본 게시글은
서울대학교 데이터사이언스대학원 정형수 교수님의
데이터사이언스 응용을 위한 컴퓨팅 시스템 강의를
학습을 목적으로 재구성하였습니다

지난 시간에 이은 가상메모리 2편이다
교수님께서 컴퓨터 공학에 있어서
굉장히 중요한 부분이라고 강조 또 강조하신 부분이다
우선 지난 시간에 배운 내용을
간단하게 복습하고 본격적으로
이번 수업시간에 배울 내용으로 넘어가보자
1950-60년대에는 os를 Physical memory 상단부에
고정 시키고 나머지 부분을 활용하는 방식을 사용했다
따라서 예전에는 physical memory가
위 ppt slide처럼 구성되어있었다
가장 위에 os를 위한 부분이 있고
그 아래에 여러 프로세스에 대해서
저장하는 공간이 각각 할당됐었다
총 512KB정도가 있지만
예전에는 이 정도 메모리도 크다고 생각했었다

하지만 프로그램 사이즈가 커지다보니
Physical memory의 한계를 초과하는 사태가 발생했다
그래서 사람들이 생각해낸 것이
모든 프로그램이 자기만의 physical memory를 가진 것처럼
illusion을 주자는 것이었다
이게 바로 address space의 개념이고 가상 주소 공간이다
여기서 physical address space는 진짜 DRAM space를 말한다

우리가 컴퓨터 관련 수업을 듣다보면
꼭 한번은 보게되는 address space 그림이다
그림에서는 보통 stack을 아래에 있다고 표현하지만
실제 메모리에서는 stack이 위에 있다
code영역은 실제 instruction들이 저장되는 곳이고
heap은 malloc, new처럼 동적으로 할당되는 변수들이
stack은 지역변수나 함수들이 저장되는 곳이다
어쨌든 여기서 heap과 stack은 계속해서
영역을 확장하면서 만나는 구조이다

따라서 virtual address와 physical address 간에
간극이 발생하였고
이걸 맞추기위해서 생긴 것이 translation이다

그래서 각자 자기가 가진 mapping translation을 갖고있으면
실제 주소 공간이 어디인지 알 수 있다
따라서 이 mapping을 해주는 translation 작업이 필요한 것이다

지난 시간에 사실 정말 빠른
address translation 방법이 있다고 했다
옛날에는 프로그램 사이즈가 작았기 때문에
(가용 실제 메모리보다)
사용가능한 address translation 방법이 있었따
하드웨어 기반의 translation 방법이라고해서
1970년대에 등장했었다

Hardware-based address translation의
예시를 한 번 살펴보자
위의 c언어 코드가 있다
위 코드를 수행하기위해 사용되는 명령어는
load, increment, store이다

그래서 위 코드를 assembly로 바꾸면 이렇게 된다
32비트라서 레지스터 앞에 e가 붙는다

이제 address space를 잘 보자
함수 내부의 변수는 stack 부분에 할당된다
그래서 x가 stack에 할당되었다
addressing은 이렇게 되어있지만
이게 실제 physical address랑은 다르다
따라서 이거랑 physical address와의 mapping을 위해서 무언가가 필요하다

따라서 virtual address를 하나의 메모리로 묶고
그걸 physical memory에 저장하는 방식을 사용하였다
이런 방식이 가능했던 이유는
프로그램 사이즈가 실제 물리 메모리 사이즈보다
훨씬 작기 때문이었다

그래서 이 virtual address space를
physical memory의 어딘가에 저장했었다
physical address는 어디서부터 시작하는지 알려주는 base가 필요하고
여기서 offset만 더해주면 위치를 찾을 수 있게 했다
그래서 해당 영역인 bound를 넘는지 안넘는지
확인하는 bound variable register가 필요했다

그래서 base and bound 방식을 사용했었다
bound register는 프로그램의 최대 size이며
base register는 실제 physical memory의 어디에
relocation 되었는지를 나타낸다

위 ppt slide에 있는 super computer가
지금까지 설명한 base and bound 방식을 이용한 컴퓨터이다
그런데 점점 프로그램 사이즈가 커지기 시작하면서
physical memory에 이걸 담을 수가 없게 되었다
그렇다고 한 번에 너무 큰 단위로 주면
internal fragmentation이 발생하게 된다
그래서 heap, stack별로 base and bound를 따로 만들었다
그렇게 해도 여전히 translation은 굉장히 빨랐다
그래서 연속으로 할당된 그 단위는 memory segment라고 불렀고
segment 단위로 base and bound memory를 주자고 한게
segmentated memory이다
c언어에서 잘못된 address에 접근하면 발생하는
segmentation fault가 여기서 유래된 것이다
하지만 이런식으로 하다보면
자꾸자꾸 segment 개수가 늘어나게 된다
그래서 그러지말고 translation의 단위를 fix하자고 한게
지금의 page가 된 것이다
따라서 지금 사용하고 있는 page는
매우 fine-grained하게 작성된 base and bound라고 할 수 있다
각각의 page별로 어디가 시작이고 어디가 끝인지
계속 기록하는 방식이라고 할 수 있다
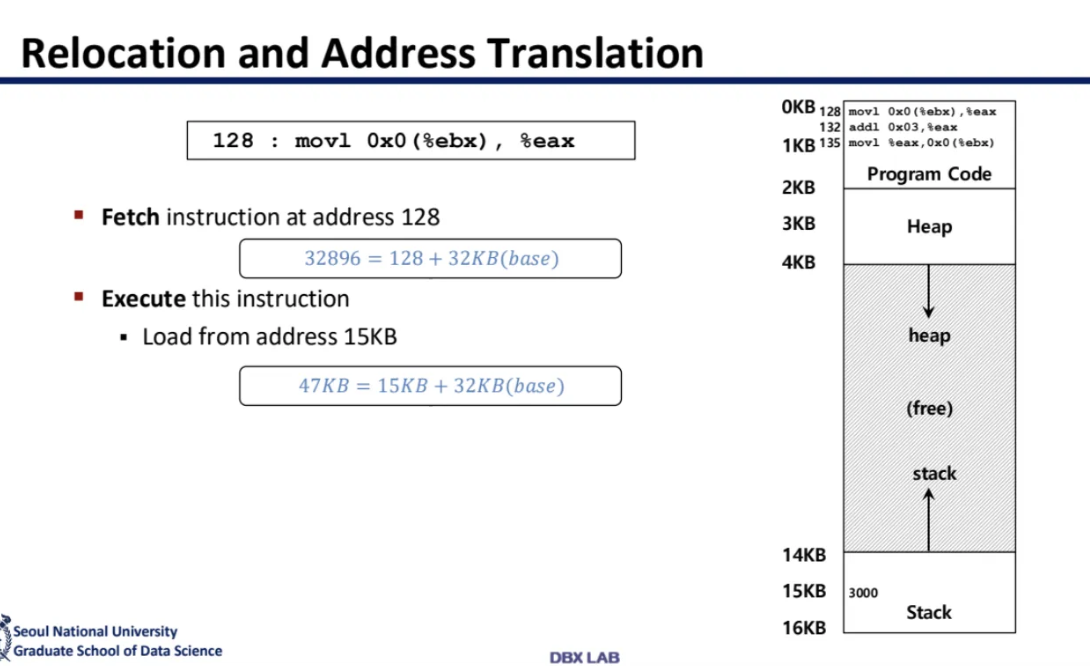
아무튼 relocation and address translation 방식에서는
위 ppt처럼 translation 해주면 됐다고 한다
128에 저런 instruction이 있다고하면
instruction을 fetch하는 방법은
128에 base인 32KB를 더해주면 됐다
또 아래도 address 15KB에서 뭔갈 가져오려고 하면
base에 15KB만 더해주면 됐다

아무튼 이런식으로 해주면
address translation이 1 cycle안에 끝날 수 있다고 한다
또한 TLB같은 캐시도 필요가 없어진다

이쯤에서 저번 시간에 배운
page table에 대해 잠깐 복습해보자
page란 우리가 allocation하는 segment 단위를
고정시키자고 한 것이다
따라서 fixed size segment = page인 것이다
처음에는 이걸 프로그램 사이즈 통째로 설정해주었는데
너무 커서 internal fragmentation이 많이 발생하게되었다
그래서 좀 더 작은 단위로 자르게 되었고
page table도 자르게 되었다
이렇게 하다가 효율성을 위해서
recursive하게 table을 구성하게 되었다고 한다
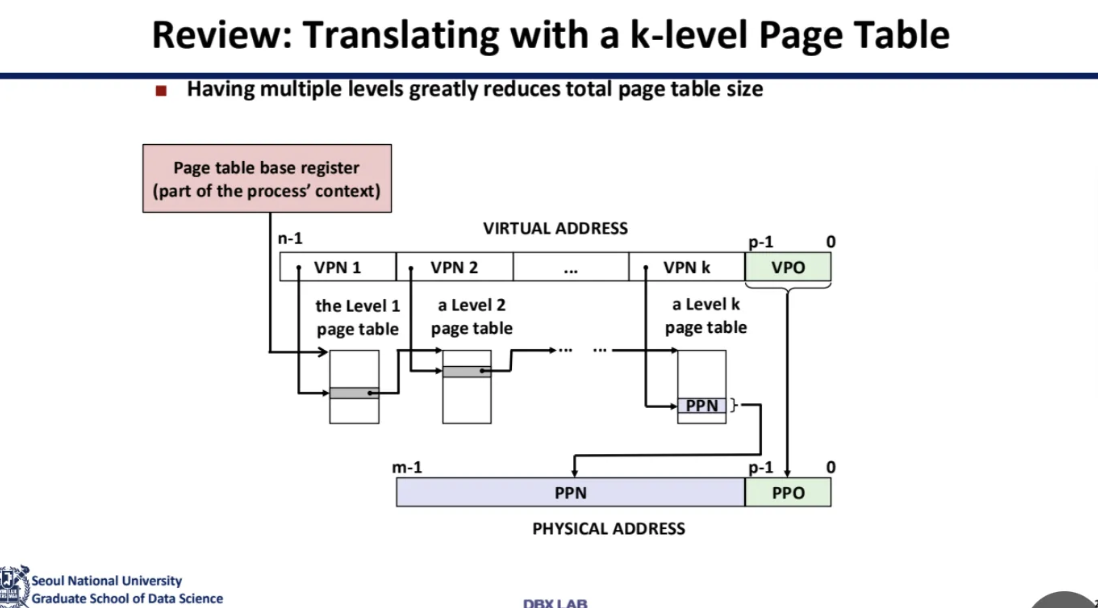
아무튼 그렇게 해서 등장하게 된 구조가
multi-level page table(계층형 페이지 테이블)이다
각 table을 index로 분해해서 관리한다
page table이 recursive하게 구성되어있는데
저 page table에 있는 fragment가
어디에 있는지 가리키는 entry가 뒤의 base를 가리키고
이를 base and bound가 recursive 혹은 hierarchy하게 구성이 되어있다고 부른다
따라서 각 테이블이 다음 테이블을 가리키고
최종적으로는 데이터가 있는 페이지를 가리키는
자기 참조적 구조이다
table 전체가 다 존재하는게 아니고
그때 그때 찾아가서 할당을 해주고 해주다가
final destination에서 data access를 해주는 것이다
이런 과정 자체를 page table walk라고 한다
사실 여기까지만 들었을 때
정확하게 머리에 그림이 그려지지 않아서
GPT에게 물어봤다

이렇게 되어있는 64bit 아키텍처에서
4-level page table 예시이다

이렇게 각 table을 타고 타고 타고 가서
최종적으로 물리 페이지의 주소를 담고 있는 테이블에 가서
실제 data에 access하는 것이
page table walk의 과정이다
따라서 이런 방식으로 사용하면
page table을 만든 multi-level의 개수만큼
memory access를 해줘야한다
TLB miss가 발생하면 실제 memory access를
5번 정도 해줘야한다고 한다
아무튼 이런 이유 때문에 TLB miss가 안나는 것이
매우 중요하다고 한다

지금까지 배운 내용에 대한 간단한 정리이다
왜 one-level page table을 쓰지 않는가?
전체 page table을 다 쓰지 않는데
one-level page table을 사용하면
메모리 낭비가 굉장히 심해지기 때문이다
따라서 multi-level page table을 이용해서
그 때 필요한 entry만
page table tree를 타고 가게 해서
할당될 수 있도록 해주는 것이다
이러한 multi-level page table은 당연히 느리다
왜냐하면 k-level page table은
실제 physical address에 접근하기 위해서
k번을 지나가야하기 때문이다

따라서 k-level page table의 문제점을 살펴보자
depth가 k인 page table 구조이다
각 계층마다 Page table의 size를 키우면
design상 최초의 segmentation model과 가까워진다
또 translation efficiency가 확실히 높아진다
하지만 당연하게도 internal fragmentation이 많아지고
memory utilization이 떨어지게 된다
k-level page table은 one-level page table보다
5배 정도가 느리다
그런데도 왜 k-level page table을 사용할까?
지금까지 설명해서 너무도 당연하겠지만
memory utilization때문이다
speed와 memory space를 trade off 한 셈이다
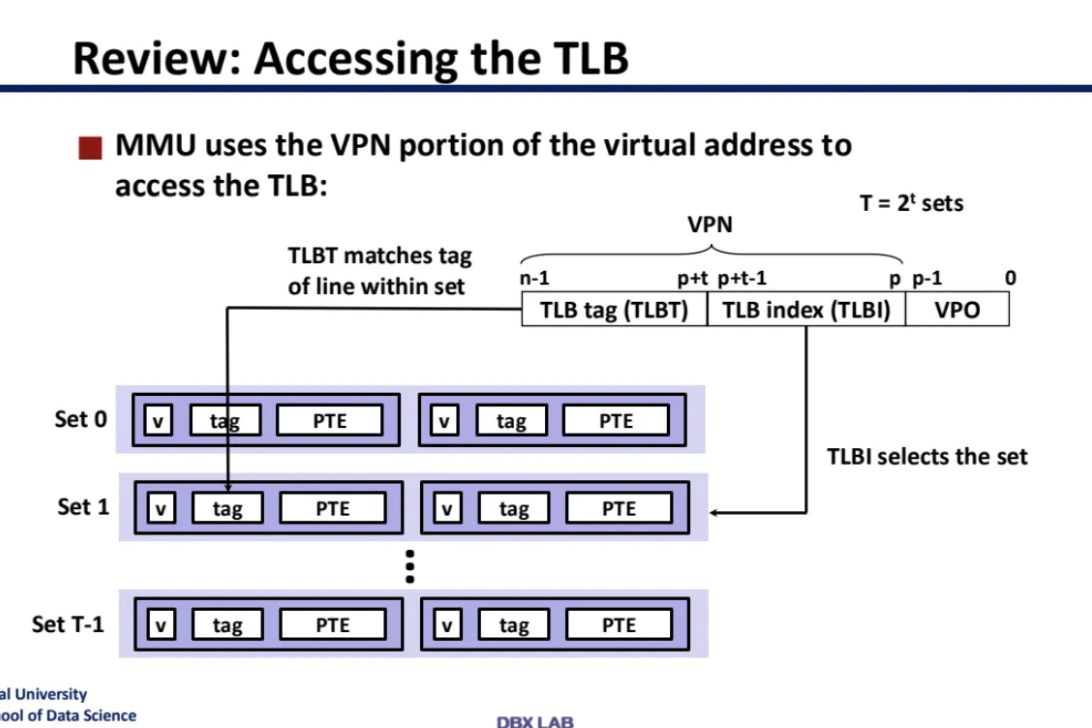
저번시간에 page table mapping 속도를
빠르게 도와주기 위한 캐시인 TLB를 살펴봤다
TLB는 translation mapping data를 캐싱하는데
translation lookaside buffer라고 해서
줄여서 TLB라고 불린다
TLB는 다른 캐시 메모리들과는 다르게
VPN 전체를 lookup한다

CPU의 cache는 physical address와만 작동한다
따라서 CPU의 VA를 바탕으로
TLB를 거쳐 PA를 찾은 다음
해당 PA가 cache를 거쳐서
실제 데이터를 찾는데에 사용되는 것이다
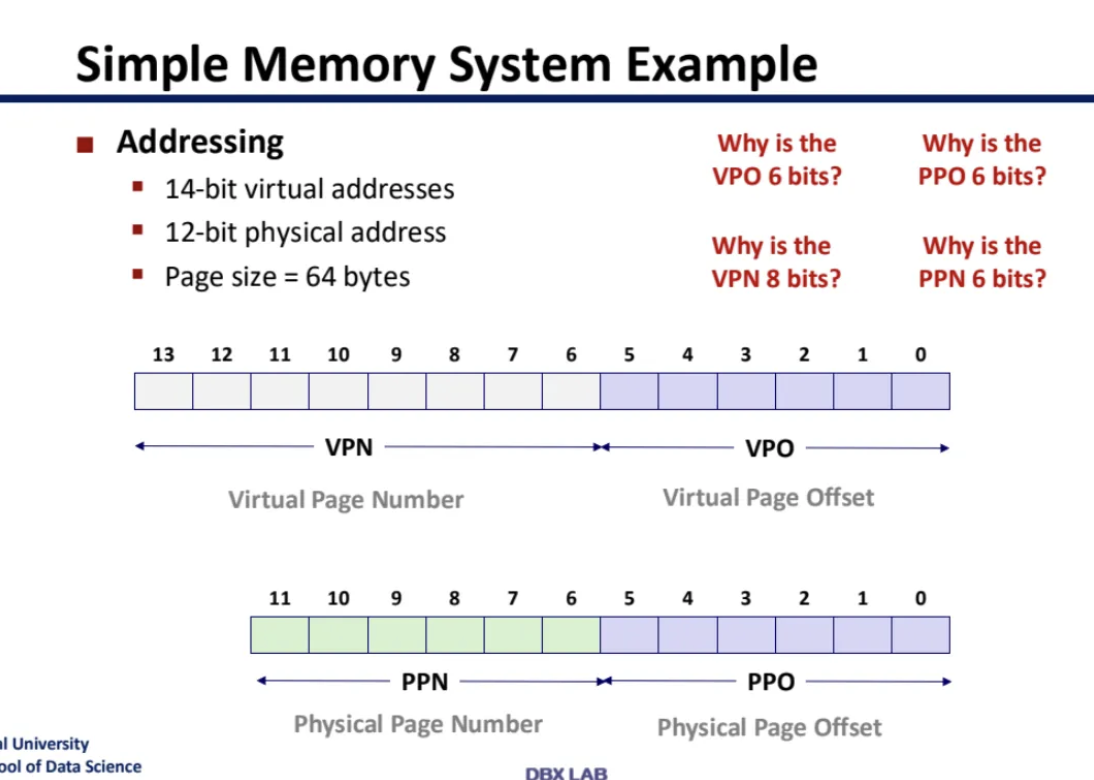
CPU가 보내주는 VA에는
VPN과 VPO가 있다고 저번 시간에 배웠다
VPN을 TLB에서는 cache에서의 tag처럼 사용하고
나중에 PPN과 VPO를 그대로 합친다
이게 TLB에서 데이터를 찾는 방식이라고 한다

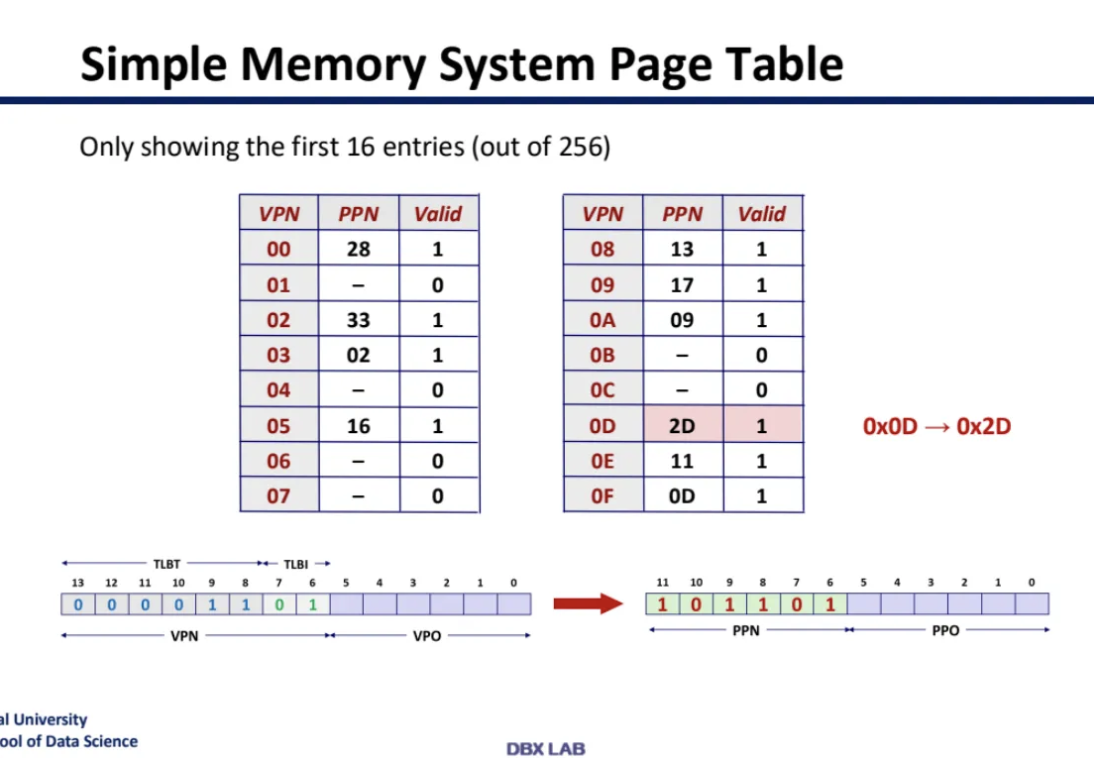
entry가 16개인 4-way associative TLB가 있다고 하자
여기서 VPO는 ignore 된다고 한다
4-way associative니까
한 set 당 line은 4개고 entry는 위 ppt slide처럼 되어있다고 한다
set이 4개니까 set index는 2비트가 되고
나머지 비트는 tag이다
위 예시에서 set index가 01이기 때문에
set 1에 들어가게 되고 valid가 1이고
tag가 일치하기 때문에 hit가 되게 되고
PPN에서 2D를 꺼낸 다음 PPO(VPO)와 결합해서
physical memory address가 된다
그 Physical address를 cache에 가져가서
진짜 데이터를 찾게 되는 것이다
위에서 설명했던 것을 다시 표현해놓은 것이다

CI는 Cache Index를 뜻한다
이 cpu cache는 directed mapped(one-way associative) 구조이고
총 entry가 16개이다
따라서 set index는 4개이고
나머지를 tag bit로 사용하게 된다
cache가 hit의 과정은 우리가 이전 시간에 배웠던 그대로이다
따라서
CPU virtual address -> TLB look up -> L1 cache
이 과정에서 전부다 hit이 된다면
사실상 memory에 접근할 필요도 없게 된다

아무튼 virtual address가
0x03D4와 같은 형식으로 주어지면
TLB를 거쳐서 hit하게 되었으니까
아래와 같은 physical address로 변환되게 된다
set index -> 11이므로 4번째 set에 찾아가고
거기서 tag bit가 000011이기 때문에 TLB set3의
03과 동일하고 valid bit가 1이므로 이건 Hit이 된다
그럼 PPN인 0D를 뽑아낼 수 있는 것이다
그런다음 앞에서 설명했듯이
0D(PPN) + VPO(PPO) 이렇게 결합해서
최종 physical address가 위와같이 되는 것이다
VPO는 PPO와 동일하다고 생각하면 된다

intel의 core i7의 구조이다
TLB 구조를 살펴보자
TLB entries가 4개밖에 안된다
이건 laptop에 들어가는 아키텍처이기때문에
TLB가 작게 설계되었다
VPN이 36, VPO가 12가 들어왔다
우선 TLB로 보내는데 이게 hit이 되면
PPN+PPO로 physical address를 알아내
L1 cache에 보내게 된다
여기서 L1 cache가 hit되면 main memory에 접근할 필요도 없이
끝!
이 되게 되는데 만약 cache miss가 뜨면
main memory에 들어가서 해당 데이터를 찾아오게 된다
TLB의 경우 miss가 발생하게 되면
page table에 들어가서 직접 physical address를 찾게되는데
가장 처음 base address는 CR3(Control Register 3)가 갖고있다
이때 context switching이 발생하면
CR3가 0이 되고 TLB 전체가 flush된다

page table entry안에는
실제로 이렇게 다양한 field들이 존재한다
여기서 한 가지만 짚고 넘어가자면
PS인데
이 PS가 0인지 1인지로
다음 table로 더 들어가야하는지 아닌지를 확인한다
PS에 1이 켜지는 순간 그 다음 translation이
마지막 단계인걸로 파악하게 된다