.31 |
| [NLP] Language Models - BERT (0) | 2026.03.22 |
| [NLP] Language Model - Transformer (1) | 2026.03.21 |
| [NLP] Language Models - Word2vec and Seq2seq (1) | 2026.03.08 |