본 게시글은
서울대학교 데이터사이언스대학원 이상원 교수님의
데이터사이언스 응용을 위한 빅데이터 및 지식관리시스템 수업을
학습을 목적으로 재구성하였습니다

이제 본 수업의 마지막 챕터인
16. Transaction Management이다
이 챕터는 크게 Lock Manager와 Recovery Manager로 나뉘는데
이번 시간에는 lock manager를 위주로 배운다
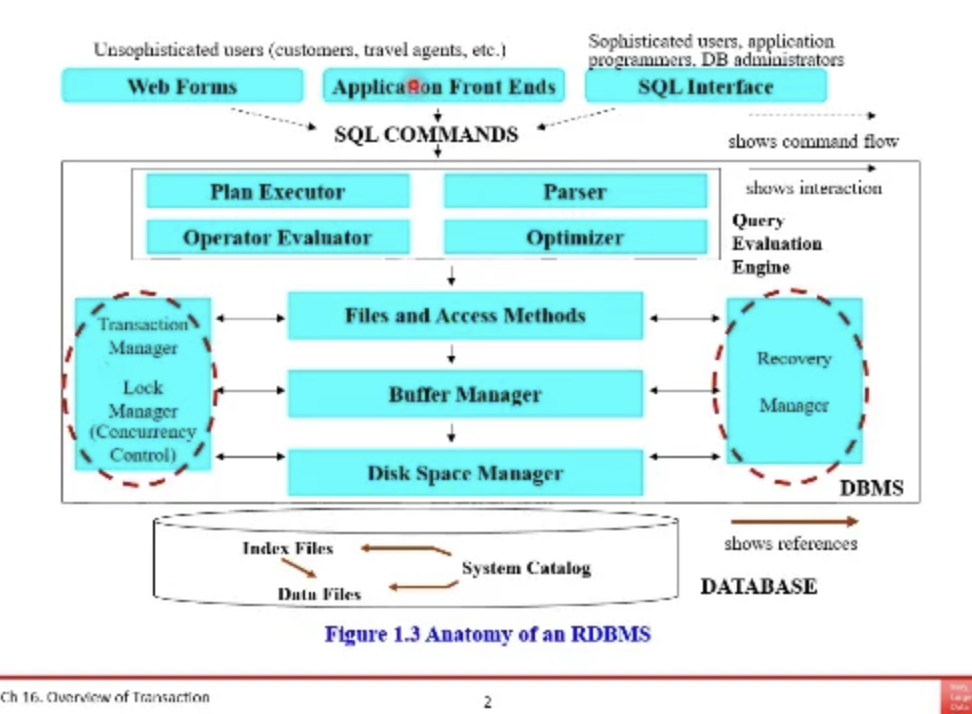
우리가 transaction을 할 때마다 concurrency control도 해야하고
프로그램이 언제 죽을지 모르기 때문에 recovery control도 해야한다
그래서 위 ppt에서 양 옆에 lock manager(concurreny control)
recovery manager가 각각 존재하고있다

위는 transaction sample이다
은행에서 관리하는 스키마 정보인데
결국 transaction들은 DML들의 연속이라고 볼 수 있다
테이블을 읽거나, record를 insert하거나
읽기 연산을 하거나 쓰기연산을 하는
sequence로 바뀌게 된다
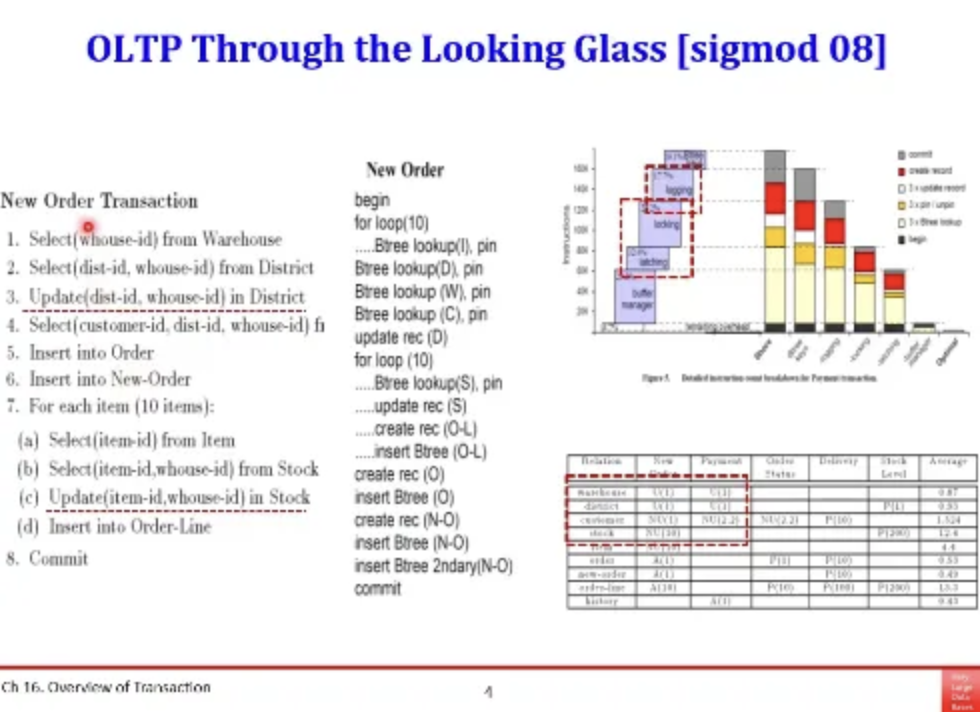
저번 실습에서도 봤던 benchmark의 예시이다
창고가 어디에 재고가 어디에 있고
이런 정보들을 담고 있는 테이블이 9개가 있다
이건 benchmark이긴 하지만 실제 현업에서도
쇼핑몰들은 이러한 구조로 DB의 스키마와 테이블을 구성한다
하지만 실제 쇼핑몰의 경우 여러명의 사용자가
동시에 접속하는 경우가 많기 때문에
concurrency control, recovery 등 작업을 필요로 한다
따라서 해당 DB는 이런 쿼리들을 수행할 때
IO, concurrency control, recovery 등을 위해서
쿼리와 함께 수행하는 작업들이 증가하고
overhead가 발생하게 된다

benchmark의 TPC-C 예시인데
쿼리에 dependency가 존재한다고 한다
다음시간에 해당 내용에 대해서 좀 더 자세히 배운다고한다
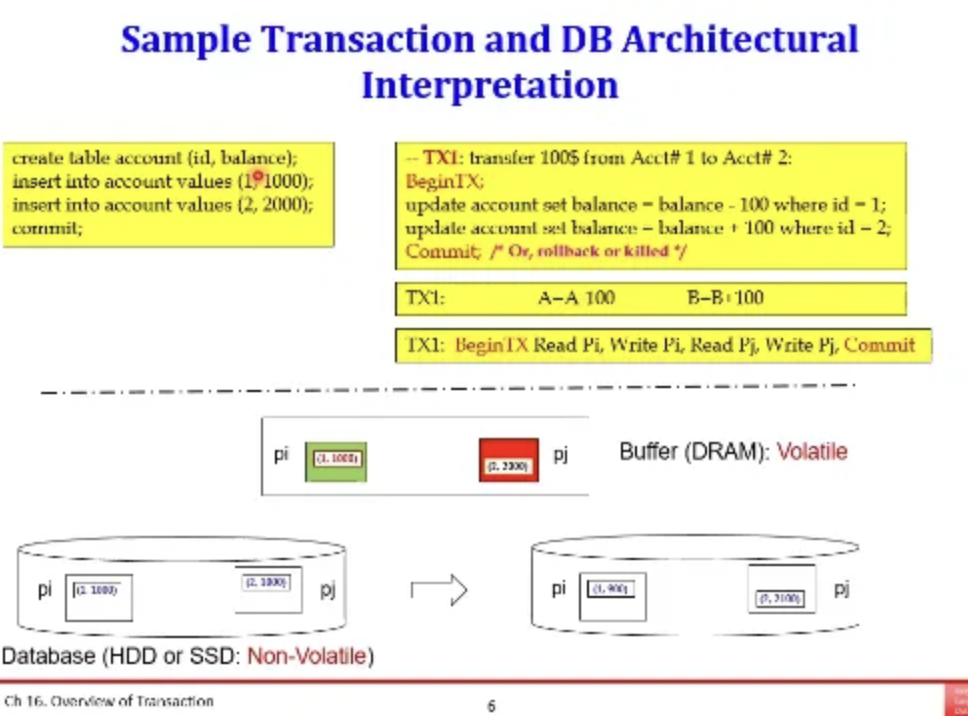
위 transaction 예시를 잠깐 살펴보자
pi table에 (1, 1000) 튜플이 있고
pj table에 (2, 2000) 튜플이 있다
오른쪽은 계좌이체를 하는 transaction이고
record level로 읽기와 쓰기 작업을 수행한다
따라서 위 순서로 transaction을 수행하게 된다면
pi를 먼저 읽은 다음 pi에서 100 뺸 것을 써주고
그 다음 pj를 읽은 다음 pj에서 100을 더해준 것을 써준다
이걸 성공적으로 수행하면 commit을 하는데
그러면 disk에 안전하게 저장되는 것이다
HDD와 SSD는 컴퓨터 전원이 꺼진다고 사라지지 않지만
DRAM은 컴퓨터 전원과 함께 휘발된다
따라서 대부분의 경우는 transaction이 끝까지 수행되지만
예상치 못한 경우게 수행 중에 중간에 죽는 경우가 종종 발생한다
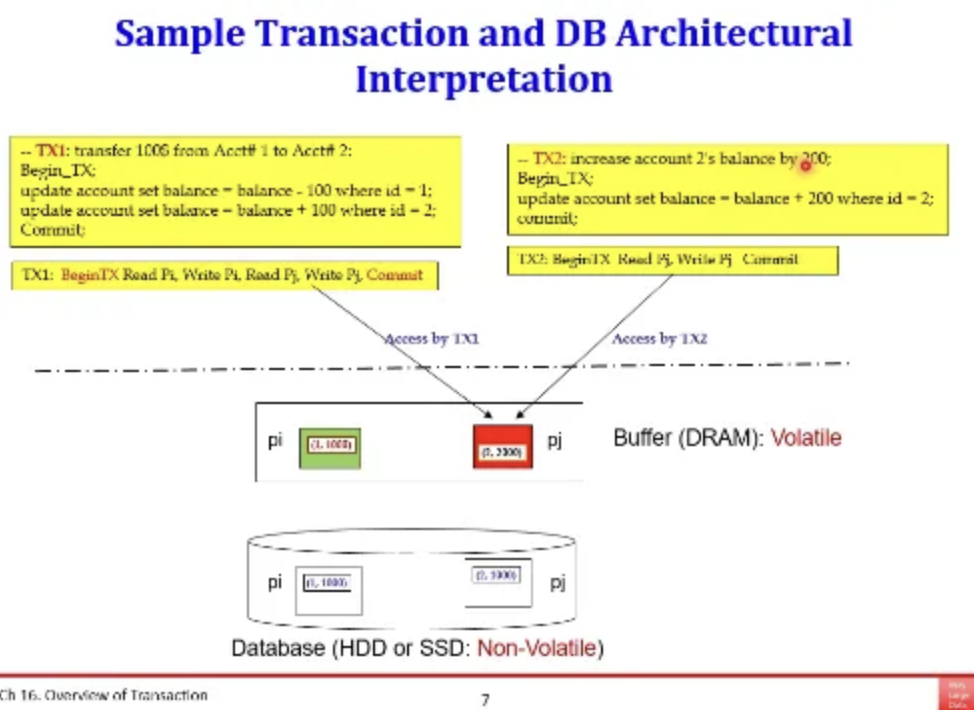
이제 앞의 예시에서 오른쪽 쿼리 하나가 더 추가됐다
계좌에다가 200달러를 더 추가하는 예시이다
그럼 이 두개의 transaction이 같은 시간에 접근하게 되어서
동시에 pj table에 접근하게 된다면 어떻게 될까?
이러한 경우를 concurrency라고 한다
동일한 데이터에 대해서 서로 다른 transaction들이
동시에 접근하려고 하는 경우이다
둘다 읽기만 하면 상관없지만
write가 있을 경우 문제가 생기게 된다

RDBMS에서 핵심 기술을 개발하신 분들이라고한다

깊이있게 공부하려면 이런 책들을 읽어봐야한다

DBMS에서 transaction을 수행할 때는 2가지 위험요인이 있다
1. 컴퓨터는 언제든 죽을 수 있다
2. concurrent하게 접근할 수 있다
이게 기술적으로 컴퓨터에서 돌아가는
DBMS가 관리해야할 두가지 위험 요인이다
file system은 이런 2가지 위험 요소에 대해서
대처가 불가능하다
따라서 DBMS는 2가지 이슈를 다루기 위해서
concurrency control과 recovery control을 제공하고 있다
이러한 기능으로 프로그래머의 생산성이 높아진다
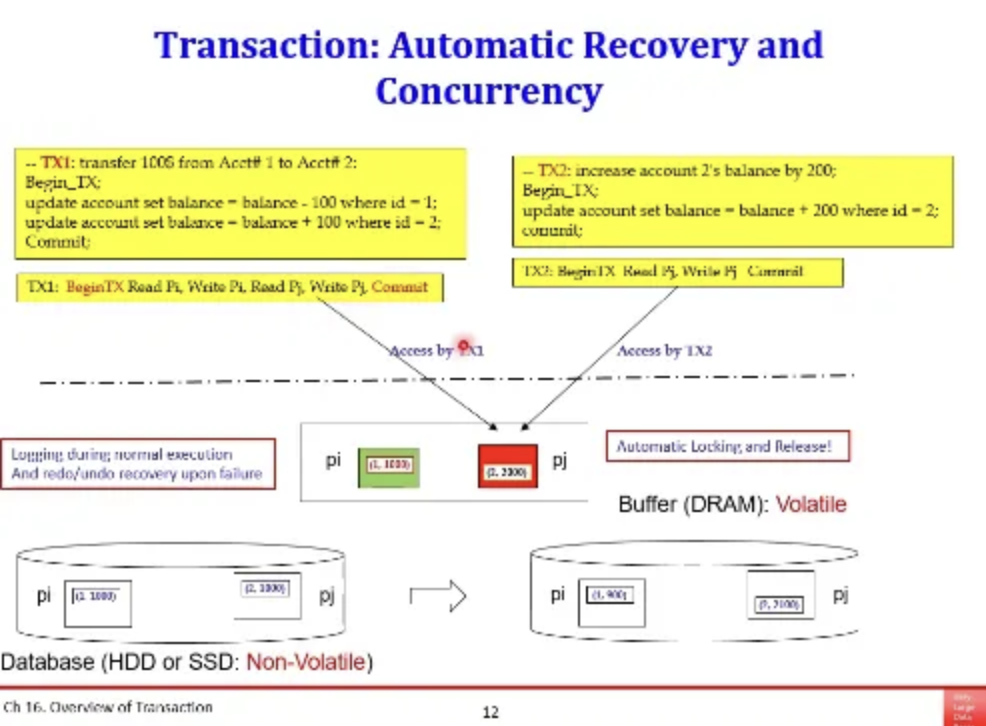
그렇다면 왼쪽 쿼리를 한 번 살펴보자
위 두개의 transaction이 성공해서
pj 테이블을 2100이라는 값으로 고쳤다고하자
그때 프로그램이 죽어서 DRAM에 있던 2100이라는 정보가 날라가면 어떻게 하나?
이럴 때를 위해서 DBMS는
모든 Transaction에 대한 로그를 저장해서 따로 관리한다
pj에 대해서 TX1이 원래 2000이었는데 2100으로 바꼈다고 하자
그럼 이 로그를 캡처해서
DBMS는 이런 로그를 별도로 관리한다
또한 TX1에서 처음 데이터를 읽을 때 DBMS는
pj 테이블에 대해서 automatic하게 lock을 건다
그렇게 해야 나중에 TX2에서 pj 테이블에 접근하는 것을 막을 수 있기 때문이다
이런 상황에서는 pj에 접근하려고 하면
pj에 걸린 lock이 release 될 때까지 기다려야한다

위에서 봤던 lock은 concurrency control에 대한 문제이다
동시성 제어라는 문제에 대해서 locking 방법으로 해결한다
이러한 것들을 isolation시킨다고 말을 하는데
동시에 돌아가는 transaction들을 격리시킨다는 의미이다
DBMS는 automatic하게 Lock을 걸어서
concurrency control을 처리한다

한번 읽어보면 좋은 내용이라고 한다

오늘은 recovery control보다는
concurrency control에 대한 얘기이다
사용자는 각각의 transaction들의 SQL문을 DBMS에 던진다
그럼 DBMS는 각각의 페이지와 레코드에 접근한다
transaction 요청이 들어오면 스케줄러가 go할지 stop할지를 정해준다
이러한 방식으로 동일한 데이터에 접근해도 문제가 없도록 해준다

이번 시간에 우리가 알아야할 것들이라는데
transaction에는 4가지의 프로퍼티가 있다는 것..
이게 가장 핵심인 듯 하다

transaction은 무엇일까
transaction은 기업 입장에서는 잘 정의된 업무의 단위이다
예를 들어서 A 계좌에서 B 계좌로 돈을 보낸다고하면
A 계좌에서 100달러를 줄이고
B 계좌에서 100달러를 추가한 후 커밋한다
DB입장에서는 저걸 수행할 때 여러개가 있겠지만
기업 입장에서는 성공하거나 실패하거나 all or nothing이다
(성공하면 혁명 실패하면 반역..?)
전체가 다 성공하던지 아니면
단 한개도 수행하면 안된다는 것이다
일부만 수행이 되고 나머지는 수행이 안되면 안된다

따라서 transaction은 all or nothing을 만족시켜야한다
아까 transaction에는 4개의 properties가 있다고 했는데
Atomicity, Consistency, Isolation, Durability의 앞글자를 따서
ACID라고 부른다
Atomicity는 원자성으로
중간 쯤 수행이 된다면 다시 원래대로 back할 수 있는 기능을 제공해야한다는 점이고
recovery control과 관련이 있는 특성이다
consistency는 일관성으로
간단하게 말하면 개발자가 transaction의 로직을
SQL로 잘구현을 해야한다는 점으로
기술적인 것과는 거리가 멀다고 한다
isolation은 고립성인데
여러 개의 transaction이 동시에 접근해서 문제가 발생하는 것을 막아준다
concurrency control의 문제이다
마지막 durability는 내구성으로
transaction이 끝나면 그 결과가 시스템에 어떠한 문제가 있더라도
유지가 되어야한다는 것이다
recovery control과 관련이 있다

위에서 설명한 내용을 정리한 것이다

atomicity랑 durability만 예시를 통해서 살펴보자
위 ppt의 transaction을 실행한다고 해보자
pi table의 내용은 disk에 내려가고
pj table를 바꾸려고 하는 순간 시스템이 죽었다고 해보자
이렇게 되면 pi table에서는 100달러가 빠져서 900이 되는데
pj table에는 아직 아무것도 들어가지 않아서 2000 그대로이다
이런 경우가 발생해서는 안되기 때문에
pi table에서도 100이 빠지기 전 상태로 아예 back 시켜야한다
이게 바로 원자성이다
그럼 위 예시에서 다시 pj table에 쓰는 것까지 연산이 다 되었다고 해보자
pj까지 수행이 되었을 때 DRAM에는 반영이 되었는데
disk까지는 반영이 안되는 경우가 있다
왜냐하면 transaction이 끝났다고 해서
바로 disk에 써지는 것이 아니기 때문이다
따라서 이런 경우 어떤 방법을 통해서
시스템이 어떠한 crash가 발생하더라도
수행한 결과를 계속 유지할 수 있도록 해야한다

다음은 Isolation에 대해서 알아보자
concurrency control에 관한 내용이다
현재 상태를 보고 스케줄러가 go or stop을 결정해주는데
사용자 입장에서는 마치 이 DB를 나 혼자서 점유하고있는 것과 같은 환상을 준다
OS의 virtualization과 유사하다

따라서 어떤 Transaction이 수행되다가 중간에 멈추는 경우가 있다
사용자가 멈출 수도 있고
시스템이 어떠한 이유에 의해서 터질 수도 있고
dead lock이 발생할 수가 있다
이런 것들은 UNDO log로 남겨서 원자성을 보장해야한다
durability를 보장하기 위해서도 동일하게 Log를 사용하는데
REDO log만을 남겨서
나중에 시스템 자체는 DRAM에서 disk까지 내려가지 않아도
REDO log를 보고 나중에 Replay를 하면
transaction의 결과를 복원할 수 있기 때문이다

96%의 transaction은 정상적으로 수행이 된다고 한다
그러다가 3%는 사용자가 멈추고
나머지 1%는 dead lock이 발생한다고 한다

transaction과 schedules에 대해서 알아보자
하나의 transaction은 begin, reads, write, commit, abort 등을
연속으로 수행한다
그렇다면 스케줄이란
T1은 A를 읽고 commit하고
T2는 B를 읽고 쓰고 commit하고..
이런 2개의 transaction을 저 순서대로 DBMS에 요청하는데
이게 하나의 스케줄이 된다
중간에 concurrency control을 담당하는 스케줄러가 존재하고
실제로 요청은 저 순서대로 하더라도
실제로 스케줄러가 뱉어내는 스케줄은 바뀔 수가 있다
그런데 상식적으로 생각했을 때
유저가 요청한 순서대로 그냥 처리해주면 되는거 아닌가?
그럼 충돌이 안나는데 왜 굳이 스케줄러를 통해서 순서를 결정할까?
이는 우리의 컴퓨터는 CPU도 짱짱하고 병렬처리도 가능하다
따라서 이런 자원을 사용하면 프로그램의 효율을 높일 수 있는데
그냥 유저가 요청한 순서대로 하면 이 효율을 놓칠 수 있기 때문이다

아무튼 그래서 concurrent는 매우 중요한 문제이다
위 ppt에서 T1과 T2를 잠깐 살펴보자
각각 2개의 계좌에다가 이자를 던져주는 transaction이고
각자의 operation을 동시에 수행한다고 해보자
각자 A에 대한 write를 요청했을 때 go or stop을
스케줄러가 결정해주는 것이다
그런데 이 작업을 수행할 때 반드시 만족시켜야하는 것은
데이터베이스의 최종적인 형태는
T1을 먼저하고 T2를 수행했던지
T2를 먼저하고 T1을 수행했던지
항상 결과가 같아야 한다
설령 2개를 동시에 허용해서 수행시키더라도
마지막 결과는 serial하게 수행하는 것과 결과가 같아야한다

앞에서 말한 T1, T2를 위 3가지의 경우를 한 번 보자
스케줄러가 가장 첫번째 경우로 수행을 했다고 해보자
이렇게 하면 T1 -> T2를 수행한 것과 결과가 같아서 큰 문제가 없다
하지만 두 번째로 수행을 한다면?
이게 끝났을 때는 첫 번째와 다른 이상한 형태의 결과가 나온다
따라서 이런 것은 DBMS가 수행하지 못하도록 막아야한다

T1 -> T2를 처음부터 serial하게 수행하는 것이
첫 번째 수행 방식이다
그 아래에 있는 수행 방식은 순서는 다르지만
결국 serial하게 했을 때와 동일한 결과를 반환한다
따라서 이도 serializable한 schedule이다
DBMS에는 이런 방식으로 스케줄을 생성해야한다

모든 operation에서 스케줄러가 go를 했을 때
발생하는 문제에 대해서 조금 알아보자
실제로 수십 수백개가 동시에 발생을 하면서 생기는 문제는
굉장히 많을 것 같지만 이 유형을 정리하면
3가지 정도 밖에 되지 않는다고 한다
첫 번째 경우는 T1이 W(A)로 업데이트를 했는데
T2에서 R(A)로 A를 읽으려고 한다
그런다음 T1이 마지막에 다시 W(B)를 하고 커밋을 하는데
이 결과는 T1 -> T2와 같고 serial하다
그런데 여기서 문제는 T1을 abort를 할 수가 있다는 것이다
그럼 T2는 DB에서 없던 값을 읽어버린게 되는 것이다
이런 경우를 DBMS는 허용하면 안된다고 한다
따라서 T1에서는 아직 중간 단계의 데이터이기 때문에
이런걸 Dirty Data라고 하고
그 data를 읽는 것을 Dirty Read라고 하는데
이 Dirty Read를 허용하면 안된다고 한다
이런 충돌을 W-R Confilcts라고 하고
커밋되지 않은 트랜잭션에 의해서 업데이트된 데이터는 읽으면 안된다
두 번째는 T1이 A를 읽고 T2가 그 사이에 A를 고쳐서 커밋했다
이렇게 수행을 해도 최종 결과는 결과에는 문제가 없다
하지만 T1이 처음 읽은것이 100이라고 가정하고
두 번쨰는 200이 된다고 가정하자
이렇게 되면 T1 입장에서는 읽을 때마다 값이 달라지기 때문에
isolation이 되어있지 않은 것이다
이런 경우를 unrepeatable read라고 하고
내가 읽었는데 누군가가 그 데이터를 덮어써버렸기 때문에 발생하는 문제로
이를 R-W Conflicts라고 한다
세 번쨰는 누가 덮어쓴 것을 또 덮어써서 발생하는 문제이다
이를 Dirty Write라고 하고 마지막 결과도 이상해진다
따라서 DBMS는 이런 스케줄도 허용하면 안된다
이를 W-W Conflicts라고 한다
따라서 DBMS에서는 concurrency 문제로 크게 이렇게 3개가 있고
이런 것들만 잘 해결하면 대부분의 concurrency 문제는 해결된다

그렇다면 중요한 것은 이제 어떤 방법을 써서
위의 concurrency 문제를 막을 것이냐이다
이를 대부분의 DBMS는 lock을 이용해서 해결한다
lock의 종류는 여러 개가 있지만 본 수업에서는 2개만 소개하는데
shared lock과 exclusive lock이 있다
위 ppt의 테이블은 lock 호환성에 대한 테이블인데
누군가가 Shared lock을 쥐고 있는데 이를 쓰려고 한다?
그러면 blocking을 해야하고
누군가가 Exclusive lock을 쥐고 있는데 읽으려고하면
blocking을 해야한다
이렇게되면 아까 앞에서 배운 모든 시나리오들을 다 방지할 수 있다
그렇다면 blocking이 걸리면 언제까지 막아야하나?
transaction이 commit이 되던지 abort가 될 때
lock을 해제할 수 있다
따라서 이렇게 blocking을 시키는 것까지가
lock manager의 역할이고
대부분의 DBMS들이 이러한 구조를 변형해서 사용하고 있다
이러한 lock manager는 pessimistic 하다
즉, 비관적인 정책을 사용한다는 뜻인데
이게 무슨 뜻이냐 하면
사실 transaction의 95%는 정상적으로 작동하는데
나머지 적은 5%의 확률을 위해서 혹시 모르기 때문에
모든 상황을 대비해서 lock을 걸기 때문에
여기서 overhead가 발생한다
이를 비관적이라고 표현하는 것이다

lock을 잡고 Lock을 푸는 protocol은
two phase 기반이다
어떤 transaction이 데이터 object를
읽으려고 하거나 update 하려고 할 때
exclusive lock을 확보한다
그러고 다 쓰고나면 lock을 release한다
어떤 data item에 대해서 lock을 걸었다가
한 번 푸는 이상 다시 lock을 거는 것을 허용하지 않는다
필요할 때 lock을 잡아가면서 올라가는 것을
위 ppt의 그래프에서 growing phase라고 하고
다시 내려가는 것을 shringking phase라고 한다

two phase locking을 좀 더 세분화 해보자
T1에서 W(A)가 끝났을 때 lock을 해제하면 안된다
commit하거나 rollback을 할 때까지 lock을 쥐고있어야한다
여기서 read일떄는 괜찮지만 write일 때 끝까지 쥐고가는 것을
strict 2PL이라고 하고
read와 write 모두 끝까지 lock을 쥐고가는 것을
strong strict 2PL이라고 한다
이렇게 하게되면 그 DBMS가 뱉어내는 스케줄은
serializable schedule이다

이러한 lock 때문에 발생하는 문제는
dead lock이다
한국어로는 교착 상태라고 하는데
실생활에서 상황이 꼬여서 이도저도 못하는
그런 상황에 비유하면 좋다
lock을 잡기위해서 잡았는데 영원히 lock이 안끝나는 상황을 말한다

또 다른 lock 기반으로 concurrency control을 수행했을 때
발생할 수 있는 문제점이다
이 concurrency control을 궁극적으로 DBMS가 허용해주는 이유는
동시성을 높여서 DB의 response time을 높여주기 위함이다
그런데 동시에 수행되는 transaction의 개수가 늘어나면
blocking도 늘어나서 runtime overhead도 증가하게 된다
초당 database가 처리할 수 있는 transaction 개수가 증가하다가
임계치를 넘어가는 순간 lock 때문에 시스템 전체 성능 자체가 떨어진다
이런걸 Lock으로 인해 thrashing에 빠진다고 말한다
따라서 이런 경우를 제한하는 것이 필요하다

실제로 SQL 입장에서의 transaction이란
그냥 문장 하나가 그 하나로 transaction이다

어떤 transaction이 데이터를 쓰거나 읽으려고 할때 lock을 거는데
그 Lock을 걸 때 그 database의 크기를
lock granularity라고 한다
lock은 table, page, record, column 단위로 걸 수가 있는데
일반적으로는 row 혹은 tuple level에서 lock을 건다
필요하면 테이블 단위로도 lock을 걸 수가 있다
따라서 위 ppt를 보면 tuple 구조에서
가장 앞에 lock bit가 있고
누군가 lock을 걸고 있다 없다를 표현한다고 한다
lock을 세부적으로 걸수록 concurrency가 높아지는데
대부분의 DBMS는 튜플 레벨로 lock을 잡는다고 한다
file system은 file 단위로 lock을 잡아서
DBMS는 이것보다 concurrency가 높다고 한다
마지막으로 phantom problem이라는 것을 보고
오늘 수업 내용 정리를 마쳐보려고 한다
transcation에서 위의 쿼리를 수행시켰을 때
rating이 8인 레코드에 대해서 접근해서
read lock을 쥐게 된다
그런데 만약 이 때 다른 transaction에서 rating = 8인
tuple을 Insert를 했다
그런 다음에 테이블에 접근해서 다시 위 쿼리를 돌리면
새로 추가된 레코드도 조회가 되게 되는데
그럼 결과가 달라지게 되는 것이다
repeatable read를 보장하기 위해서
lock을 걸었는데도 결과가 달라지는 경우가 발생하는 것이다
따라서 이런 문제를 phantom problem이라고 한다
이런 문제를 해결하기 위해 rating = 8에 대해서 Lock을 거는데
이걸 predicate lock이라고 한다고 한다
'강의 > database' 카테고리의 다른 글
| [database] Crash Recovery (2) | 2025.06.07 |
|---|---|
| [database] DB Lock 2편 (multi-version CC, MVCC) (2) | 2025.06.06 |
| [database] simpleDB로 buffermanager에서 LRU 알고리즘 구현하기 (2) | 2025.05.27 |
| [database] Physical Query Algorithm & Query Optimization (0) | 2025.05.26 |
| [database] External Sorting (2) | 2025.05.25 |