본 게시글은
서울대학교 데이터사이언스대학원 정형수 교수님의
데이터사이언스 응용을 위한 시스템 프로그래밍 강의를
학습을 목적으로 재구성하였습니다

이번 시간에 배울 내용은
linux 운영체제 내에서의 exception control flow에 대한 내용이다
이번 수업의 내용은 굉장히 중요한 내용인데
이 내용을 이해를 하지 못하면
이 시스템 프로그래밍이라는 수업 자체를
따라가기가 매우 힘들어 진다고 한다
그래서 교수님께서 이번 수업은 강의 녹화본을 올릴테니
이해가 안가면 갈때까지 영상을 보며 이해하라고 하셨다..
지금까지는 단순히 assembly code와
user program 내에서 어떻게 메모리와 register가 이동하고
어떤 과정을 거치는지를 알아봤다면
오늘 배우는 내용은 지금까지 배우는 내용에서
더 확장된 내용이다
그리고 여기서 말하는 exception이란건
우리가 흔히 코딩할 때 쓰는
try, exception 같은 개념이 아니다
한 마디로 정리하자면,
컴퓨터가 어떤 프로그램을 수행하고 있는데
다른 작업을 어떻게 수행하는지에 대해 담은 내용이고
특정 프로그램이 실행 중인데 다른 작업에 대한 요청이 들어오는 것을
시스템 프로그래밍에서는 exception이라고 부른다
우리가 컴퓨터로 어떤 코드를 실행시켰다
그럼 CPU에서는 해당 instruction을 열심히 수행시키고 있을 것이다
그런데 분명히 우리의 컴퓨터는
코드를 수행시키면서 우리가 마우스로 어떤 것을 클릭하면
그것에도 반응하고
키보드로 뭔가를 타이핑하면 그것도 그대로 받아들인다
이것이 어떻게 가능한걸까?
우리가 만약 마우스를 움직이게 된다면
그 마우스에 대한 신호는 CPU까지 가게 된다
보통 전기전자 쪽에서는 "핀을 켠다"라고 얘기를 하는데
와이어에서 핀을 켜면서 마우스 전기 신호를 CPU에게 준다
CPU는 모든 Instruction을 수행하면서
마우스와 같은 핀이 켜져있는지 아닌지 체크를 한다
그렇게 체크하다가 핀에 신호가 들어오면
어느 핀인지를 체크한 다음 해당하는 미리 운영체제가 정의해놓은
핸들러를 찾아서 수행한다
그런데 이건 어떤 작업을 수행하는 중간에
갑자기 넘어가는 것과 동일하다
그래서 핀이 켜지게 되면 그 상태의 cpu를
register와 return address를 고대로 저장한다
그리고 주변 장치의 event에 맞게 작성된 handler로
가기 위한 준비 작업들을 수행하는데
save를 하고, 운영체제의 kernel stack에 접근하고..
등과 같은 작업들을 수행한다
이러한 일련의 과정을 exception control이라고 한다
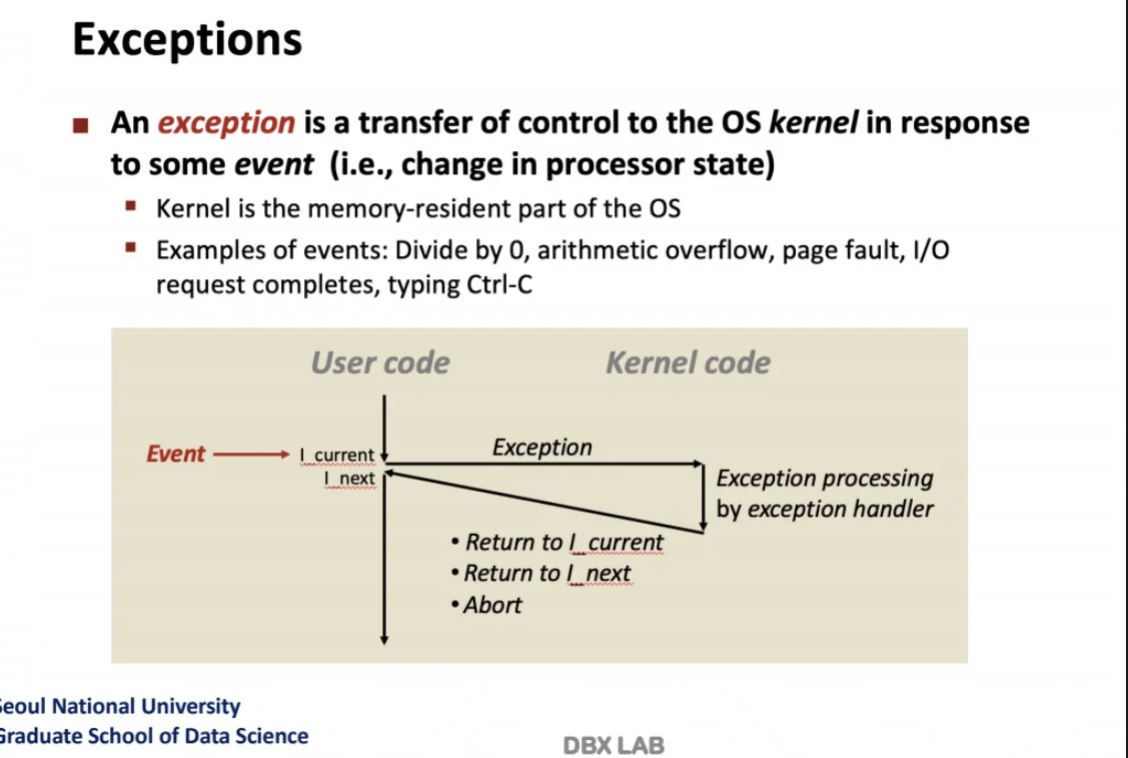
exception의 정의이다
내가 지금까지 어떤 프로그램을 수행하고 있는데
외부에서 event가 들어올 때 처리하는 것을 말한다
이것을 처리하는 코드는 os에서 handler로 이미 구현되어있다
우리는 내부에서 우리가 실행시킨 user code를 작동시키다가
외부 event pin이 켜지면
코드를 멈추고 current, next instruction과 관련된
register를 모두 저장한다
그런 다음 exception으로 가서
exception processing by excpetion handler를 수행시킨다
그다음 결과를 return 해주고
다시 원래의 user code돌아가서 아무일도 없었다는 듯이
수행을 계속한다고한다..
이렇게 하는게 user 모드에서 os 모드로 왔다갔다 하는 것인데
이렇게 모드를 변경하는 것을 mode switch라고 한다
뒤에 context switch도 나오는데
mode switch와 context switch는 확연히 다른 내용이다
그리고 이러한 것을 exception이라고 부르는 이유는
우리의 컨트롤과 상관없이 넘어가는 것이기 때문이다
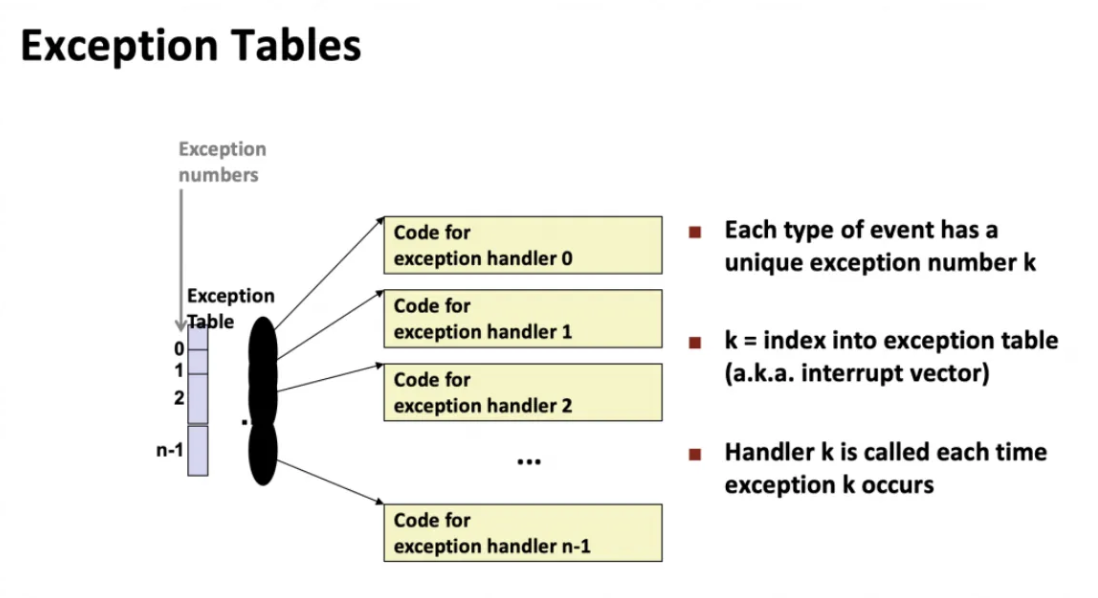
exception을 위해서 exception table이라는 것이 존재한다
interrupt description table(IDT)라고도 부르는데
이 테이블은 처음에 우리가 컴퓨터를 부팅하는순간 생성된다
번호에 따라서 이미 만들어진 함수의 주소를 담고있고
예를 들면
0번은 timer 관련 핸들러
1번은 마우스 관련 핸들러
2번은 SSD 관련 핸들러
3번은 network 관련 핸들러 등..
그걸 CPU 핀에 날라오는 와이어의 number를 보고
몇 번 Handler를 불러야할지 결정하는 것이다
이걸 하게해주는 하드웨어가 있는데
PIC(Programmable interupt controller)이다
주변장치에서 신호가 들어왔을 때
PIC에 의해서 CPU의 pin에 해당하는 number를 정확하게 가져올 수 있다
그런 다음 현재 동작하고 있는 context를 save 시킨다
그러고 exception table 안에 들어있는
function pointer에 있는 코드로 점프해서
코드를 수행하고 다시 돌아온다
모든 CPU는 IDT를 빠르게 찾아가기위해
IDT의 base pointer를 항상 가리키고있는
register를 갖고 있는데 이를 IDTR register라고 한다
user mode에서 IDTR을 핸들링하려고하면 프로그램이 바로 죽어버리고
운영체제가 처음에 부팅할 때만 세팅할 수 있는 레지스터이다
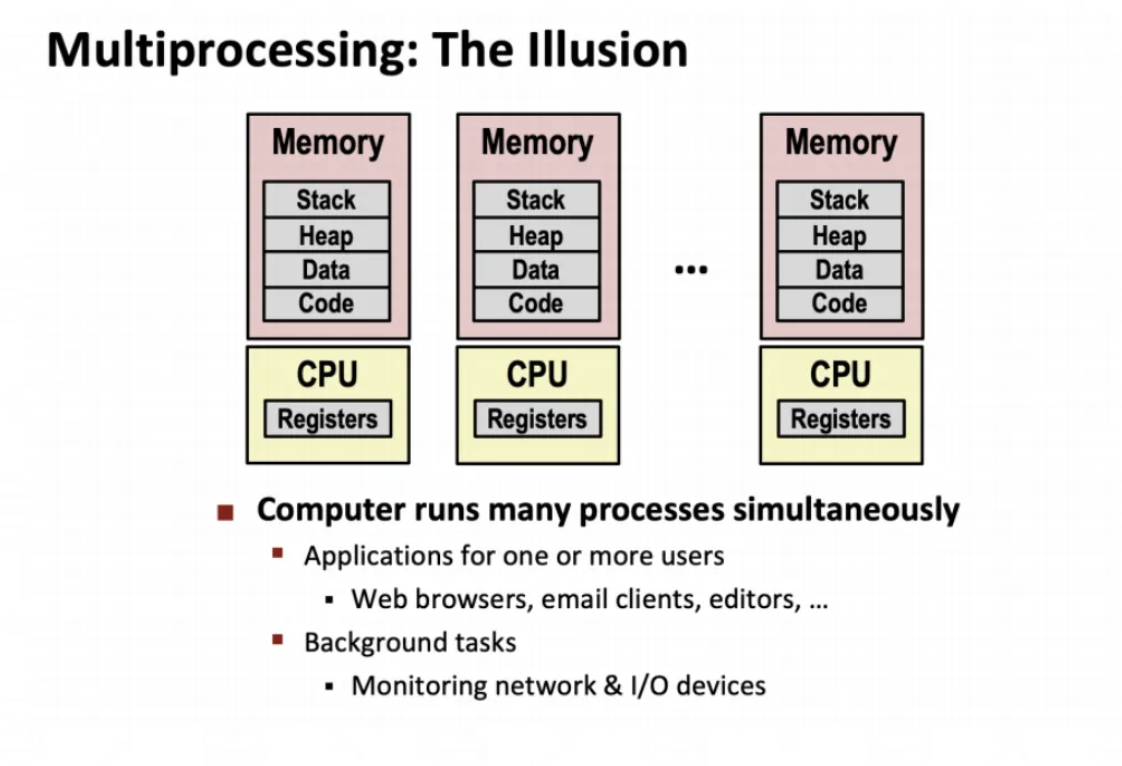
이번 수업의 가장 첫 OT 때부터 교수님이 강조해왔던 내용..
htop을 다운받아서 terminal에서 htop을 실행시켜보면
현재 프로세스가 굉장히 많다는 것을 알 수 있다
하지만 우리는 그냥 한개의 프로세스가
CPU를 혼자 점유하고 있는 것처럼 느껴진다
프로그램이 실행되려면 메모리 영역에는 stack, heap, data, code가 있어야하고
CPU에는 register가 있어야한다
하지만 CPU는 물리적으로 제한이 되어있는데
어떻게 여러 가지 프로세스를 실행시킬 수 있는걸까?

매 순간에 core가 1개밖에 없다면
내가 실행할 수 있는 프로그램은 한 개 뿐인 것이다
그럼 나머지 프로그램들은 다 멈춰있어야하는데
그래서 현재 동작하고 있는 프로그램에 대해 캡처하는
추상화(abstraction)이 필요해진다
이걸 process라고 부르는 것이다
다시 한 번 process의 정의에 대해서 설명하자면
현재 동작하고 있는 running program에 대한 추상화이다
현재 동작하고 있는 프로그램이 무엇인지를 알아야
잠깐 이 프로그램을 멈추고 다음 프로그램을 실행시킬 수 있다
그 프로그램이 뭔지 알아야하는게
memory와 CPU의 state이다
따라서 process는 결국 memory + CPU의 state가 되는 것이다
그래서 결국 core가 1개더라도
동작하고 있는 program을 추상화해서 process를 생성한다
그래서 이 process를 왔다갔다 돌아가면서 수행시키기 위해
전부 save시키고 restore하는 과정을 반복해서 동작시키기 때문에
각각의 프로그램을 돌아가면서 돌릴 수 있는 것이다
이런식으로 결국 컴퓨터는 한 번에 한개의 연산밖에 수행을 못하고
이걸 멈추고 다시하고 멈추고 다시하고의 과정을 통해서
여러 개의 프로그램을 실행시키고 있는 것인데
우리는 컴퓨터가 모든 프로그램을 동시에 실행시키고 있다고 착각을 한다
이게 바로 os에서 가장 중요한 개념인 illusion이다
그런데 프로세스와 프로세스 사이의 term을 얼마나 가져갈지는
아직까지도 딜레마라고한다
term을 짧게 가져가면 사람은 눈치재지 못하지만
save와 restore의 횟수가 많아지기 때문에
나중에는 프로세스 수행 시간보다
save와 restore에 사용하는 시간이 더 많아질수가 있다
그렇다고 term을 길게 가져가면?
사람에게 illusion을 가져다주지못한다

이건 multi core procerssor에 대한 설명이다
main memory와 cache memory를 공유하면서
여러 개의 별도의 process를 실행시킬 수 있다

macOS 기준 shell에 접속해서 명령어를 치는걸 생각해보자
우리가 가장 많이 사용하는 명령어인 ls를 예시로 생각해보자
shell에 ls를 치고 엔터를 치면
shell이 우리가 입력한 명령어로 process를 생성한다
원래라면 shell은 process를 생성하고
command가 끝날 때 까지 기다리게 되는데
명령어 끝에 &를 붙이면 background에서 실행시킬 수도 있다
이걸 타임라인 그래프로 표현해보면
A조금 수행하고, B조금 수행하고, C조금 수행하고..
이런 과정을 반복한다
이걸 time sharing이라고 하는데
1960년대에 unix timesharing system이라는 논문이 나왔고
이 timesharing system은 아직까지도
가장 대표적인 방법론으로 사용되고있다
timesharing을 당시에 개발자들이 assembly code로 개발하다가
너무 힘들어서 만들게 된 언어가 바로 c언어라고한다
한마디로 원래 운영체제를 개발하기 위해서
만들어진 언어인 것이다

운영체제의 핵심 동작이 아까 앞에서 말했던
illusion과 virtualization이고
이걸 가능하게 해주는 핵심 개념이 바로 time sharing이다

cpu virtualization의 핵심은 program을 process로 추상화시키는 것이다
그러고 이 process는 memory와 cpu로 구성되어있다
cpu register set을 운영체제가 들고 있다가
멈췄을 때 다 저장해버린다
그런 다음 다시 restore을 수행하는데 이건
우리가 앞에서 배웠던 move로 수행한다

이게 CPU의 상태인데
이걸 abstracting 해줘야한다
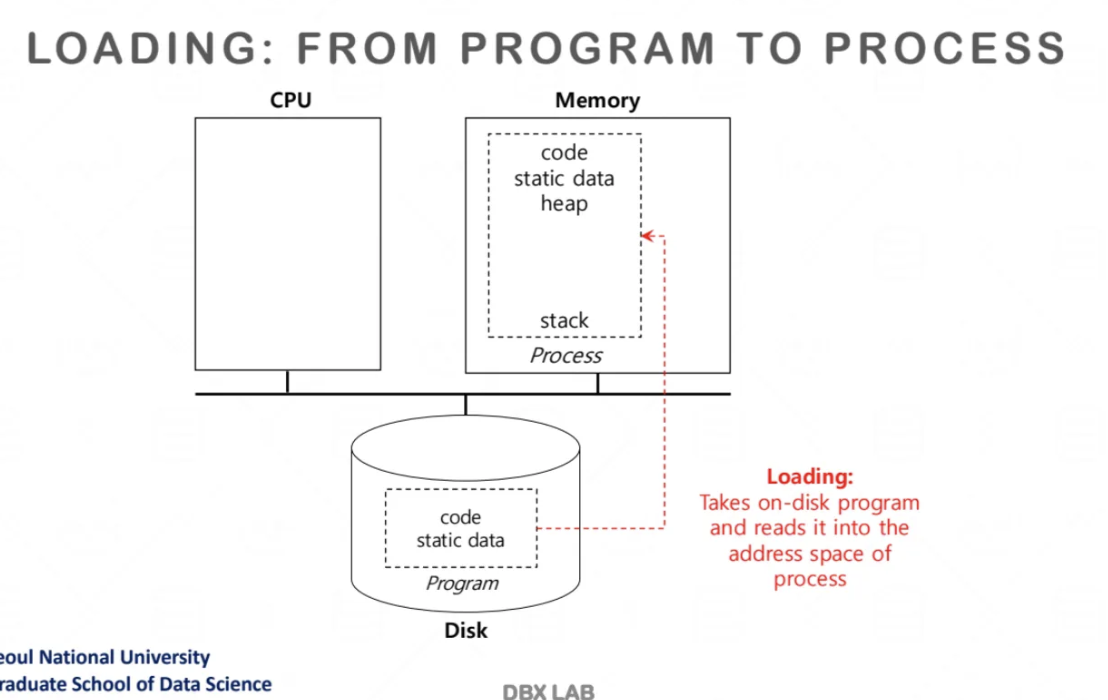
우리가 shell에 command를 치는 순간
내부에서 process를 만든다
프로그램을 올릴 때 라이브러리가 있는 경우
linker가 라이브러리들 모두 memory 영역에 올려준다
그리고 그 안에서 어떤 함수가 어디에 있는지
메모리 주소를 해당하는 function에다가 적어준다
이걸 Linker loader라는 친구가 수행한다
이 작업을 다 끝내고 마지막에 start main이라는 address를
%rip에 적어주면 program이 시작되게 된다
이걸 process start라고 한다

이제 구체적으로 shell이 어떻게 Process를 만드는지 살펴보자
(원래 학부생 수업에서는 shell을 직접 구현해서 만드는 것만
2주에 걸쳐서 수행한다고한다)
process를 수행할 때 첫 번째로 하는 일은 fork라고 한다
fork는 새로운 child process를 만드는 작업인데
fork를 수행하면 shell이 한 개가 더 생성된다
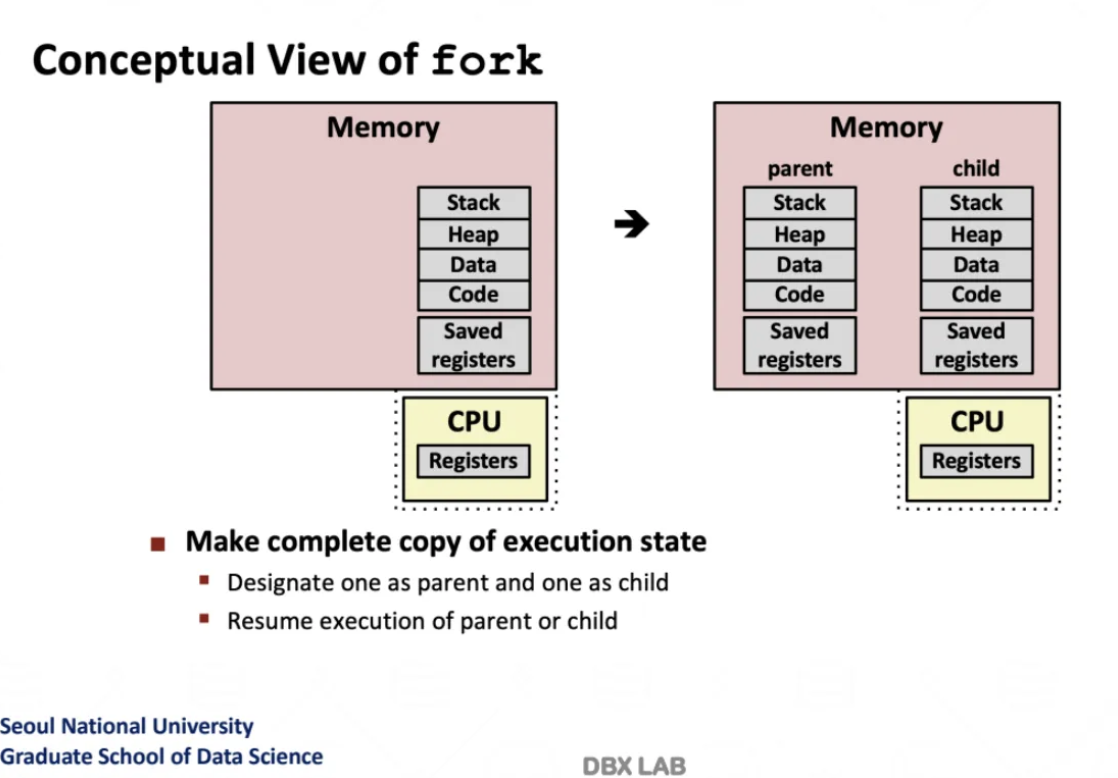
fork 명령어를 수행하면 shell이 한 개 더 생성되고
원래 있던 구조와 똑같이 복사한다
그래서 fork 수행 후에는 그냥 shell이 한 개 더 생기는 결과가 나온다

이 fork가 끝나면 execve라는 것을 수행하는데
fork를 실행하면 return value는 2개가 나온다
첫 번째는 fork를 실행했던 부모 process
그다음은 새롭게 생성된 child process이다
부모의 pid는 child의 pid이고
child의 pid는 0이다
이렇게 pid를 확인해서 어떤 것이 child process인지 확인한다
위 ppt에 linux에서 fork를 실행했을 때
parent와 child의 결과가 예시로 나와있다
parent와 child의 순서는 그냥 마음대로라고한다
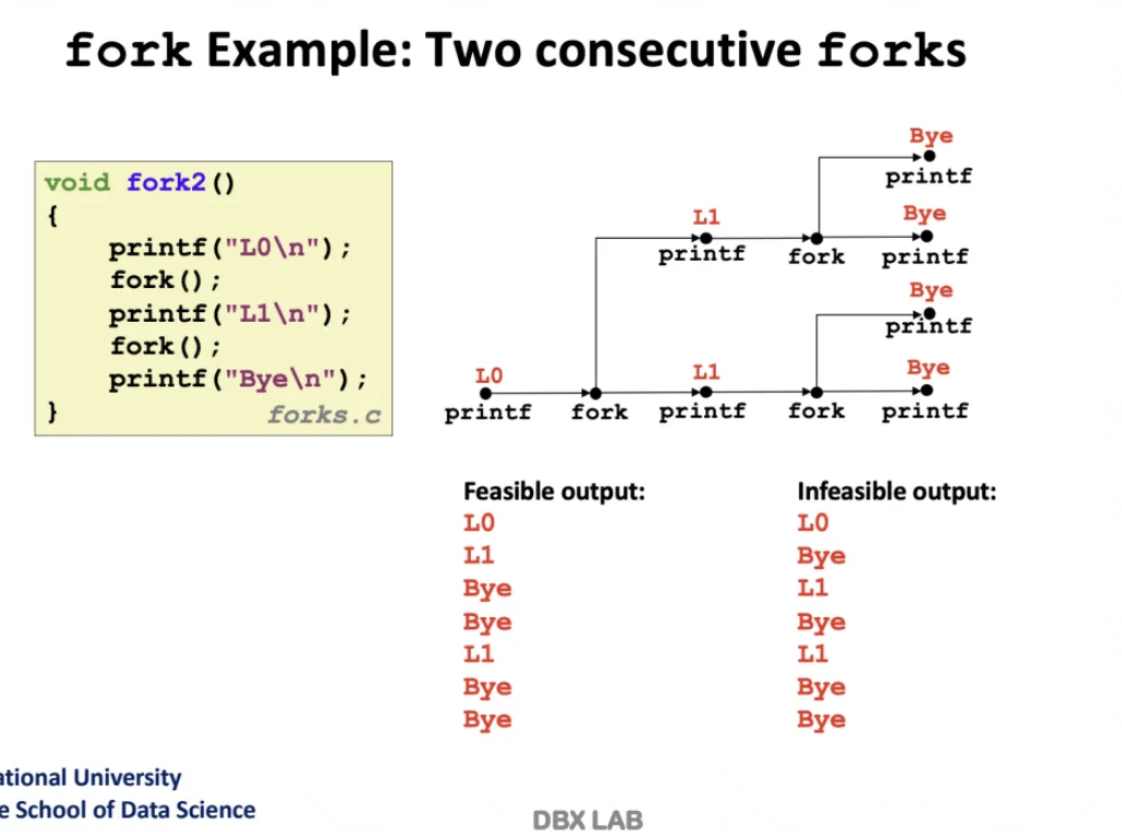
위 코드를 통해 예시를 살펴보자
맨 처음에 L0을 출력하고 fork를 한다
그럼 shell이 한 개 더 생성되면서
부모도 L1, 자식도 L1을 출력하게 된다
거기서 또 각각 fork를 수행하게 되기 때문에
총 4개의 process가 만들어지고
Bye는 4번이 출력되게 된다
이 4개의 process는 fork 명령어를 통해
고대로 복사된 것이기 때문에
모두 똑같은 memory 상태를 가진다
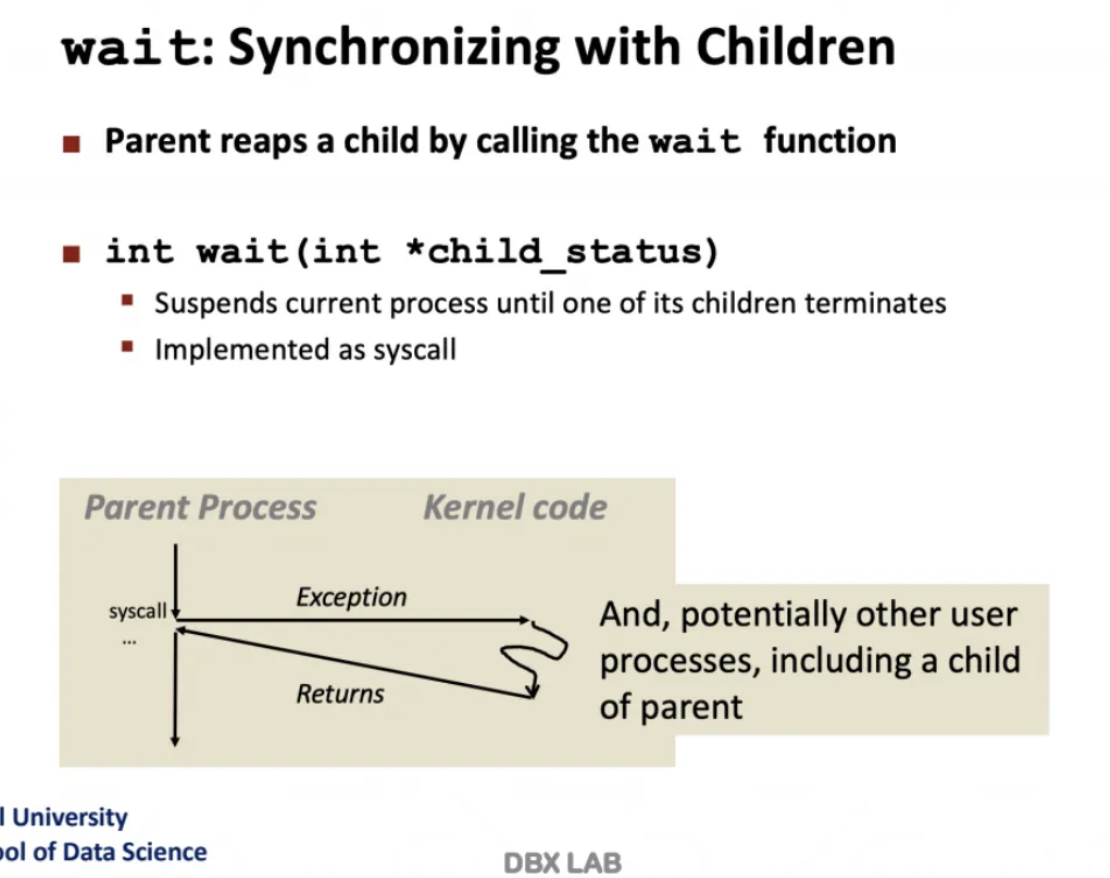
fork를 했을 때 자식이 너무 많아지면 안되기때문에
wait system call이라는 것이 있다
fork를 통해서 생성됐던 자식 process가
수행이 완료될때까지 parent는 기다리겠다는 의미이다
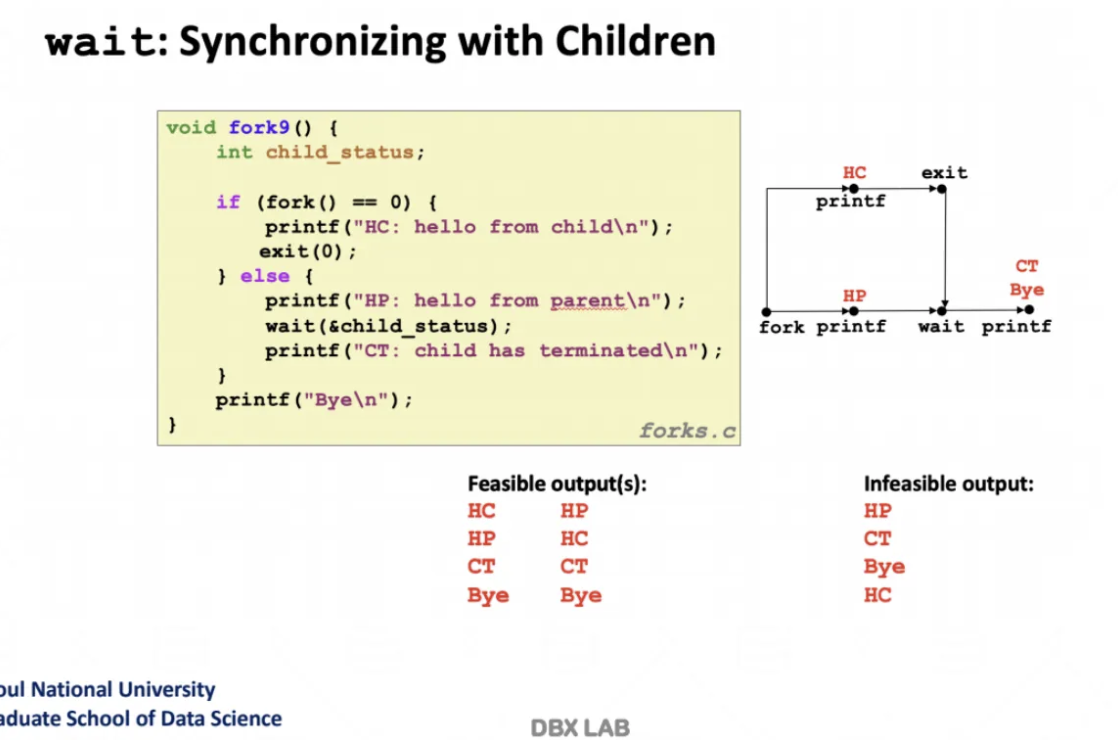
위 ppt의 코드에서 else 부분이 부모의 파트이다
fork를 수행하면 parent와 child가 동시에 수행되지만
parent는 child가 마무리 되기까지 기다린다
fork() == 0으로 child임을 확인하면
hello from child가 출력되고
자식이 exit(0)해서 process를 멈춘다
그럼 마지막 child has terminated 부분이 수행되고
printf의 출력 순서가 정확하게 맞춰지게된다
우리가 쓰는 os의 shell은 이런 과정을 통해 컨트롤을 하고있다

아까 앞에서 잠깐 언급했는데
fork 명령어를 수행한 다음에 수행되는 것이
execve이다
execve의 argument로는 파일 이름이 들어가는데
그럼 현재 fork 되어있는 이 process를
memory와 cpu를 해당 filename에 있는 것으로 바꿔달라는 뜻이다
그래서 드디어 fork해서 새로 복사해서 생성한 shell이
execve를 통해서 내가 수행한 명령으로 바뀌게 되는 것이다
아예 새로 process를 init하는 것이다
fork를 하는 이유는 그냥 새로운 process를 만들
껍데기를 생성한 것이고
execve를 해야지 내가 정말 수행하고 싶은 프로세스로 바뀌는 것이다

결국 우리가 쳤던 이런 명령어들을 모두 담아서
execve가 수행을 시키는 것이다
위 노란색 박스의 코드에서
execve(myargv[0], myargv, environ) 이런 코드를 볼 수 있는데
myargv[0] 이 부분을 실행시켜달라는 뜻이다
그래서 execve가 성공적으로 수행되면 다음 코드는
실행이 될 수가 없다
왜냐면 execve가 성공했다는 소리는
기존에 있던 memory가 모두 변경되었다는 뜻이기 때문에
execve 아래의 코드는 절대로 수행될 수가 없다
execve가 메모리 셋업 다해주고 코드도 올리고
linker loader의 역할도 죄다 다 해준다음
그 다음에 다시 돌아오지 않도록 해준다
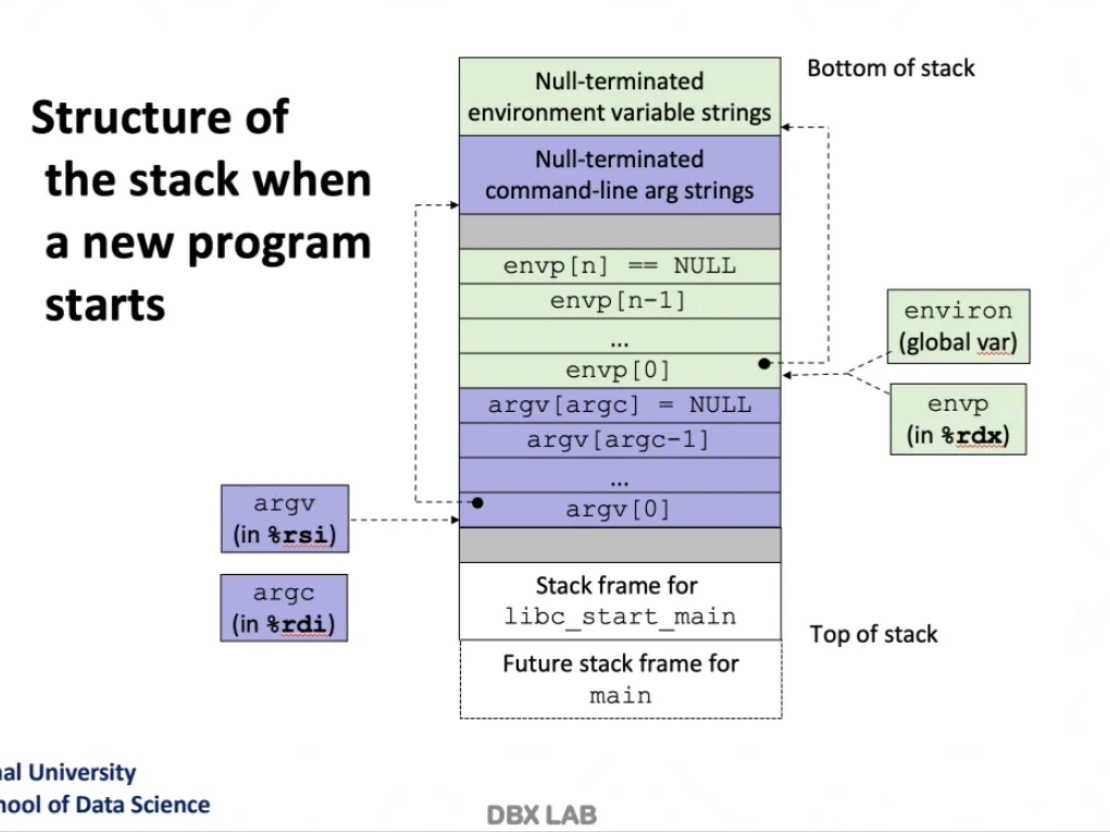
stack 메모리에 모든 것들이 다 저장된다
저 libc_start_main부터 만약 우리가 생성한 process가 ls라고 한다면
main function이 사용될 수 있는 코드들이 셋업된다
현재 current가 무엇인지 argument는 무엇을 받았는지 등을
모두 다 운영체제가 셋업을 해준다
그런다음 libc_start_main을 한 다음에 rip에
이 부분에 Pointer를 던지게 된다
그럼 이제 거기서부터 수행이 시작되는 것이다-!
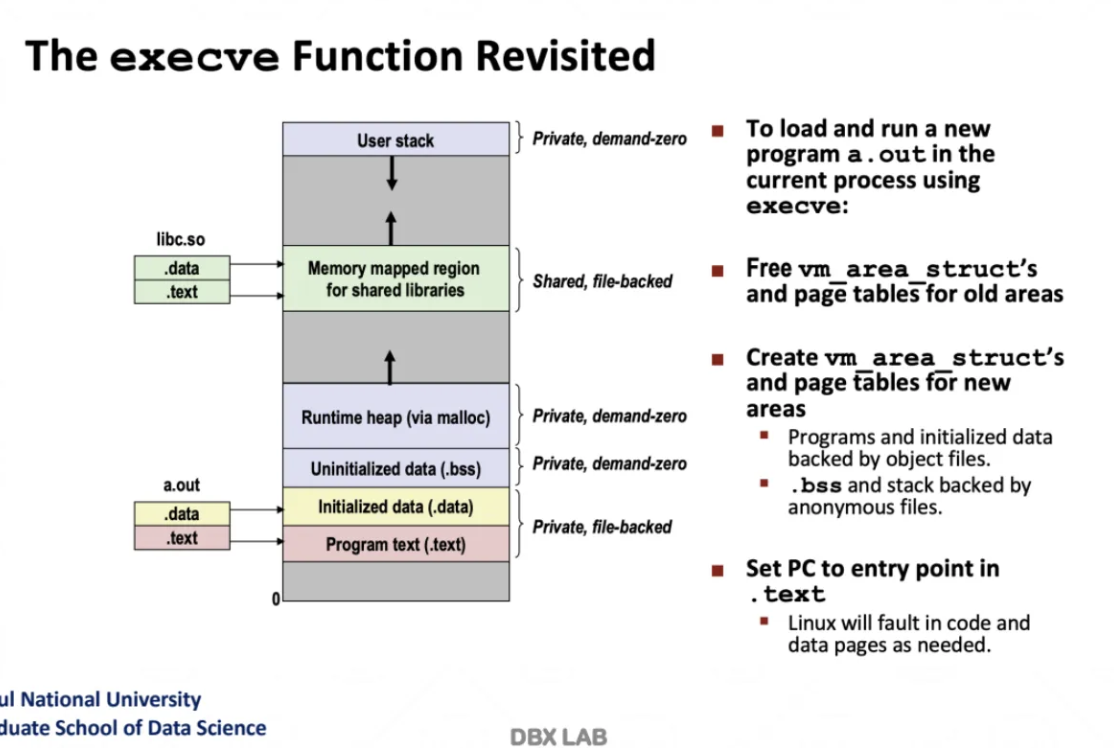
가장 마지막이 program text 코드이고
위 ppt의 그림처럼 환경설정과 셋팅을 전부다 다 해준다음
program text의 시작 주소를 CPU의 rip에 넣어준다
그때부터 process가 run되는 것이다

CPU가 동작을 하고 있을 때는
현재 state를 save 시킬 수가 없다
그래서 CPU가 동작을 멈추게 한 다음 save를 시켜줘야한다
그래서 동작을 멈추게 하기 위한 작업이 필요하다
그러고 CPU를 멈추게하면 뭔가를 저장할 무언가가 필요하다
이걸 운영체제에서 PCB(Process Control Block)이라고 부른다
PCB 안에 메모리가 어디서부터 어디까지 사용하고있고
지난번에 멈췄을 때 CPU의 register 상태가 무엇이고
혹시나 지금 멈추면 register를 어떻게 저장해야할지
register name 등을 모두 기록해 놓는다
linux에서는 이걸 task structure라고 부른다

PCB 내부를 잠깐 살펴보자
PCB 내부에서 context를 담당하는 부분이다
이렇게 cpu의 context를 담아둘 수 있는
변수들이 다 선언되어있다
이미 이전 수업에서 배웠듯이
64비트이면 e가 아니라 r이 들어간다
그래서 이렇게 들고 있으면 running program을
항상 구현할 수 있다고 한다
운영체제 측면에서는 PCB를 그냥 process라고 인식하고
이렇게 save된 A process의 context를
B process의 context로 바꿔주는 일련의 작업을 바로
앞에서 잠깐 나왔던 context switching이라고 한다
당연히 느껴지겠지만 mode switching보다 훨씬 비싼 작업이다

위 코드를 한 번 잘 살펴보자
kstack은 커널 스택이다
exception handling을 할 때 kstack으로 stack을 change한다
이 과정은 mode switching이다
stack이 kernel stack으로 바뀌면
현재 user program이 동작하고 있던걸 저장한다음
mode switching을 해주는 것이다
CPU는 kernel stack을 별도의 register에 기억을 해둔다
user stack을 가리키는 rsp가 있고
kernel stack을 가리키는 register도 존재한다
그래서 프로그램 수행 중 pin이 잡혔을 때
딱 고상태에서 고대로 멈추고
stack change를 하고 변경된 stack에서 작업을 수행한다
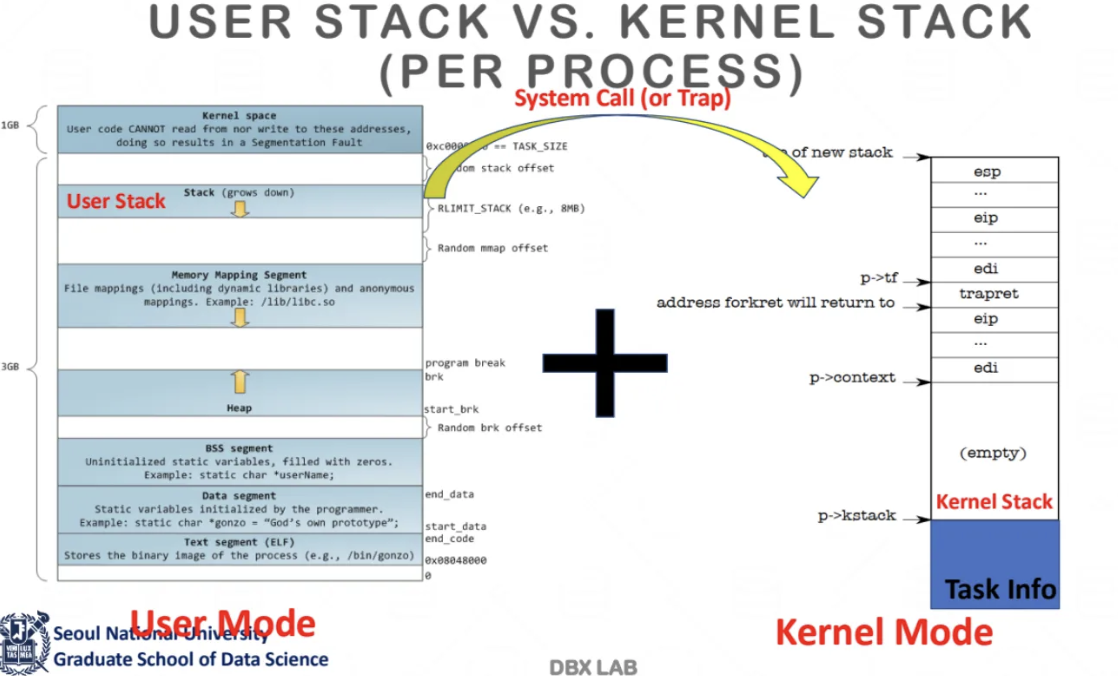
user stack과 kernel stack을 비교한 것이다
user stack은 왼쪽, kernel stack은 오른쪽이다
user stack은 CPU에서 esp 혹은 rsp가 가리키고 있다
user mode에서 kernel mode로 모드를 변경해주려고 하면
현재 CPU의 register 값들을 esp부터 쭈우욱 저장한다
마지막에 현재 user가 동작하다가 멈춰진 그 지점의
다음 지점으로 돌아갈 수 있는 지점인 eip도 저장한다
그러고 나서 stack change를 한 다음
kernel mode로 들어가서 필요한 동작을 수행한다
다 끝나서 다시 return하게 되면 다시 mode를 변경해주는 것이다
실제 내부에서는 위와 같이 구현이 되어있다고 한다

앞에서 말했던 exception table이다
IDTR register는 컴퓨터 부팅부터 영원히 바뀌지 않고
계속 똑같은 곳만 가리키고 있는다고 한다

IDTR register의 모습이다
우리가 마우스를 움직이면 pin으로 number가 기록된다고 한다
그럼 PIC에 신호를 주고
CPU는 그 자리에서 지금까지 수행하던 것을 멈추고
number를 왼쪽의 PIC에서 받아온다
그걸 IDTR를 사용하여 해당 handler 주소를 찾아오는데
number는 보통 32비트 기준 4바이트 단위로 저장이 되는데
number * 4를 하면 해당 handler의 주소로 바로 찾아올 수 있으므로
그런 방식으로 계산된 주소로 이동하고
IDT에서 해당 핸들러를 실행시킨다

위 ppt에서 색이 진한 것들이 CPU의 중요한 register들이라고 한다
오른쪽에 있는 여러 handler function들은
운영체제 개발자들이 구현한 것이다
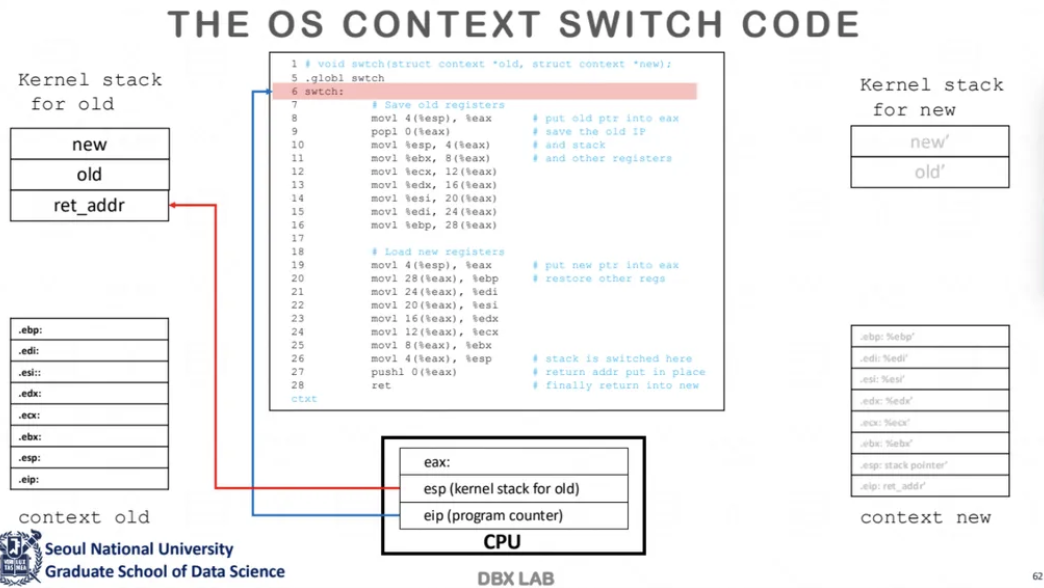
이 부분부터는 context switching이 구체적으로
어떻게 이뤄지는지에 대한 설명인데
시간이 부족해서 동영상 강의를 통해 따로 설명을 해서 올려주신다고한다
ㅋㅋㅋ
아직 영상이 안올라와서 영상이 올라오면
시청해서 공부를 하고 다시 정리한 내용을 올리려고 한다
마지막을 context switching이 비싼 작업인 이유를
설명하고 이번 수업 정리를 마무리하려고 한다
context switching은 A process에서 B process로
memory 영역을 바꿔주는 것인데
원래 동작하고 있던 memory 영역과
새로운 memory 영역은 다른 영역이다
그런데 이걸 바꿔주면 무슨 일이 발생하게 되냐?
원래 동작하고 있던 cache의 content가 단 하나도 안맞게 된다
그럼 cache 메모리에 저장되어있던 데이터를
전부 flush 시켜야 되는 것이다
그래서 context switching이 수행되면
cache memory는 전부 flush가 된다
cache는 core에 존재해서 속도를 빠르게 도와주는 메모리인데
이게 다 flush가 되어버리기 때문에
전부 메모리로 돌아가서 다시 접근해야한다
그래서 context switching을 빈번하게 유발하면
속도가 느려지게 되는 것이다
정확히 말하면 프로그램의 속도가 느려지는게 아니고
memory access가 증가하기 때문에
여기서 유발되는 속도가 느려지는 것이다
아무튼 그렇다고한다..
그렇다면 오늘 수업 내용 정리는 여기까지 -!
다음시간에는 CPU 아키텍처에 대해 배운다고한다