본 게시글은
서울대학교 데이터사이언스대학원 이상원 교수님의
데이터사이언스 응용을 위한 빅데이터 및 지식기반시스템 강의를
학습을 목적으로 재구성하였습니다
이번 시간 강의는 DBMS에서
Analytic Function과
Oracle에서의 Tree Traversal 내용에 대해 다뤘다
하지만 갑자기 교수님이 진도를 폭주하셔서
ppt slide가 굉장히 많기 때문에
Tree Traversal 내용은 다음 게시글로 옮기고
이번 게시글에는 Analytic Function만 정리해보려고한다
한 개 한 개가 그냥 function에 대한 예시가 많아서
최대한 핵심만 담아보려고한다

Analytic Function이란
요즘 대부분의 DBMS에서 제공하는 기능이다
SQL이 개발된 이후에
가장 좋은 기능이라는 말도 있다,,고한다

Analytic Functions은 위스콘신 대학교의
DB그룹에서 가장 최초로 개발했다고한다
그러다가 위와 같은 과정을 거치면서 발전했다고한다
ISO/ANSI에 채택되기는 굉장히 힘든데
좋은 성능때문에 빠르게 채택이 된 케이스라고한다

이게 Sorted Relational Query Language라고 하는
Analytic Function의 논문이다
교수님께 해당 논문이 매우 잘쓴 논문이라고 하셨는데
노란색 박스 부분이 해당 논문의 핵심들을
잘 정리한 부분들이라고 한다
지금까지 우리가 DBMS에서 relation을 배울 때
tuple의 순서는 중요하지않다고 배웠다
왜냐하면 relation은 tuple들의 set이었기 때문이다
하지만 위 논문에서는 ordered data를 대상으로
분석을 해야하는 경우가 있다는 것을 제안했다
이를 sequence data라고 정의했다
따라서 sorted relational query language를 제안했고
따라서 sequence를 sorted relation 형태로 만들어
이를 query language로 확장했다

business operations에서는 흔한 질문이지만
SQL 입장에서는 처리하기 쉽지 않은 질문들이 있었다
위 예시를 살펴보면
각 지역별 TOP10 영업사원의 랭킹이라던가
특정 시대(?)와 대비하는 질문이라던가
다른 단계에서 비교를 요구하는 질문들이 있다

그렇다면 위에서 봤던 까다로운 질문들을
우선 SQL로는 어떻게 처리할 수 있는지를 살펴보자
작년의 sales와 올해의 sales를 비교하는 쿼리를 수행한다고해보자
그렇다면 우선 위와같이 view를 만든다음
해당 view를 바탕으로 self join을 해서
쿼리를 작성할 수는 있다

이 이동 평균에 대한 예시도 마찬가지이다
이걸 기존의 SQL로 어떻게 표현하냐하면
view를 만든뒤 그 view를 이용해서
self-join을 해준다고한다
이렇게 해당 질문들은
기존 SQL로는 표현하기 어려운 점들이 있다

Analytic Function들을 사용하면 좋은점이다
뭐.. 당연히
쿼리 수행도도 높아지고 개발자의 생산성도 높아지고.. 할 것이다

Analytic Function은 굉장히 많은 형태의
함수들이 제공되고있다

Analytic Function에서 아주 중요한 개념인
Key Concepts에 대해서 살펴보자
첫 번째는 Second-Pass Grouping인데
2차 그룹핑을 의미한다
두 번째는 partition으로
데이터를 그룹화하는데
group by처럼 row 개수가 줄어드는 것이 아닌
모든 row에 대해서 연산하는 함수이다
세 번째는 ordering인데
partitioning과 함께 row를 정렬할 때 사용된다
마지막으로는 window인데
어떤 연산의 대상이 될 구간을 지정할 때 사용된다

위는 second pass grouping에 대한 예시이다
빨간색으로 작성된 부분이 Analytic Function 부분인데
이외에 기존 쿼리에도 GROUP BY가 있는 것을 알 수 있다
우선 처음에는 해당 GROUP BY를 기준으로
job, deptno를 grouping을 해준다
그럼 각 job과 deptno별 sal의 합이 나올텐데
이를 다시 job으로 grouping을 한 다음
sal의 합을 기준으로 순위를 측정하고
그걸 s2로 표기해달라는 쿼리이다
그럼 각 job 내부에서
연봉에 대한 순위가 매겨지게 되는 것이다
그러고 이걸 job과 s2를 기준으로 정렬을 해준다
Analytic Function도 그렇고
그냥 일반 SQL에서도 order by는
항상 마지막에 나온다고 생각하면 된다

Analytic Function의 기본 문법이다
그리고 Analytic Function에는 3개가 정말 중요한데
1. Partitioning
2. Ordering
3. Windowing
이라고 한다
이 3개는 반드시 외워두라고하셨다

이제 ORDER BY와 RANK를 보자
위 쿼리는 partition이 없어서 grouping을 수행하는 쿼리는 아니다
단지 sal을 기준으로 order by를 한 다음
이를 등수를 매기는 쿼리이다

이를 Analytic Function을 쓰지 않고
그냥 SQL로 한다면 위와 같이 표현할 수 있다고 한다
subquery를 사용하는 방식인데
자기보가 월급이 높은 사람들의 수를 구해서
rank라는 등수 attribute로 나타내는 방식이다

위의 SELECT 구절에서 사용된
Analytic Function의 ORDER BY와
아래의 ORDER BY는 다르다
rank를 기준으로 처음에 order by가 되더라도
아래의 ORDER BY 때문에
EMPNO를 기준으로 다시 재정렬돼서 출력된다

partitioning에 대해서 살펴보자
위 쿼리는 DEPTNO를 기준으로 grouping을 한 다음
그 안에서 SAL을 기준으로 order by를 한 쿼리이다
한 마디로 같은 부서 내부에서
월급 기준으로 몇 등인지를 계산하는 것이다

위 쿼리는 Analytic Function을 여러 개 쓴 쿼리이다
위 쿼리를 보면
SAL을 기준으로 내림차순으로 정렬하고
그 다음 HIRE_DATE를 기준으로 오름차순으로 정렬한 뒤
마지막으로 ENAME을 기준으로 다시 정렬한다

월급을 기준으로 TOP 10 이내에 드는 row들만
출력하고싶었다
그래서 Analytic Function을 WHERE절에 쓰게되면
에러가 뜬다고 한다
Analytic Function은 반드시
SELECT절에만 사용이 가능하다고한다

그래서 RANK가 10 이내인 row 출력은
위와 같이 하는게 맞다고 한다

그렇다면 RANK를 할 때 동점자에 대해서
어떻게 처리하는지 알아보자
Analytic Function에서 등수를 매기는 함수는
RANK, DENSE_RANK, ROW_NUMBER
이렇게 3개가 있는데 각각 미묘하게 다르다
첫번째 RANK는 우리가 흔히 알고있는 등수이다
그래서 위 slide를 보면
공동 2위가 있으면 다음 순위는
3위가 아닌 4위가 나오는 것을 볼 수있다
반면에 DENSE_RANK는
동점자에게는 같은 순위를 부여하지만
순위를 건너뛰지않고 gap 없이
바로 다음 순위로 가는 것을 볼 수 있다
마지막으로 ROW_NUMBER인데
동점자를 따로 구분하지않고
무조건 고유한 번호로 순위를 매기는 것을 확인할 수 있다

그렇다면 ROWNUM과 ROW_NUMBER는 어떻게 다를까?
위 쿼리를 보면 SELECT에
ROWNUM이 있는 것을 볼 수 있는데
ROWNUM은 어떤 정렬에 의한 순서가 아닌
단순히 입력된 순서로 순번이 매겨지는 구조이다
따라서 우리가 의도한 순서와 다를 수도 있고
정확한 어떤 기준에 따른 순서가 나오지 않는다
반면에 ROW_NUMBER은 정확한 기준에 의해 정렬된 순번으로
위 예시의 경우 SAL에 의해 내림차순으로 정렬됐다

NULL 값이 있을 때의 정렬 기준이다
보통 NULL값은 Highest로 분류가 되어서
위 예시에서도 NULL인 경우 가장 위에 정렬되는 것을 확인할 수 있다
여러 개의 NULL값이 있는 row가 존재할 때
RANK, DENSE_RANK, ROW_NUMBER의
각각의 차이도 확인해보면 좋을 것 같다

NULL FIRST와 NULL LAST는
NULL 값을 어디에 정렬할 지 명시하는 것이다
위 예시의 경우 각각
RANK, DENSE_RANK, ROW_NUMBER 모두에
NULL이 가장 마지막에 오도록 명시해줬다
따라서 위에 NULL이 가장 마지막에 오고
순번도 그에 맞게 매겨지는 것을 확인할 수 있다

이젠 PARTITION BY에 대해서도 살펴보자
위 쿼리는 우선 DEPTNO를 기준으로
grouping을 한 다음
그 내부에서 SAL을 기준으로 내림차순 정렬을 한 것이다
그러고 SAL을 기준으로 순위를 매긴 것이다
따라서 위 slide를 보면
DEPTNO을 기준으로 묶여있고
그 안에서 SAL에 대해 순위가 출력된 모습을 볼 수 있다

그렇다면 여러 개에 의해 Partition되면 어떻게 될까?
위 예시를 보면 DEPTNO와 JOB
2개를 partitioning했다
그럼 DEPTNO와 JOB이 둘다 같은 것을 기준으로
분류가 되는 것을 확인할 수 있다
따라서 위처럼 SAL을 기준으로 ORDER BY를 하면
순위가 매겨지게 되는데
DEPTNO + JOB이 동일한 것을 기준으로
순위가 측정되는 것을 확인할 수 있다

그렇다면 위 예시처럼
다른 row에서 Analytic Function을 여러 개를 사용해서
PARTITION BY와 ORDER BY를 수행하면 어떻게 될까?
결론적으로는 여러 개의 analytic function을 이용해서 연산해도
결과는 결국 독립적으로 수행된다
따라서 위 예시에서는 DEPT_RANK는
DEPTNO에 대한 partition + order by인데
이를 기준으로 순위가 매겨진 것을 볼 수 있고
JOB_RANK는 JOB를 기준으로
partition + order by인데
이를 기준으로 순위가 매겨진 것을 볼 수 있다
그리고 TOTAL_RANK의 경우
partition 없이 단순히 SAL을 기준으로
내림차순 정렬을 했는데
이를 기준으로 순위가 측정된 것을 확인할 수 있다

그렇다면 위 예시처럼
aggregate function과 analytic function을
함께 사용한 예시를 살펴보자
위는 DEPTNO로 group by를 한 다음
이를 기준으로 각 DEPTNO별 SAL의 평균값을 구했는데
이 때 구한 평균값을 바탕으로 순서를 매겨
이를 DEPT_RANK에 표기한 것이다
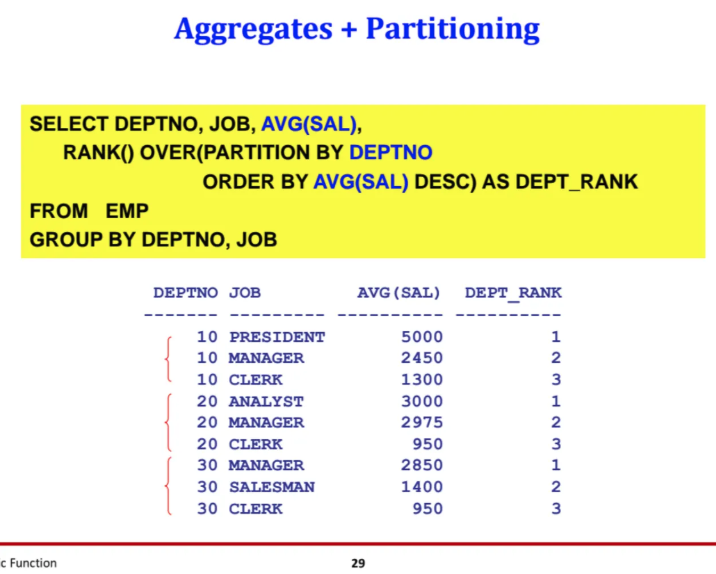
aggregate와 partitioning이 함께 된
사례에 대해서도 살펴보자
우선 DEPTNO와 JOB을 기준으로 group by를 하고
여기서 각 DEPTNO+JOB별 SAL의 평균값을 구했다
그런 다음 다시 DEPTNO을 기준으로
grouping을 수행하고 해당 AVG(SAL)을 정렬해서
DEPT_RANK로 순서를 매겼다
그럼 위 slide와 같이 DEPTNO이 같은 것에 대해서만
AVG(SAL)값을 기준으로 순위가 매겨지는 것을 볼 수 있다

우선 AVG(SAL) OVER() 구절에서
OVER안에 아무 것도 없으면
전체 행을 대상으로 연산을 수행하다는 것이다
따라서 위 구절은 그냥 전체 SAL의 평균을 구하는데
소수점은 반올림을 해준다
그런 다음 아래에서
각 row의 SAL과 평균에서 반올림한 SAL의 차이를
DIFF로 정의해서 출력해준다

위 예시는 DEPTNO별로 grouping한 다음 SAL의 평균을 구하고
본인의 SAL과 위에서 구한 SAL 평균과의 차이를
DIFF로 나타낸다
여기까지 그냥 대표적인 analytic function들의
기본적인 syntax을 알아봤다
계속 더알아보자(?)

Percentiles에 대해서 알아보자
Percentiles는 우리나라말로 백분위수라고 하는데
쉽게 말해서 그냥 백분위를 구하는 거라고 생각하면 된다
기본적인 syntax는 위 slide에 나온 것과 같은데
PERCENTILE과 그 연산 방식을 설정한 후
괄호 안에 비율을 적어주는데
당연히 비율이라서 0에서 1사이의 값이어야한다
그리고 어떤 column을 기준으로
백분위 연산을 수행할 것인지를 지정해준다
위 쿼리를 살펴보면
PERCENTILE_CONT(0.5)와
PERCENTILE_DISC(0.5)
두 가지를 수행하고 있는데
이는 똑같이 percentile 연산을 수행하는 것이지만
연산 방식이 조금씩 다르다
PERCENTILE_CONT 뒤의 cont는
continuous의 약자로 연속형이라는 뜻인데
계산된 위치를 기준으로 선형 보간법을 사용해
실제로 없는 값도 생성하는 방법을 말한다
반대로 PRECENTILE_DISC는 discrete의 약자로
이산형 방식으로 실제 데이터 중에서
가장 가까운 값을 하나 선택하는 방식을 말한다
따라서 두 방식의 계산 방법 차이 때문에
continuous하게 하면 1550이
disc하게 하면 1500이 나오는 것을 알 수 있다

Percentiles 연산은 group by와 함께 사용할 수 있다
위 예시는 DEPTNO을 group by 시키고
SAL로 각각 percentile 연산을 수행하였다
fraction이 0.5이기 때문에 중앙값이 된다

위 쿼리는 SAL을 정렬해서 MEDIAN에 중앙값을 구하고
DIFF로 각 row의 SAL과 위에서 구한 중앙값의 차를 나타냈다

PERCENT_RANK 연산에 대해서 알아보자
위 예시에서 PERCENT_RANK(2500)라고 있으면
2500이 sal column에서 몇 퍼센트 위치에 있는지를 반환해준다
따라서 결과에 따르면 0.64정도에 위치해있는다고 한다

그럼 좀 더 복잡한 위 쿼리에 대해서도 알아보자
PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL ASC) as PR
위와 같이 되어있는 부분이 있는데
이는 우선 DEPTNO를 기준으로 grouping을 한 뒤
SAL을 오름차순으로 정렬을 하는데
여기서 SAL을 grouping된 DEPTNO 내부에서
몇 번째 위치에 있는지 비율로 계산한 값을 반환한다
따라서 위 예시를 보면
DEPT 10의 경우
각각 0, 0.5, 1 이렇게
순서대로 비율이 측정되어있는 것을 알 수 있다

위 예시도 한 번 살펴보자
크게 바뀐건 없고 percentile과 percent_rank를
같이 출력한 예제이다
이제 마지막인
window function에 대해서 알아보자

Ntile은 window function의 함수 중 하나이다
Ntile은 row를 n개의 동일한 크기 혹은 비슷한 크기의 bucket으로 나눈 뒤
각 row가 어떤 bucket에 포함되는지를 알려주는 함수이다
위 예시를 통해 자세하게 살펴보자
첫 번째 줄에는
NTILE(2) OVER(ORDER BY SAL DESC) AS NTILE2
과 같이 되어있다
이는 전체 row를 2개의 bucket으로 나누는데
그 나누는 기준을 SAL의 내림차순으로 정렬한 뒤
나누겠다는 뜻이다
그 아래는 그럼
NTILE(4) OVER(ORDER BY SAL DESC) AS NTILE4
와 같이 되어있는데
SAL로 내림차순 정렬을 한 뒤
4개의 비슷한 크기로
(동일하게는 나눌 수가 없어서)
나눈 결과를 반환해달라는 뜻이다
마지막같은 경우는 10개의 bucket으로 나눠달라고 했는데
총 row가 14개이기 때문에
4번째 bucket까지는 2개씩 row를 갖다가
이후에는 1개씩 row를 갖는 모습을 확인할 수 있다

window function의 기본 syntax이다
window function이 앞에 들어오고
괄호 안에는 argument
OVER 뒤에는 analytic clauses가 들어간다
한 가지 기억해야할점은
window를 사용하기 위해서는
반드시 ordering이 되어있어야한다
window는 순서화되어있는
tuple들의 집합을 뜻하기 때문이다

window function이란 집계함수처럼 동작하지만
전체 그룹이 아닌 행 단위로
지정된 window 안에서 계산이 수행되는 함수이다
한마디로, 각 행에 대해
주변 이웃들과 함께 계산되는 것이다
window는 상대적인 tuple들의 집합이라는 뜻이다
위의 예시를 잘 살펴보자
sliding window라는 개념이 나온다
sliding window란 현재 row를 기준으로
window가 이동하면서 이웃 row들과 함께 계산하는
그 범위를 뜻한다
위 slide의 그림처럼 현재 row를 기준으로
계속 내려가면서 window의 범위 내부에 있는
row들끼리 어떤 연산을 수행하는 것이다
따라서 이러한 window는
row들의 ordering이 전체가 되어있어야하고
tuple들이 sorting이 되어있어야한다

위 슬라이드의 쿼리를 한 번 살펴보자
위 쿼리는 running total을 계산하는 쿼리인데
running total이란 지금까지 row들의 전체 총계를 말한다
위 쿼리에서 EMPNO를 기준으로 tuple들을 정렬했다
그런 다음
ROWS BETWEEN UNBOUNED PRECREDING AND CURRENT ROW
라는 절이 나오는데
이는 맨 앞의 행부터 현재 행까지의 누적을 뜻하는
window function이다
SELECT 절에서 SUM(SAL)이
이러한 window function에서의 SUM이 되어서
현재행부터 누적행까지의 총 SAL의 합이
ACC_SAL로 출력이 되게 되는데
이때 SUM(SAL)이 단순 aggregation function으로 취급되지 않는 이유는
뒤에 analytic function이 나왔기 때문이다

두 번째 예시를 살펴보자
EMPNO로 sorting을 시킨 다음
1 PRECEDING과 1 FOLLOWING으로
window를 지정해줬다
이는 현재 행을 기준으로 1개의 이전 행과 1개의 다음 행까지를
sliding window로 삼겠다는 뜻이다
그런데 위 ppt의 예시에서
가장 첫번째 행인 SMITH의 경우
1 PRECEDING row가 없으므로
그냥 자기 자신과 다음 행까지만 계산이 된 것을 볼 수 있다
마찬가지로 마지막 행인 MILLER도
1 FOLLOWING row가 없기 때문에
이전의 FORD와 자기 자신까지만
계산이 된 것을 확인할 수 있다

앞에서 window는 반드시
tuple들이 sorting이 되어있어야한다고 했다
위 쿼리의 경우 sorting이 되지 않았는데
이는 ORDER BY가 되어있지않아
에러를 띄우는 것을 확인할 수 있다

이번에는 sliding window에서
physical offset과 logical offset에 대해서 알아보자
physical offset은 이전 슬라이드에서의 쿼리처럼
ROWS BETWEEN과 같은 구문을 사용하는데
이는 정말 현재 행을 기준으로
앞 뒤로 행의 개수로 sliding window를 설정한다
반면에 logical offset은
RANGE BETWEEN과 같이 사용하는데
이는 행의 개수가 아닌
실제 값을 기준으로 sliding window를 구분하는 것이다
위 예시에서
100 PRECEDING AND 200 FOLLOWING 이라고 한다면
EMPNO 기준 current row가 MARTIN이라면
EMPNO가 7654-100=7554이상부터
7654+200=7854이하까지가
sliding window가 되는 것이고
MARTIN row의 ACC_SAL에는
해당 값들의 합이 들어가게 되는 것이다

이는 Physical offset과 logical offset의 차이를
보여주는 예시이다
위 쿼리에서는 ROWS도 RANGE도 둘다
처음부터 현재행까지의 합을 구하도록 해줬는데
왜 빨간박스 부분의 값이 달라질까?
첫번째 physical offset인 row는
행의 개수를 기준으로
현재 행보다 이전의 행의 모든 합을 구하는 것이다
따라서 해당 WARD의 row에서는 그냥
SMITH부터 WARD까지의 SAL의 합을 구한 것이다
그래서 4100이라는 결과가 나오게 됐다
반면에 logical offset인 row는
행의 개수가 아닌 "값"을 기준으로
현재 "값"보다 이하인 값을 가진 row의 모든 합을 구하는 것이다
따라서 WARD와 SAL이 같은 다음 row인
MARTIN row의 1250도 함께 합산이 되는 것이다
따라서 SMITH부터 MARTIN의 SAL까지 더해져서
5350의 값이 RANGE_ACC에 나오게 되는 것이다

그렇다면 이제 기본값인
default 값에 대해서 알아보자
위 쿼리에서 첫번째 analytic function에서는
SUM(SAL) OVER()와 같이 적혀있다
여기에는 ORDER BY도 없고 WINDOW를 지정하는 syntax도 없으므로
그냥 단순히 전체 테이블의 총 합을 계산해서 적어준다
따라서 29025가 모든 row에 적히게 되는 것이다
반면에 아래의 analytic function에는
SUM(SAL) OVER(ORDER BY SAL)이라고
ORDER BY는 명시되어있지만 WINDOW를 지정하는 syntax가 없다
이는 따라서 default window frame을 지정해주는데
이 default가 바로 처음부터 현재까지 누적 행인
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
가 되는 것이다
따라서 오른쪽과 같이 누적 합계가 나오게 된다

partitioning과 window가 합쳐진 쿼리를 살펴보자
DEPTNO를 기준으로 grouping한 뒤
EMPNO를 기준으로 sorting하고
앞 1, 뒤 1씩 rows를 기준으로 SAL의 합을 구한다
그럼 DEPT가 10인 것을 보면
CLARK는 이전이 없으므로 2450 + 5000 = 7450이 되고
KING은 위아래로 다 더한값인 8750이 되고
마지막 MILLER는 뒤가 없으므로 5000+1300=6300이 되는 것이다

지금까지는 window가 값을 기준으로
RANGE를 통해 나눠지는 것을 보았다
하지만 이는 시간을 기준으로도 나눌 수 있다
위 슬라이드에서는 HIREDATE를 기준으로 sorting했는데
6개월 이전인 row와 6개월 이후인 row들을
window로 삼아서 SAL의 평균을 계산했다

이후 추가적인 함수들을 몇몇개 알아보고
이번 수업 정리를
(드디어) 마무리하려고한다
FIRST_VALUE와 LAST_VALUE가 있는데
window 범위 안에서 정렬된 순서로
가장 첫번째 SAL이 FIRST_VALUE,
가장 마지막 SAL이 LAST_VALUE가 된다

그다음으로 RATIO_TO_REPORT 함수는
전체 합계에서 차지하는 비율을 계산해주는 함수이다
위 slide에서 SAL/SUM(SAL)의 값과
RATIO_TO_REPORT(SAL)의 값이 동일한 것을 볼 수 있다

정말정말 마지막,,
LAG와 LEAD를 알아보자
LAG는 current row보다 이전 행에 대한 정보를 가져오는 함수이고
LEAD는 이후 행에 대한 정보를 가져오는 함수이다
LAG(SAL, 3)과 같이 들어갔다면
나보다 3개 이전의 row의 SAL의 값이고
LEAD(SAL, 3)이면
나보다 3개 이후의 row의 SAL의 값이다
만약 아무것도 없이 LAG(SAL)처럼 있다면
바로 직전의 row를
LEAD(SAL)이라면 default로
바로 직후의 row를 가져온다