본 게시글은
서울대학교 데이터사이언스대학원 정형수 교수님의
데이터사이언스 응용을 위한 컴퓨팅 시스템 강의를
학습을 목적으로 재구성하였습니다
이번 수업은
교수님께서 중요하다고 정말정말 강조하신
가상 메모리에 대한 내용이다
이번 시간과 다음 시간에까지 진행할
이 가상 메모리 개념이 중간고사 범위인데
교수님이 정말정말 중요하다고 강조하셨다
가상 메모리는
one of the greatest idea in computer science라고도 불릴만큼
위대한(?) 개념이라고 한다

아무튼 가상메모리 수업 정리 시작-!
가상메모리는 영어로는 virtual memory인데
이전 시간에 배웠던
메모리 계층구조(memory hierarchy)를 위해 나온 개념이다

지난주까지 열심히 공부했던 캐시 메모리는
single process가 동작할 때
나오는 address와 그에 해당하는 데이터를
메모리 계층구조에 어떻게하면 가장 가까운 구조에 둘까?
하는 이야기였다
하지만 지금부터 할 얘기는
single process가 아닌
multi process에 대한 이야기이다
process가 하나일 때는 그냥
address space에 접근하면 되는데
만약 프로세스가 여러개라면?
그럼 어떻게 해야할까?
가상 메모리는 위의 상황에서
아래의 2가지 질문을 해결하기 위해 나온 개념이다
1) 각 process가 각각의 주소에 접근한다고 할 때
그 주소를 어느 주소로 해야하나?
2) 그렇다면 저 주소를 process마다 같은 주소를 하면
서로 충돌이 나지 않을까?
(당연히 난다)

우선 address space라는 개념에 대해 알아보자

위 예시는 one process, one thread에서의 경우이다
그럼 physical address를 그냥 사용하게 해줘도 된다
one process를 주로 활용하는
엘레베이터 알고리즘 같은 경우는
이런 방식으로 충분히 가능하다고 한다
그런데 만약에 process가 여러개면?
이번 수업시간에서 running program을 추상화한게 process라고 했다
그렇게 생성된 여러 개의 process가
같은 physical address를 접근하려고 하면
그 때부터 문제가 발생하게 된다

그래서 도입된 개념이 바로
virtual memory
가상 메모리 개념이다
현재 돌고있는 여러 개의 프로세스로 하여금
자신이 사용하는 address space를 unique하게
해주기위해서 나왔다
process는 여러 개인데
각각의 Process들이 physical address를 사용하게하면
다른 process의 메모리 영역을 침범할 수도 있게 된다
따라서 protection을 위해서
분리시켜야할 필요가 있었다
또한,
program마다 쓰고자하는 메모리 영역의 사이즈가 각각 다르다
하지만 가용한 physical memory는 이미 정해져있는데
이를 어떻게하면 잘 활용할까에 대한 것도
가상 메모리를 통해서 해결하고자 했다
아무튼 이러한 이유로
virtual memory를 사용하자!
가 된 것이다
그렇다면 말 그래도 Physical memory는
우리가 흔히 생각하는 위의 main memory이고
virtual memory는 가상 메모리인데
physical과 virtual을 맞춰야 할 필요가 생긴다
따라서 이 둘을 맞춰주기위한
mapping table이 생기게 된다
따라서 이 mapping table을 이용해서
address translation을 진행하게 된다
따라서 CPU가 요청하는 것은 virtual address이다
그럼 이 virtual address를 translation하기 위해서
address mapping table을 이용해
physical address를 mapping한다
따라서 이 Mapping table이 어떻게 구성되어있느냐가
virtual memory 구성의 key가 된다
또 이러한 작업을 하게 해주는 것이
위에도 나오는 MMU(Memory Management Unit)인데
virtual address를 physical address로 바꿔주는
circuit인 이 MMU가 CPU안에 내장되어있다

address space는 3가지의 개념이 있다
1) linear address space
0부터 무한까지의 address
2) virtual address space
하드웨어가 지원하는 memory의 맥시멈
3) physical address space
컴퓨터에 들어있는 실제 가용한 메모리

그렇다면 virtual memory를 사용하는 이유는 무엇일까?
아까 다 설명을 했지만
다시 한 번 정리해보자
우선 여러 개의 프로그램을
실제 메모리 상에서 잘 돌아가도록 해주기 위해서이다
또한 프로세스가 서로의 프로세스를 침범하지 않게 하기 위해
isolation을 시키기 위해서도 사용한다
여러 프로그램에서 필요로 하는 주소가
다 똑같이 0x ... 어쩌구 여도
프로그램마다 실제 주소는 달라지는 것이다

이제부터 저 3개에 대해서
본격적으로 배워보자

virtual memory는 virtual address로
내가 모든 address space를 다 쓸 수 있는 것처럼
illusion을 줘야한다
그럼 이걸 우리가 어떻게 해석할 수 있을까?
virtual memory는 한 마디로 비유하자면
마치 원래 고향은 디스크(storage)인데
그 중에 실제 내가 쓰고있는 것(instruction, data 등)만
메모리에 잠시 올려두는 개념이다
우리가 이전 시간에 캐시 메모리에 대해 공부하면서
캐시 메모리는 메모리 계층구조 상
memory vs CPU cache의 구조였다면
virtual address space라고 하면
원래 모든 데이터는 다 디스크에 있고
그 중 일부가 DRAM에 캐싱되는 것과 같은 구조이다

한 마디로 DRAM을 cache memory같은 용도로 인식하자는 것이다
근데 그렇게 되면
지난 시간에 배웠던 SRAM의 cache memory를 공부할떄와는
단위 자체가 달라진다
우선 miss penalty가 훨씬 커진다
miss penalty가 CPU <-> main memory의 10배 이상 수준을 넘어
10000배 이상으로 커진다
왜냐하면 이건 main memory <-> disk의 문제이기 때문이다
따라서 저번시간에 CPU cache 공부하면서
hit되면 좋고 miss나면 아쉽~ 수준이 아니고
정말로 관리를 잘 해주어서
miss penalty를 최소화해야한다
그래서 SRAM의 cache와는 설계가 달라지게 된다
이런 문제들을 고민하다가
main memory <-> disk 갈 때
penalty가 너무 크기 때문에
한 번 접근할 때 그냥 큰 단위로 한 번에 가져오자!
라는 생각이 나왔다
따라서 데이터를 가져오는 단위가 커지게 된다
그럼 이 단위를 어느 정도로 조정하면 좋을까?
단위를 너무 크게하면 쓸데없는 데이터도 다 가져오게되고
그렇다고 너무 작게하면 굉장히 frequent한 miss가 발생할 수 있다
따라서 이 단위를 적정선에서 타협하는 것이 중요했는데
현대에 와서 2의 12제곱 바이트, 즉 4KB를 가져오는 것으로
타협을 보았다고 한다
이 4KB가 결국 main memory <-> disk 사이에 왔다갔다하는
데이터들의 단위이고
이걸 page라고 부르기로 했다
그런데 이게 보통 4KB인거지
특수한 경우 단위를 늘릴 수도 있다
리눅스의 경우 2MB까지도 지원하고
더 나아가서는 1G까지도 올릴 수 있다고 한다
그런데 아까 위에서도 언급했지만
이 단위가 크다고 무조건 좋은게 아니다
큰 단위로 바꾸면 당연히
한 번에 많은 데이터를 가져오기 때문에
miss가 줄어들겠지만
이 page의 단위가 커진다는 것은
사실 원하는 것보다 쓸데없는 더 큰 공간을 붙잡고 있는 것이 된다
한 번 단위가 정해지면 그 내부를 남에게 주는 것이 불가능하다
따라서 내부에 사용가능한 공간이 있는데도
남에게 줄 수가 없는 것이다
이걸 internal fragmentation이라고 부른다
이러한 단점을 없애기 위해서 4KB라는 단위로 통일한 것이다
또한 앞에서 CPU cache의 경우
direct-mapped, set-associative 구조를 사용하여
conflict miss가 발생할 수 있었다
하지만 virtual memory에서는
miss를 최소화해야하기 때문에 conflict miss가 나서는 안된다
full-associative구조는 power consumtion이 증가하지만
다른 구조와는 달리 데이터들이 cache의 어느 자리에든
다 들어갈 수 있게 해주는 구조기때문에
conflict miss를 최소화하고 utilization을 높일 수 있다
그다음 당연히 write-back을 사용한다
진짜로 메모리가 부족하게 되면
그때 디스크에 write하는 전략을 사용하는 것이다
왜냐면 디스크에 한 번 접근할 때마다
시간이 매우 오래걸리기 때문이다

설명이 길었지만 아무튼
CPU cache와 virtual memory 설계는
많이 다르다고 이해하면 좋을 것 같다
사실상 virtual memory를 정말 빠르게 사용할 수 있는
방법이 있다고한다
이건 다음 시간에 배울 내용인데
한 20년 전 쯤에 나왔던 방식이라고 한다
하지만 이 방식을 배제하고 우리가 쓰는 방식은
좀 더 속도가 느린데
왜 빠른 방식을 버리고 현대에 이 방식을 사용하는지는
다음 시간에 제대로 배운다고 한다
아무튼 virtual address에 해당하는게
physical memory의 어디에 해당하는지
매핑을 해주기 위한 자료구조가 필요할 것이다
그게 바로 page mapping table이다
보통 줄여서 page table이라고 부른다
위 ppt slide를 보면
virtual memory와 physical memory(DRAM)이 있고
virtual memory adress에서의 0이
실제 physical memory의 어디에 해당하는지를
page table은 알고있다
실제로 DRAM 상에서 4KB까지 끊어놓은 애들이
쭈우욱 나와있는 것이다
DRAM은 CPU cache와 달리
fully associative 구조로
그냥 비어있으면 바로 데이터를 저장하는 구조이다
만약에 한 번도 본 적이 없는 데이터다?
그럼 cache miss와 같은 사태가 발생하는데
이를 page fault라고 한다
아까 앞에서 virtual memory는
여러 개의 프로그램을 돌릴 때
메모리를 protection하기 위한 목적도 있다고 했는데
실제로 프로그램 한 개당
mapping table이 존재한다
그럼 얘의 size는 이론상으로는 되게 커지게 될 것이다
하지만 이렇게 커지는 것이 싫기 때문에
이 page table조차도 쪼개는 개념이 나오게 된다
이것도 다음시간에 자세하게 배우게 된다고 한다..

그래서 이렇게 CPU가 virtual address를 보내주는데
virtual address는 VPN(virtual page number)와 offset
두 부분으로 나눠져서 온다
VPN은 해당 주소가 속한 가상 페이지의 번호이고
offset은 해당 page내에서 데이터의 위치이다
따라서 virtual address의 VPN을
page table의 index로 이용해서
해당 PTE(page table entry)를 찾는다
그러고 위 slide처럼
PTE 안에는 valid bit과 physical page number가 들어있다
따라서 거기서 찾은 physical page number와
virtual address에서 함께 보내줬던
offset을 이용해서 실제 데이터에 접근하게 된다
이런 일련의 과정을 address translation이라고 한다

만약에 위 경우처럼
virtual address에서 VPN을 찾아 entry에 들어갔는데
거기에 해당하는 물리 메모리 매핑이 없다면?
page fault가 발생하게 된다
이렇게 page fault가 발생하게되면 우리가 2~3주차에 배웠던
운영체제에서의 exception control이 수행되게 된다
제어권이 OS의 page fault handler로 넘어가게된다
그럼 이후에 어떤 작업이 수행되냐?
아직 해당 virtual address가 메모리에 올라오지 않은 것이기 때문에
disk에서 읽어서 해당 페이지를 DRAM에 올려야한다
그런데 만약 새로운 페이지를
DRAM에서 올릴 공간이 없다면?
Page Replacement Algorithm을 통해서
가장 덜 사용되는 것 같은 page를 빼고
새로운 페이지를 로드하게 된다
그런 다음 Page table에 해당 물리주소를 넣고
page table을 업데이트한다
그다음 운영체제는 해당 instruction을 다시 재수행하게 된다
이를 수행하기 위해 CPU는 매번 수행할 때
memory address에 접근할 때
가장 최근에 접근한 address를 기억한다
왜?
만약 page fault가 발생했을 때
exception handler가 발동하고
다시 해당 Instruction을 실행할 때
가장 최근에 접근한 주소를 알고 있어야지만
해당 instruction을 다시 실행할 수 있기 때문이다
따라서 이걸 어디에 저장하냐?
Control Register 4라고 해서
CR4에 저장한다

page fault가 발생한 사례이다
a[500]에 접근하려고 했는데
한 번도 접근한 적이 없어서
page fault가 발생했다
그럼 page fault handler의 pin이 딱 켜지게되고
모든걸 멈추고 kernel stack에 지금까지 동작하고있던
모든걸 저장한다
그 다음에 위에서 설명한 방식대로
disk에서 가져와서 DRAM에 올려주고
해당 정보를 page table에도 세팅해준다
그런 다음 아까 Instruction을 다시 수행하게 된다

위 예시에서 뭐..
page fault가 발생했는데 DRAM에 공간이 없어서
VP 4를 빼고 새로운 page를 넣어주는 예시라고 한다
우리가 c언어에서 malloc을 하게 되면
얘는 page table의 entry만 열어주는 과정이다
실제 physical address는 아직 할당되지 않은 것이다
그래서 우리가 선언을 하고 실제 access를 수행하게되면
fault가 발생하게 된다
우리가 실제로 access를 하고 read, write를 하는 그 순간에
실제 물리 주소가 할당이 된다
그래서 malloc하고 access하는 순간
fault가 발생해서 순간 느려지게 된다
"physical memory page is allocated as you demand"
그래서 이 개념을 demand paging이라고 부른다
운영체제에서 실제로 매우 중요한 개념이다

따라서 페이지를 올릴 때
우리가 어떤 데이터를 쓸지 미리 알면 좋지만 쉽지 않다
따라서 실제 virtual memory에서
함부로 prefetching을 하지 않고
실제로 demand할 때만 이루어지게 되는 것이다
그래서 앞의 CPU cache에서 배웠던
locality의 개념이 여기에서도 사용되게 된다
우리가 실제로 작업하고 있는 페이지 집합을
working set이라고 부른다
working set은 시점마다 다르고 동적으로 바뀐다
만약에 이 working set이 DRAM보다 작으면
처음에는 cold miss가 발생할 수 있지만
이후에는 필요한 데이터가 다 메모리에 올라와있기때문에
이상적으로 잘 작동할 수 있다
하지만 만약 working set이 DRAM보다 커지게되면
문제가 발생하게 된다
필요로하는 데이터가 실제 메모리 안에 다 못올라오므로
새로 페이지를 올리기 위해서
기존 페이지를 또 날리고 하는 과정을 반복하는
capacity miss가 계속해서 발생하게 된다
이 과정에서 IO로 인한 cycle이 굉장히 많이 발생하게 된다
(그래서 성능 좋은 서버와 우리가 흔히 쓰는 노트북은
보통 10000배의 cycle정도가 차이난다고한다)
계속 이렇게 되다보면 어느 순간
프로그램이 안돌아가기 시작한다는데
이런 현상을 thrashing이라고 부른다
thrashing에 걸려버리면 성능이 수직으로 떨어진다고 한다
그래서 DBMS도 그렇고 어떤 프로그램이든
working set 사이즈를 DRAM보다 키우지 않는 것이
매우 중요하다고 한다
아무튼 이 설명을 하시면서 크롬에 대해 말씀해주셨는데
크롬을 한 번도 안끄고 계속해서 창을 추가하게 되면
여기서 계속 thrashing이 발생해서 엄청 느려진다고 한다
그래서 컴퓨터 느려지면 크롬만 한 번 꺼도
가용 메모리가 쭈욱 생긴다고 한다

앞에서도 말했지만 프로세스마다
각각의 virtual memory를 사용한다
그래서 프로세스마다 매핑 테이블이
각각 딸려서 들어와야한다
그럼 CPU가 address를 보내면
바로 어떤 프로세스의 어떤 테이블로 보내야하는지 알아야하는데
따라서 각 table의 base address를 기억하고 있는
누군가가 있어야한다
따라서 이를 수행해주는 레지스터가 있고
이게 바로
Control Register 3(CR3)이다
따라서 현재 수행 중인 프로세스가 바뀌면
CR3가 같이 바뀌게 된다

page table 내부를 자세하게 살펴보자
page table을 살펴보면 각각의 virtual page(vp)들이
이렇게 physical page(pp)들과 연결되어있다
그런데 자세히 살펴보면 permission bits라고 해서
이 페이지에 대해 어떤 동작이 허용되고
어떤 동작은 금지되는지를 알려주는 비트들이 있다
각각 read, write, execute, sup 등이 대표적이다

이제 address translation을 살펴보자(지금까지 거의 다본 것 같은데?)
address translation은
virtual address를 physical address로 바꿔주는 과정이다
MAP을 하게 되면
V를 P 또는 공집합으로 만들어주는데
P는 physical address이고
공집합이 나오게 되면 Page fault가 발생한다

address translation에서 사용되는 용어들이다
Virtual Address (VA)에서는
VPO (virtual page offset)
VPN (virtual page number)가 있고
Physical Address (PA)에서는
PPO (physical page offset)
PPN (physical page number)가 있다
PPO와 VPN을 더하게 된게 실제 DRAM에서
어느 부분을 가서 어떤 데이터를 가져와야할지 정해주는 것이다
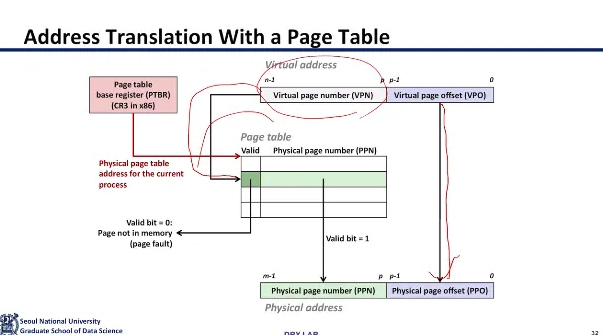
address translation 과정을 도식화 한 것이다
아까 앞에서 봤던 것과 유사하다
CR3를 통해 CPU는 어느 mapping table로 가야할지
base address를 통해 결정한다
그럼 해당 base address를 가진 page table로 향한 다음
VPN을 통해 page table에서 index에 맞는 entry를 찾아가고
valid한지 확인 후 PPN을 확인하게 된다
그런 다음 PPN과 PPO의 조합을 통해
실제 DRAM에 접근해서 필요한 데이터를 가져온다
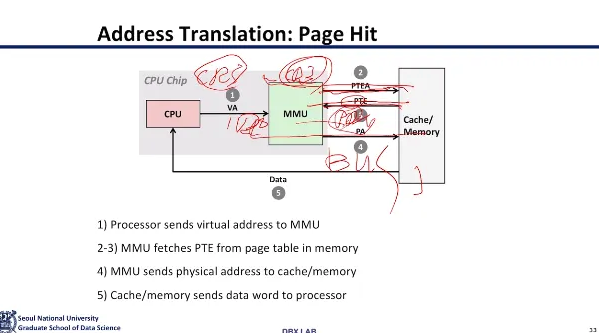
위에서 설명한 것과 동일하다
MMU에서 CR3을 보고 base address를 확인한다
PTE를 찾아가서 entry를 확인하고
PPN+PPO를 bus에 태워서 보내버리면
마지막에 데이터가.. 나온다고한다

그럼 page fault가 발생하면?
아까 앞에서도 말했듯이
page fault 하드웨어의 핀이 켜진다
그럼 진행되고 있던 모든 것이 다 동작그만 ..
그리고 지금까지 수행한 모든 것을
kernel stack에 저장하게 된다
그런 다음 disk로 가서 필요로하는 데이터를 가져오게되는데
이 victim page를 수행할 때
거의 1000사이클 가까이 걸린다고 한다
그런데 만약에 new page를 DRAM에 올릴 자리가 없다?
그럼 거기서 thrashing이 발생하는 것이다
그래서 mapping table의 entry 중 일부를
cache에 올려놔서 빨리 page table lookup을 수행할 수 있도록 한다고 한다
그래서 address translation을 하는 이 mapping table을
caching 하는 circuit이다라고 해서
translation lookaside buffer (TLB)
그 유명한 TLB가 나오게 됐다..

page table의 entry정도는 cache에 올려달라고
하드웨어 회사에 부탁을 하게 된 것이다
그래서 TLB라는 하드웨어를 MMU에 둬서
page table의 entry를 저장하게 되었다
만약 TLB가 없다면 10배정도 느려진다고 한다

이건 TLB의 구조이다
우리가 지금까지 알고있던
L1, L2, L3 캐시와는 용도가 완전히 다르다
이건 MMU 내부에서 CR3가 들고있는 base address의 table의
page table entry를 담아놓는 용도이다
VPN을 이용해서 이 TLB에서 lookup해서 성공한다면
100 사이클 정도가 세이브 된다고 한다
만약 TLB miss가 많이난다?
이 뜻은 address translation을 위해서
memory를 계속 왔다갔다 하고 있다는 의미이다
따라서 TLB란
address translation을 가속화하기 위해서
MMU에서 전용으로 사용하고 있는 캐시이다

마지막으로 TLB의 동작을 한 번 살펴보고
오늘 수업을 마무리해보자
CPU에서 VA가 날라오면
MMU에서는 즉시 TLB lookup을 시도한다
만약에 TLB에 있다?
thank you 한 다음 바로 100 사이클을 save한다고 한다
TLB도 당연히 다른 메모리들처럼
크면 좋겠지만
가격문제도 있기 때문에 한계가 있다
따라서 TLB가 아무리 커봤자
1000개 정도의 entry만 담을 수 있다고 한다
이번 시간에 배운건
virtual memory를 왜 사용하는지와
기본적인 concept에 대해서 배웠다
그렇다면 다음 시간에는?
사실 우리가 배운 page table은 size가 정말 크다
하지만 page table의 대부분은 사실
잘 안쓰게 된다고 한다
그래서 Internal fragmentation이 너무 커지게 된다
그래서 이걸 쪼개자는 개념이 등장하게 된 것이다
따라서 다음 시간에는 이 부분을 자세하게 배워본다고한다
그럼 오늘 가상 메모리 개념에 대한 내용은 여기까지!
'강의 > system programming' 카테고리의 다른 글
| [system programming] program optimization (compiler와 최적화 기법) (3) | 2025.05.11 |
|---|---|
| [system programming] 가상 메모리(virtual memory) 2편 (0) | 2025.05.03 |
| [system programming] 캐시 메모리 (Cache Memory Organization and Operation) (2) | 2025.04.28 |
| [system programming] 메모리 계층구조와 캐시 메모리(Memory Hierarchy, Locality, Cache Memory) (0) | 2025.04.28 |
| [system programming] Parallel Architectures (ILP, DLP, TLP) (1) | 2025.04.13 |