이 게시글은
서울대학교 데이터사이언스대학원
조요한 교수님의
데이터사이언스 응용을 위한 컴퓨팅 강의를
학습을 위해 재구성하였습니다.
이번 시간에는 all-pair shortest path의
첫 번째 강의 내용을 정리해보려고한다
저번 시간에는 single-source shortest path(sssp)에
관한 내용을 2차례에 걸쳐 정리했는데
이번에는 all-pair이다

All-Pairs Shortest Path (APSP)는
주어진 그래프가 있을 때 모든 pair의 vertex에 대해서
shortest path를 찾는 것이다
이전의 sssp는 한 개의 vertex에 대해서
shortest path를 찾는 것이지만
apsp는 모든 vertex에 대해서 찾는 것이다
따라서 apsp에 관한 내용은 위의 ppt처럼
Matrix로 표현할 수 있다
row가 source, column이 destination이다
이러한 apsp는
각 도시들에서 도시들로 가는 경로
네트워크의 diameter를 구하는 곳에 사용될 수 있는데
네트워크에서는 각각의 vertex들 간의 거리들 중
가장 긴게 diameter가 된다

asps를 구하기 위한 Input graph를 한 번 살펴보자
그래프 G에 대해서 n개의 vertex가있고
input은 n x n 행렬로 나타낸다
w(i, j)는 i에서 j로 가는 weight이다
만약 i와 j가 같다면 w는 0
i와 j가 다른데 (i, j)가 실제 그래프G안에
존재하는 edge라면 w(i, j)가 되고
그렇지 않다면 무한대가 된다
input graph에서 negative weight cycle은 없다고 가정한다

이제 apsp의 output을 보자
output은 n x n matrix로 최단경로를 나타내는
matrix를 반환한다
l(i, j)는 source i에서 j로 가는 최단거리를 들고있는 matrix이다
그다음 Predecessor를 저장하고있는 matrix도 함께 저장한다
만약 i와 j가 같다면 predecessor(i, j)의 값은 nil
i, j가 없는 경로여도 nil을 저장한다
만약 i, j 경로가 input graph G내에 존재한다면
π(i, j)는 j의 바로 앞 vertex를 담고있다

이제 Input과 output을 함께 살펴보자
input으로는 위와같이 오각형 모양의
그래프 G가 있고 오른쪽 3개의 Matrix가 있다
W는 edge들의 weight matrix
L은 최단거리 matrix
π는 precedessor matrix이다
앞에서 봤듯이 row가 source, column이 destination이다
따라서 대각선은 각 Matrix마다 대각선 부분은
자기 자신에서 자기 자신으로 가는 경우가 된다

그렇다면 apsp를 구할 수 있는 방법은 어떤게 있을까?
가장 단순하게는 이전까지 배웠던 sssp 알고리즘들을 이용하는 방법이 있을 것이다
sssp를 구하는 알고리즘들을 모든 vertex에 대해서 구하도록 해주면된다
sssp를 구하는 대표적인 알고리즘인
다익스트라를 이용해서 구해보자
다익스트라 알고리즘을 모든 vertex에 대해서
여러 번 수행하면 된다
단, egative-weight edge가 없을 때만 다익스트라를
적용 가능하다는 것을 기억하자
minimum priority queue를 사용했을 때 sssp를 구하는
다익스트라 알고리즘의 시간복잡도는 O(V+E)log V)가 되고
모든 Vertex에 대해 이를 수행해주면
O(V (V+E)log V)가 된다
만약 그래프에서 가능한 모든 edge를 다 잇는다고하면
엣지는 V제곱에 bound가 되고
따라서 time complexity는 O(V세제곱 log V)가 된다

그 다음은 벨만포드 알고리즘을 이용해 구해보자
만약 negative weight edge가 있다면 다익스트라를 못쓰기때문에
벨만포드를 이용해야한다
다익스트라를 이용하는 방식과 동일하게
모든 vertex를 source로 지정하면서
여러번 벨만 포드 알고리즘을 수행해주면된다
벨만포드 알고리즘이 다익스트라보다 느리고
벨만포드로 sssp를 구할 때는 O(VE)만큼이 소요된다
따라서 모든 vertex에 대해서 벨만포드를 수행하면
O(V제곱 E)만큼의 시간복잡도가 되고
E는 V제곱에 바운드가 되므로 총 time complexity는
O(V네제곱)이 될 수 있다
이제 matrix를 이용해서 구할 수 있는
다른 방법을 알아보자

기본적으로 행렬 연산을 사용해서 구하는 방식은
dynamic programming(dp)를 사용하는 방식이다

최적해를 구하기 위해 구조를 세워보자
path p는 vertex i에서 j로 가는 최단거리이다
그러고 p는 최대 r개의 edge를 지난다고 가정하고
negative-weight cycle이 없다고 가정하자
만약 i = j라면 p는 0이 된다
만약 i가 j와 다르다면 몇 가지 경우로 분류가 되는데
vertex k를 도착지 j의 바로 앞에 오는 vertex라고 가정해보자
그렇다면 i에서 k로 갈때 최대 r-1개의 edge가 있을 것이다
그리고 k에서 j로 가는 edge는 1개가 될 것이다
따라서 제일 마지막의

이 식이 나오게 된다

이전의 다익스트라와 벨만포드 알고리즘을
증명할 때 사용했던 Lemma를 다시 사용한다
어떤 Path가 shortest path라면 그 path의 subpath도
shortest path가 된다는 것이다


위 l를 i에서 j로 가는 path의 최단거리이며 최대 r개의 edge를 갖고있는 것을
나타낸다고 정의하자
즉, 최대 r개의 edge만을 사용해서 i에서 j로 가는 최단경로를 말하는 것이다
Base Case는 r = 0일때 인데,
r=0이란 뜻은 edge가 0이고 아무런 edge도 통과하지 않는다는 뜻이다
따라서 자연스럽게 r=0일 때 l의 값도 0이 된다

위에서 state와 base case를 정의했으므로
dp의 step에 따라 이제 recursive case를 정의해보자
case는 총 2개로 나눌 수 있는데
path p가 최대 r-1개의 edge만 갖고있는 경우와
path p가 최대 r개의 edge만 갖고있는 경우로 나눌 수 있다
case1처럼 최대 r-1개의 edge를 가진다고 할 경우에는

위 식이 성립하게 된다
그리고 case2의 경우에는
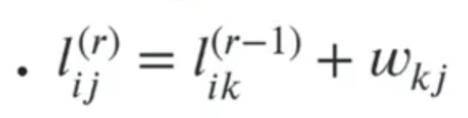
위 식이 성립하게 된다
따라서 위 case들을 종합해보면

의 값은
edge가 최대 r-1개 일 때의 최단경로 값과
i부터 k까지의 최단경로 값 + (k, j)의 weight값들 중 최솟값의
최솟값이 된다
따라서

위와 같은 식이 성립되게 된다
그런데 잘 생각해보면
여기서 r-1개의 edge를 사용하는 (i, j)의 최단경로값은
i부터 k까지의 최단경로 값 + (k, j)의 weight값들 중 최솟값인 오른쪽 값에
포함이 될 수 밖에 없다
따라서

이러한 식이 성립하게 된다

이제 점화식을 작성했으므로
점화식을 바탕으로 Bottom up 방식으로 계산해보자
r=0일 때인 L(0) matrix를 작성해보자
최대 0개의 edge를 통해서 임의의 vertex i에서 j로 갈 수 있는
최단경로를 나타내는데
edge가 0이란 뜻은 갈 수 있는 경로가 없다는 뜻이다
따라서

위와 같은 행렬식이 나오게 된다
그 다음 r=1일 때의 L(1)의 행렬식을 작성해보자
edge를 최대 1개 사용해서 i에서 j까지의 최단경로이다
이를 구할 때

앞에서 구했던 이 식을 이용해보자
최대 1개의 edge를 사용해서
vertex1에서 vertex2로 갈 때의 최단경로를 구해보자
그렇다면 i는 1, j는 2가 되고
k는 1부터 4까지 vertex가 될 수 있다
그렇다면 k=1일 때는

위와 같은 계산식이 나오고
r=0일때의 L matrix와 W matrix를 참고하면
0 + 3 = 3이 된다는 것을 알 수 있다
k=2일 때는

이렇게 되고
결과값은 무한대
k=3일 때는

이렇게 되고
결과값은 무한대
k=4일 때는

이런 계산식들이 나오게 되고
결과값은 또 무한대라는 것을 알 수 있다
그렇다면 위 4가지 식 중 가장 계산값이 작은 값이
최종적으로 i=1, j=2, r=1일 때의 matrix L의 값이 되는 것이다
따라서

이렇게 표현할 수 있고

위에서 계산한 값들을 적용해서
3, 무한대, 무한대, 무한대라고 표기할 수 있다
그럼 3, 무한대, 무한대, 무한대 중 가장 작은 값은 3이므로
L(1) 행렬에서 row 1, column 2인 부분에
3이 들어가게 되는 것이다
다른 위치의 값들도 마찬가지의 방식으로 구할 수 있다
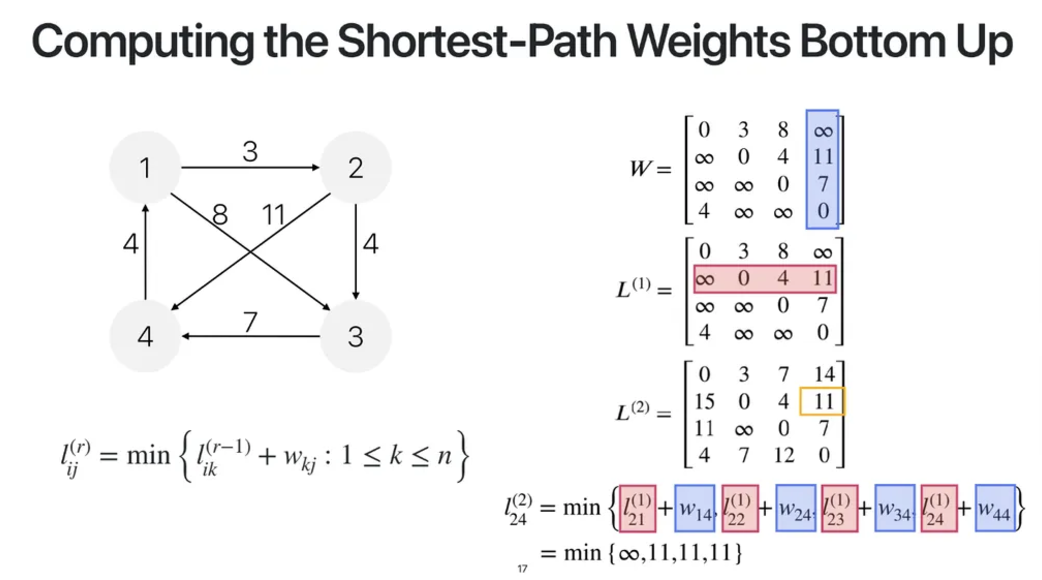
r=2, i=2, j=4일 때의 값도 똑같은 방식으로 구해보자
위의 ppt처럼 계산할 수 있고, 결과는 11이 나온다는 것을 알 수 있다

이런식으로 r=3에 대해서도 구하고
r은 모든 vertex의 개수 -1개까지 될 수 있으므로
n-1개까지 쭈욱 matrix L을 구해준다

한 matrix에서 최단경로를 구하는 pseudo code를 살펴보자
n이 모든 vertex의 개수라고하면
i는 1부터 n까지 for문을 돌고
그 안에서 j는 1부터 n까지 for문을 돌며
i, j의 모든 pair에 대해 연산한다
그러고 i, j의 모든 pair에 대해 1부터 n까지의
모든 k값에 대해 계산하고
그 중 하나로 결과값을 update해준다
이 때 소요되는 time complexity는
n에 대해서 그 안에서 3번 for문을 돌고 있으므로
O(n세제곱)이 된다

그럼 모든 matrix L을 구하는 Pseudo code와
time complexity를 알아보자
L은 n x n 행렬이고
우선 처음은 r=0일 때로 L을 설정해준다
그 다음 r을 최대 될 수 있는 값인 n-1까지 loop를 돌리고
행렬 M을 처음에는 무한대로 초기화해준다
그 다음 위에서 봤던 EXTEND-SHORTEST-PATHS 알고리즘을 수행해주고
그렇게 나온 matrix M을 L에 할당해준다
이렇게 하면 EXTEND-SHORTEST-PATH의 time complexity가
위에서 봤듯이 O(V세제곱)이 되는데
1부터 n-1까지 다시 loop을 돌리므로
O(V네제곱)에 bound된다
time complexity를 계산해보니
이러한 방법은 다익스트라보다 조금 더 느리게 작동하는 것을 알 수 있다
따라서 이렇게 행렬을 이용해서 구하는 방식에서
조금 더 속도를 개선할 수 있는 방법을 알아보자

위에서 봤던 L의 min값을 구하는 과정을 유심히 봤다면
이 과정이 행렬곱을 구하는 과정과 매우 유사하다는 것을 눈치챘을 것이다
따라서 행렬곱 계산을 차용해서 operation을 수행해주려고한다

이런 표기식이

을 나타낸다고 정의하자
그렇다면 r=1일 때는

이렇게 작성할 수 있고
r=2일 때는

이렇게 작성할 수 있는데 L(1)을 위에서 구했던 값으로 대입하면

위와 같이 표기할 수 있다는 것을 알 수 있다
여기서 W제곱은 W를 두번 곱했다는 뜻이 아니다
W를 활용하는 어떤 우리가 정의해준 dot 연산에서
W가 두번 들어갔다는 뜻이다
이에 따라 r = n-1이 된다면

위와같이 나타낼 수 있는 것을 알 수 있다

실제 r=0일 때의 L(0)과 W matrix를 곱해서 L(1)을 구해보자
하지만 위 ppt에서 계산 결과를 보면 알겠지만
L(0) * W = W가 될 수 밖에 없다
따라서 L(1)은 W 행렬과 동일할 수 밖에 없게된다
따라서 L(2) = L(0) * W * W인데 L(0) * W가 W이므로 W 제곱이 되고
이에 따라 L(n-1)은 W(n-1)제곱과 동일해진다
그렇다면 그냥 W를 n-1번 곱해주면 되는거 아닐까?
그럼 time complexity가 O(n 네제곱)이 되는데 과연 이게 최선일까?

행렬곱 연산은 반드시 순서대로 할 필요가 없다고 한다 -> associative하다
이게 뭐 .. 2의 지수승으로 뛰면서 계산이 가능하다고 한다
(정확히는 나도 잘 .. 이해가 ...ㅎㅎ 안돼 ㅠ..)
아무튼 그래서 r = n-1까지 계산을 할 때
1, 2, 3, 4, ..., n-1 이렇게 하나씩 다 해주는게 아니고
2, 4, 8, 16, ... 이렇게 점프하면서 계산을 할 수 있다고 한다
따라서 이를 정리하면

이렇게 계산식을 정리할 수가 있다
vertex i에서 j로 가는 path가 simple path이기 때문에
최대 n-1개의 edge를 가질 수 있다
그런데 n-1보다 edge를 더 사용했을 때
더 짧은 path를 구할 수가 없다
왜냐햐면 i에서 j로 가는 path는 이미 simple path이기 때문이다
따라서 n의 값이 증가해도 결국 n-1보다 커지는 것에 대해서는
모두 값이 n-1을 가지는 것과 똑같아진다고 한다
어차피 실제 최단거리는 많이봤자 n-1개의 edge만을
가질 수 있기 때문에, n을 증가시켜봤자 더 짧은 거리가
나올 수 없게 된다
따라서

이렇게 나타낼 수 있다고 한다
(저도 이해가 잘 안됩니다 ㅎㅎ,, 그냥 그렇다고 합니다)
그래서 이렇게 좀 더 효율적인 방법으로 L의 값을 찾는
pseudo code를 살펴보자

좀 더 빠르게 처리하는 faster apsp방식의
pseudo code이다
n x n matric로 L을 세팅하고
최초 L는 W와 동일하게 초기화한다
그리고 r은 1로 초기화해준다
그 다음 r을 2의 지수승만큼 증가시켜준다
그러고 r이 n-1보다 작을 때까지
EXTEND-SHORTEST-PATH를 실행시킨다
그러고 L = M으로 세팅하고 다시 돌아간다
이렇게 되면 time complexity가
O(n 세제곱 * log n)만큼 돼서
기존에 비해서 조금 줄었음을 확인 할 수 있다

위 Exercise를 바탕으로 실제 코드를 작성해보자
코드를 작성하면서 중요한 것은 precedessor matrix를 저장하는 것이다
이렇게 해야 나중에 저장하면서 복구가 가능해지기 때문이다