본 게시글은
서울대학교 데이터사이언스 대학원 이상원 교수님의
데이터사이언스 응용을 위한 빅데이터 및 지식관리시스템 수업을
학습을 목적으로 재구성한 글입니다
본 수업에서는 중간고사 이전까지는
DB users로써 알아야 할 기본적인 내용에 대해 배운 다음
중간고사 이후부터는
DBMS라는 것이 내부적으로 어떻게 동작하는지와
인공지능 시대에 hot한 vectorDB,
그리고 NL2SQL의 개념에 대해서도 배운다고한다
OT 수업인만큼 DB는 왜 배우며
DB의 역사에 대해서 강의해주셨다

DB는 왜 배울까?
Data Processing은 인류에게 왜 중요할까?
농경사회에서는 이미지나 패턴을 파악하는 것이 중요했다고한다
그러나 농경사회가 끝난 이후에는
숫자를 기반으로 하는 어떤 data가 중요해졌고
이러한 숫자 기반의 data processing system이 갖춰져야
문명이 발전할 수 있었다고한다
오른쪽의 그림 사진들은
예전의 수기 data table 내용이라고 한다

비록 시대가 인공지능 시대로 접어들고있다고 하지만
21세기에도 DB를 잘 관리하는 것은
매우 중요하다고 한다
생성형 AI가 장악하는 이 시대에서
DB는 현대 문명의 초석같은 존재라고한다
이러한 DB가 현대 사회에서 어떻게 사용되는지 알아보자
OLTP(Online Transaction Processing)
우리가 일상에서 쿠팡에서 물건을 구매한다거나
기차를 예매한다거나 할 때
이 모든 것은 transaction이다
우리는 하루에도 수많은 transaction을 유발하며
OLTP는 온라인 상에서 transaction을
처리하는 시스템을 말한다
DB에서 가장 중요한 시스템 중 하나이며
ERP/CRM/SEM/BSC와 같은 것들이 있다
OLAP
쌓여있는 data들을 이용하여 분석하는 것을 뜻한다
Data Warehouse, Data Mining과 같은 것들이 있다
Web Log Analysis
개발을 해본사람이라면 알겠지만
웹 또는 앱을 만들 때 user의 모든 click이나
모든 동작을 log로 기록해둔다
이렇게 log를 쌓아둔 다음
user actions을 분석한다
Google, Facebook, Twitter, Naver와 같은
Big Tech 기업들도 이러한 작업을 하고있다
Mobile
Mobile App 내부의 DB의 경우
SQLite라는 DB를 사용한다
이외에도 공간정보를 저장하는 spatial database
(내전공...)
과학적 데이터를 저장하는 scientific database도 있다
또한 제조업에서 모든 생산 및 제조 기록을 관리하는
MES도 있다

이러한 DB를 좀 더 효율적으로
성능을 upgrade시켜 사용하는 것을
tuning이라고 하는데
이러한 tuning은 왜 중요할까?
data의 양은 매우 증가하고있고
이러한 큰 data를 DB에 담아두고 관리할 때
DB의 속도가 빨라져야한다
이를 위해 tuning이라는 과정을 거치게 된다
실제로 쇼핑몰에서 SQL을 튜닝한 뒤
매출이 증가했고
경매 사이트에서 index를 없애자 수익이 감소했다고한다

옛날 얘기일 수 있지만 Database를
왜 효율적으로 사용해야하는지에 대해 알아보자
요즘 데이터 개수가 굉장히 늘어나면서
database에 가해지는 load도 매우 커지고있다
이러한 이유로 관리를 효율적으로 해주는 것은
매우 중요하다
위 ppt에서 fig가 하나 있는데
이는 DB를 관리하는 컴퓨팅 시스템에 비해
관리해야하는 data의 복잡도나 양이 더 증가하고있음을
보여주는 fig라고 한다
(많이 옛날 얘기라고하셨다)
아무튼 이렇게 데이터의 양이 늘어나고있기 때문에
데이터를 저장하는 database를
효율적으로 사용하는 것이 중요하다고 한다

최근의 Database 동향을 잠깐 소개해주셨다
지금까지 전통적인 DB는 관계형데이터베이스(RDB)였지만
2000년 무렵에 전통적인 DB가 아닌 새로운 형태의 data system을 개발했다
Big-Data, MapReduce, Hive 등등이 있다
또한 NoSQL의 개념이 나왔는데
전통적인 SQL의 개념을 탈피하는 것으로
RocksDB, MongoDB와 같은
NoSQL의 대표주자들이 등장하였다
또한 MapReduce가 발전을 해서
우리가 한 번쯤은 다 들어봤을
MapReduce -> Hadoop -> Apache Spark -> Spark SQL
의 순서로 발전을 거친다
이렇게 최근에 전통적인 DB로부터 많은 변화가 일어났지만
SQL이라는 개념은 여전히 중요하다고 한다
그 이유는 SQL은 DB의 interface이고
아무리 DB가 변하고 있어도
DB의 interface로써 SQL의 중요성은
모두가 동의하고 있다고 한다
Big-Data가 등장하면서 새로운 방향들이 계속 제시되고있고
최근에는 PostgreSQL이 시장에서 인기가 많아지고 있다고 한다

PostgreSQL이 왜 인기가 많은지에 대해
간단하게 설명을 하자면
PostgreSQL은 만들 때부터
확장성을 염두에 두고 만든 DB라고 한다
새로운 기능이 필요할 때 새로운 기능을
어느정도 자유롭게 추가할 수 있으며
데이터를 다루는 웬만한 기능들을
extensible하게 갖고 있다고 한다

2022년에 IEEE에서 제시한
취업 잘되는(?) 언어 순위라고 한다
(SQL이 1등이란걸 강조하고싶으셨나보다 ㅎ,,)
그렇다면 이제 본격적으로
DB의 역사에 대해 배워보자
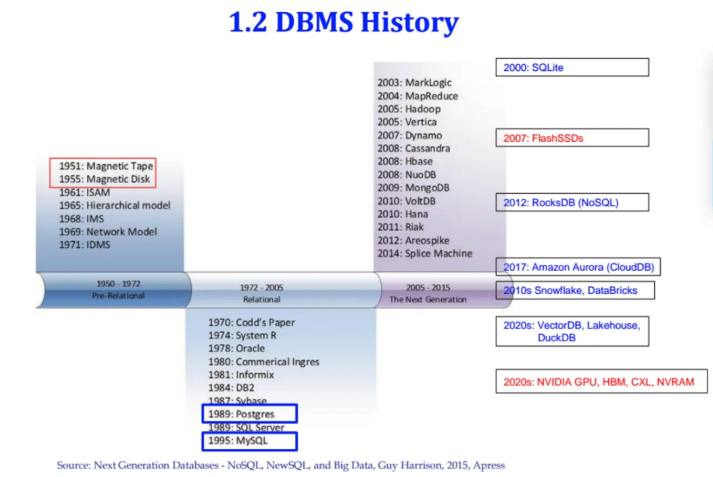
1950년도에는 Magnetic Tape가 저장장치로 사용됐었다
몇 년 뒤에 IBM에서 Magnetic Disk라는
하드디스크를 개발했다
이후에 data를 중점적으로 다루는 시스템이 필요하다고 생각되어
1960~1970년대에도 꾸준히 DBMS는 개발이 되었고
1970년대 초반에 IBM에서 RDB에 대한 초석을 개발하였다
Codd라는 박사가 쓴 논문을 기반으로
IBM에서 SystemR이라는 DB를 개발하였고
이를 바탕으로 현재까지 짱짱한 Oracle이라는 회사가 설립되었다고한다
1980년대 후반에 Postgres가 개발되었고
1995년에는 Postgres와 opensource로
양대 산맥인 MySQL이 개발되었다
2000년 무렵에는 모바일 특화 DB인 SQLite가
2012년에는 NoSQL의 대표주자인 RocksDB가 개발되었다
또한 2007년에 주목해야 되는 점이
2007년 이전까지만 해도 DB입장에서
유일한 storage는 하드디스크였다고 한다
하지만 2007년 FlashSSD의 개발로
훨씬 더 DB의 속도가 증가하는 계기가 되었다고한다
2017년에는 Amazon에서 Aurora라고 하는
Cloud의 DB시스템을 출시하였다
(CloudDB의 발전)
이 Aurora에서 재밌는 점은
Aurora는 opensource인 MySQL인데
이걸 Amazon 자사에서 cloud 서비스로 제공하는 것이라고 한다
믿거나 말거나지만 당시 아마존에서
수익성이 가장 높은 부분 중 하나였다고 (,,,)
2010년대에는 큰 데이터를 분석하는 시스템으로
Snowflake, DataBricks가 개발되었고
현재인 2020년대에는
vectorDB나
snowflake나 DataBricks같은 시스템들이
Cloud에 있는 큰 storage를 Lakehouse라는 시스템으로
발전시키고 있다
또한 data mining 용도인 opensource DB인
DuckDB도 개발되었다
이제 DB 역사에 한 획을 그은 위인(?)들을 알아보자

1950년대에 주로 활약하셨던 분으로
data를 별도로 관리해주는 software가 필요함을
가장 처음으로 주장하셨다고한다
컴퓨터 과학계의 노벨상인 튜링상을 DB계에서 첫 번째로 수상하셨다고한다

앞에서 잠깐 언급됐던 분인데
Codd 라는 박사가 위 Bachman 박사의 주장을 반박하며
새로운 논문을 냈다

Codd 박사가 발표한 논문인데
data independence라는 키워드로 논문을 작성하셨다고 한다
이분도 2번째 튜링상을 수상하셨다

Codd 박사님의 논문을 바탕으로 IBM에서
SystemR을 개발하였고
이는 최초의 관계형데이터베이스시스템(RDBMS)이다

IBM에서 SystemR을 만든 분들이라고 한다
Jim Gray 박사는 세 번째 튜링상을 수상하셨고
Don Chamberlin 박사는 SQL을 최초로 만든 분이라고한다
P.Selinger 박사도 쿼리 수행 시
가장 빠른 답을 찾는 연구를 하면서
query optimization의 초석을 쌓은 분이라고한다

Berkeley 대학에서 최초로 Ingres라는 RDB를 개발했다
이후 이 Ingres의 다음 버전으로 나온 것이
Postgres이고 opensource로써 현재도 많은 사랑을 받고있다
이 개발자분도 튜링상을 받으셨다고..

RDB의 역사라고한다

1990년대에 들어와서 RDB의 아쉬운 점들이 제기되면서
객체지향의 컨셉을 활용한
OO-DBMS(Object Oriented-DBMS) 등
여러가지 DB의 컨셉들이 등장하였다
하지만 여전히 RDB가 굳건히 자리를 잡고 있었고
1995년에 Postgres와 opensource 양대 산맥을 이루는
MySQL과 MariaDB가 개발되었다
현재에 들어서면서 Amazon Aurora나
중국 Alibaba의 LegoDB와 같은
CloudDB가 개발되고 있고
앞에서 잠깐 언급했던 인공지능 시대에 맞는
vectorDB 등이 각광을 받고 있다고 한다

현대는 로컬이나 서버에 DB를 두고 쓰는게 아닌
CloudDB의 시대라고한다
위와같은 CloudDB 시스템들이 있다고한다

Data Engineering의 역사라고한다
DB의 역사들을 들으면서
생각보다 흥미로웠다 ㅋㅋㅋ
늘 말로만 듣던 RDB니 하던 것들의
초석을 쌓으신 분들의 스토리를 들으니 재미있는 것 같다
나도 그런 멋쟁이 연구자가 되고싶당 ㅋ
'강의 > database' 카테고리의 다른 글
| [database] Relational Algebra (Division과 Query 예시) (0) | 2025.03.31 |
|---|---|
| [database] Relational Algebra (selection, projection, cross-product, set-difference, union) (0) | 2025.03.24 |
| [database] View와 Materialized View (0) | 2025.03.24 |
| [database] Relational Database(Primary key와 Foreign key) (0) | 2025.03.16 |
| [database] DBMS는 무엇이며 왜 사용할까? (Feat. Data Independence, RDBMS) (2) | 2025.03.12 |