본 게시글은
서울대학교 데이터사이언스대학원 성효진 교수님의
데이터사이언스 응용을 위한 시스템 컴퓨팅 강의를
학습을 목적으로 재구성하였습니다
지난 시간에는 CPU 아키텍처를 배우면서
각 step별 pipelining을 배웠고
이런 pipelining 과정에서 각 단계마다 이쁘게 딱딱 맞아떨어지면 좋지만
실제로는 예외 상황들이 자주 발생해서
각 pipeline step간에 병목이 발생한다
이러한 병목을 hazard라고 하고
이러한 hazard는 주로 data 혹은 control dependency에 의해 발생한다
따라서 hazard를 해결하기 위해 크게 3가지 방법이 있다고 했는데
1. stall
2. bypass
3. speculation
이라고 했다
그 중 stall은 가장 단순한 방법으로
dependency가 해결될 때 까지 기다리는 방식이다
그래서 dependency문제로 기다려야할때는
NOP이라는 아무 의미없는 instruction을 수행시키며
앞의 절차가 완료되어 dependency가 해결이 되면
그때서야 다음 단계로 진행한다
여기까지가 지난 시간에 배운내용이고
이번 시간에는 bypass, speculation을 알아보고
instruction 수행 순서에 대해서도 알아보자

Bypass Logic에 대해서 알아보자
이전 수업시간에서도 살짝 설명을 했는데
bypass는 data hazard 상황에서
이전의 data가 write하는 상태까지 기다리지 않고
그냥 연산이 끝나기만을 기다렸다가
연산이 끝나자마자 바로 데이터를 넘겨주는 방식이다
따라서 bypass는 forwarding이라고도 부른다
이렇게 bypass가 가능하게 하기 위해서는
하드웨어적으로 추가적인 회로가 필요한데
이게 굉장히 복잡하고 추가 비용이 많이 든다고한다
위 그림과 같이 실제로 와이어도 굉장히 많이 연결하고
굉장히 큰 mux들도 필요하다고 한다

사실 컴파일러가 이러한 data hazard를 도와줄 수도 있다
컴파일러가 dependent한 instruction들이 멀리 떨어지도록
코드를 재정렬 할 수도 있는 것이다
위 예시를 보면 R2를 쓰는 SUBC instruction을
가능한 가장 멀리 보내서 stall을 없앤걸 확인할 수 있다

지금까지 배웠던 data hazard 해결 방식을 다시 한 번 살펴보자
첫 번째는 stall인데 이건 그냥 기다리는 것이었다
매우 단순하고 사실상 stall만 해도
모든 hazard를 다 피할 수가 있다
하지만 이는 리소스를 굉장히 낭비하는 방식이며
CPI가 매우 높아진다
그 다음 두 번째는 bypass였는데
이는 새로 라우팅을 해서 기다리는 시간을 줄이는 대신에
비용이 굉장히 비싸다
또한, 아무래도 stall보다는 CPI가 낮아지는건 사실이겠지만
사실상 CPI가 그렇게 극단적으로 낮아지는 것은 아니라고한다
왜냐하면 어짜피 bypass를 해줘도 ALU 단계에서
계산이 되는 것은 무조건 기다려야하기 때문이다
그래서 보통 bypass는 꼭 필요할 때에만 적용하고
나머지는 stall을 하는 방식으로 많이 사용한다
또한, pipeline stage가 많아질수록
hazard의 위험은 더욱 커진다
우리가 앞에서 pipeline stage를 크게 5개로 봤지만
실제로는 한 단계에서도 여러 개로 쪼개진다
그러고 복잡한 계산은 실제로 한 사이클에 못하기 때문에
보통 여러 사이클을 돌리는 경우도 있다
그래서 이걸 따로따로 사이클로 나눠서
execution 단계가 execution 1, execution 2.. 이런식으로
여러 개의 stage로 세분화가 되는 것이다
이렇게 해야 clock time이 더 줄어드는데
왜냐하면 이렇게 쪼개야 instruction들이 더 세부적으로 overlap이 되기 때문이다
이렇게 세분화가 되면 그 instruction들 간에
또 data dependency가 높아질 가능성이 커지게된다

지금까지는 주로 data hazard에 대해서 공부했는데
이번에는 control hazard에 대해서도 알아보도록하자
control hazard는 branch 명령어 때문에
발생하는 pipeline 제어 흐름 문제이다
위 예시와 같이 BEQ 혹은 BNE instruction이 들어오거나
JMP instruction이 들어오면
CPU는 원래 다음 instruction을 미리 fetch해서 기다리는데
해당 조건 수행 결과를 받아오기 전까진
어느 instruction을 fetch해야할지 몰라서 문제가 발생하게 된다

data hazard와 비슷하게
가장 첫 번째 단순한 해결방식은 stall이다
instruction fetch하는 것을 stall 시킬 수 있다
위 예시를 보면 3번에서 BNE가 들어오면서 branch를 한다
하지만 다음에 어떤 instruction을 수행해야할지 모르기 때문에
다음 instruction으로는 NOP을 넣어준다
그런다음 ADDC가 RF stage로 들어오게 되면
해당 branch가 taken인지 아닌지 알 수 있고
위 예시를 보면 branch가 taken 되었기 때문에
다음에 수행할 instruction인 ADDC를 fetch해서 가져오게된다
앞에서 예시로 들었던 위 경우는 사실
branch가 굉장히 간단하기 때문에
큰 비용없이 stall로 간단하게 해결이 가능하다
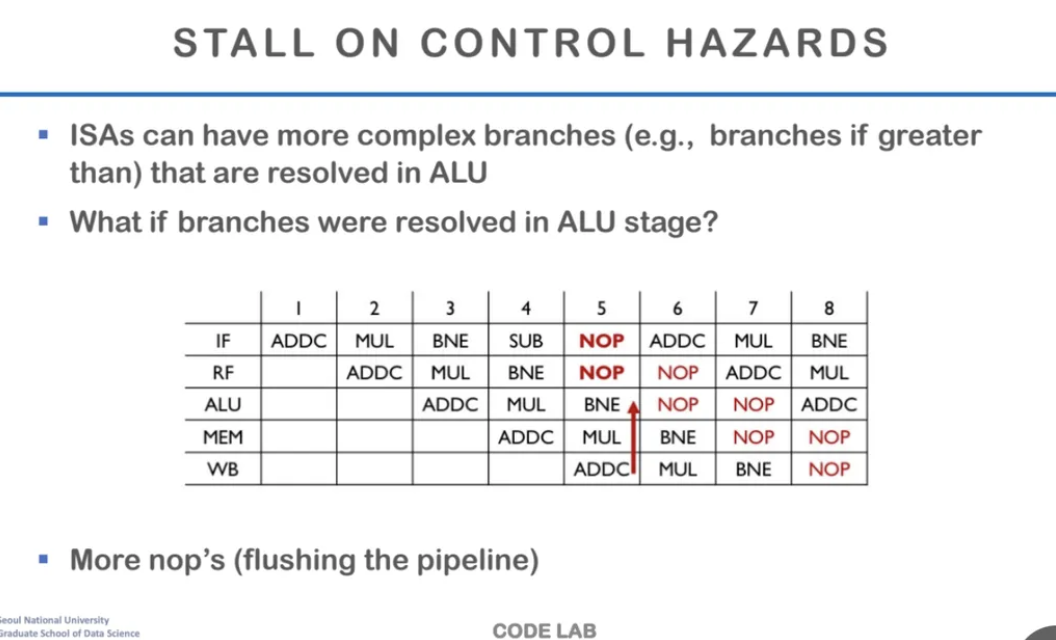
하지만 현실세계의 Instructin architecture은 이렇게 단순하지않다
앞의 예시에서는 RF stage에서 taken여부를 알 수 있었지만
보통은 레지스터를 읽는 것 만으로는 taken인지 알 수 없고
ALU 단계까지 가야 하는 경우가 많다
이런 경우에는 stall을 더 많이 시켜줘야하고
NOP이 더 많이 수행되게 된다
이렇게 NOP이 많이 생기게 되면 결국
pipeline을 flushing해야하는 문제가 생기게된다

따라서 세 번째 방법인 speculate를 수행하게 된다
간단하게 말하면 speculate는 branch의 결과를 예측해서
그에 맞게 수행하는 것이다
만약 예측값이 맞으면 ㄱㅇㄷ으로 그냥 넘어가는 것이고
그렇지 않으면 모든걸 flush하고 처음부터 다시 수행하는
죗값(?)을 치르게 된다
뒤에서 더 자세히 살펴보자
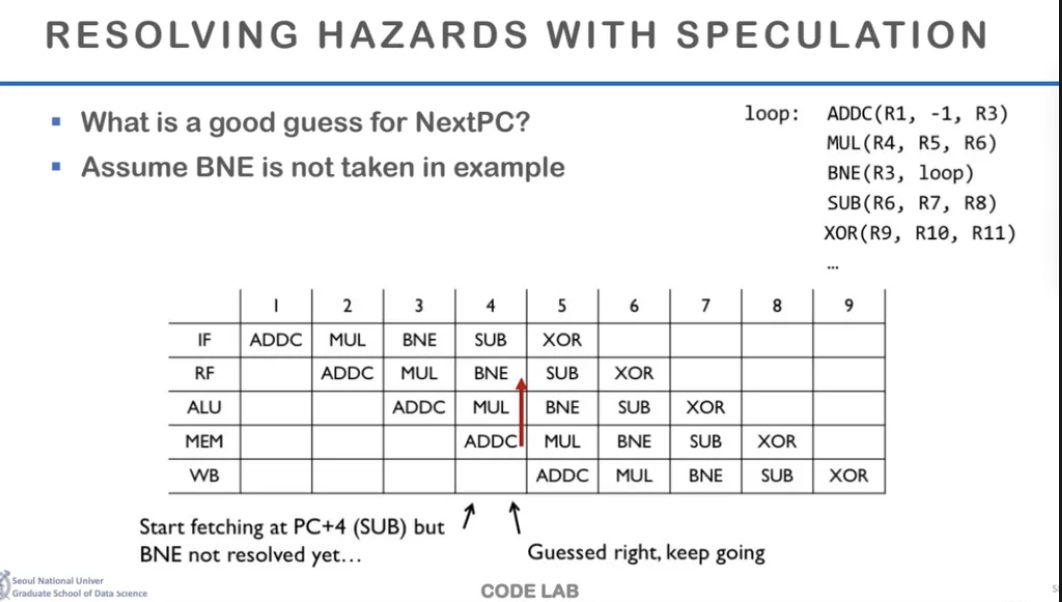
Speculation이란 실행해도 되는지 안되는지 모르는 코드를
우선 그냥 실행하는 것이다
BNE의 결과값도 모르지만 not taken이라고 예측한다음
그럼 Loop를 돌지 않으므로
뒤의 SUB instruction을 수행해준다
만약 이게 맞으면 걍 개이득인것이다
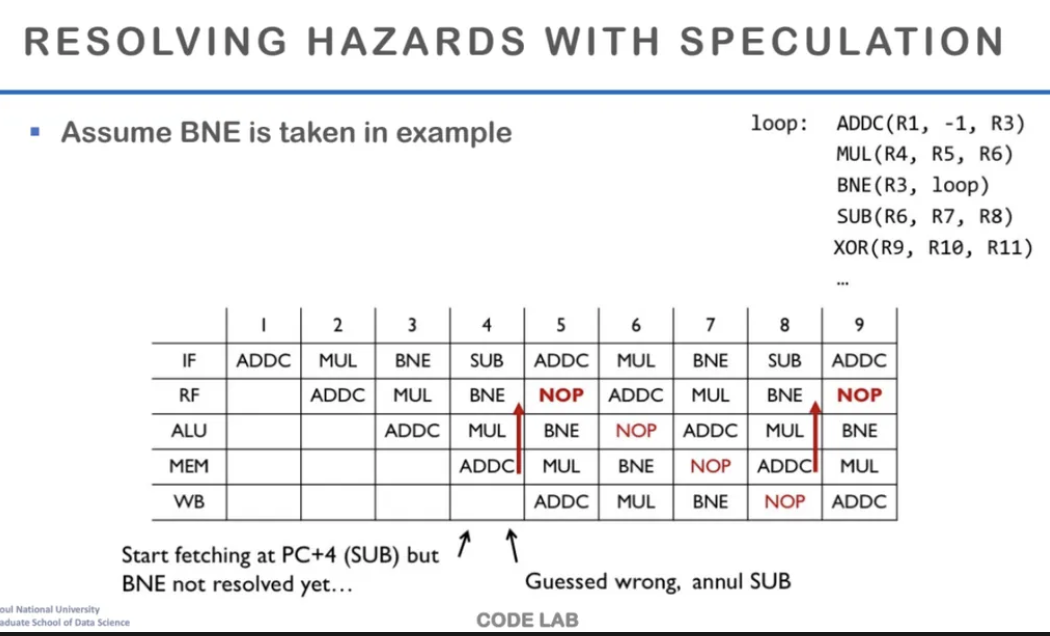
그런데 여기서 만약 예측 값이 틀려서
not taken이라고 생각하고 SUB를 수행했는데
알고보니 taken이었다
그럼 다음 사이클에는 원래 수행되었어야할 instruction인
ADDC가 수행되고,
이전에 수행됐던 SUB는 수행되면 안되므로 NOP으로 바꿔준다
잘못 예측을 했기 때문에 SUB는 flush를 해주는 것이다
예측을 제대로 하면 괜찮은데
만약 그 예측이 틀리게되면 결과를 이전으로 되돌리는 작업이 필요하고
이는 결론적으로 cycle 낭비로 이어진다

이렇게 branch의 결과를 예측하는 것을
branch prediction이라고 하는데
이 branch prediction에 대해서 좀 더 자세하게 살펴보자
하드웨어적으로 단순하게 무조건 모든 branch가
not taken일 것이라고 예측하고 다음을 실행한다고 가정하자
만약 예측이 잘못되었을 때 flush를 하게 되는데
이 때 파이프라인이 길어질수록 훨씬 더 많은 cycle을 낭비하게된다
그래서 현대의 CPU는 이 branch가 taken인지 not taken인지
예측할 수 있는 branch predictor라는 하드웨어를 갖고있다
이전의 branch가 taken인지 not taken인지 history와
해당 branch의 주소를 기록해서 예측모델과 같이 작동하도록 되어있다
우리가 생각하는 그런 머신러닝의 개념이 맞는데
작은 하드웨어이기 때문에 굉장히 단순하게 구현이 되어있다
이렇게 단순한 예측 머신으로 branch prediction이 가능한 이유는
대부분의 branch들은 예측이 가능하도록 행동하기 때문이다
예를들면 Loop같은 경우는
계속해서 taken이 되다가 마지막에는 결국
not taken이 되어야하는 구조이다
이렇듯 지금까지 loop에서 몇 번까지 taken이 되고
언제부터 not taken인지 그 히스토리를 기록하는 것이다
또 taken이 되면 수행해야할 instruction을 따라서 가게 되는데
이때 수행되어야할 Instruction, 즉 target의 주소값도 저장을 해놓는다
이런식으로 지금까지의 branch history와 target 주소값을 이용해서
branch predictor가 간단한 예측을 수행하는 것이다

만약 예측을 하지 않는다면
branch의 값이 나올 때까지 cycle이 낭비가 된다
그럼 branch의 다음 pipeline은 어떤 instruction을 수행하는데
그건 branch의 결과와 아예 상관없는 어떤 instruction을 다음에 넣게 된다
이렇게 하면 flush를 수행할 필요가 없기 때문이다
이런 방식을 Branch Delay Slot이라고 한다
예전에는 많이 사용했던 방식이지만
현재의 CPU에서는 잘 안쓰는 추세라고한다

저번 시간과 이번 시간 지금까지 배운 내용을
간단하게 요약해보자
우리는 기본적으로 지금까지 processor architecture의 pipeline을 배웠다
ISA라는 software와 hardware의 인터페이스가 있고
이걸 바탕으로 실제로 코드가 생성이 된다
현대의 컴퓨터 아키텍처는 폰 노이만 아키텍처를 따르고 있고
이는 PC가 increment하면서 순차적으로 코드를 실행하는 구조이다
보통은 pipeline을 5개의 단계로 구분하는데
한 instruction이 수행될 때 다른 Instruction에 overlap되게 만들어서
CPI가 낮아지도록 만든다
실제로 이런 과정에서 data 혹은 control dependency가 증가하면서
hazard가 많이 나오게 되는데 이걸
stall, bypass(forwarding), speculation과 같은 방법을 통해 해결할 수 있다
우리가 지금까지 배운 이게
inorder pipeline
즉, 순차적으로 실행되는 pipeline에 대한 내용이었다
다음 슬라이드에서부터는 in-order pipeline의 한계와
out-of-order execution에 대해서 배운다고 한다

superscalar와 out-of-order execution에 대해서 배워보자

프로세스의 성능을 측정하는 방식에 대해 알아보자
이전에도 나왔지만 프로세서의 성능은 바로 시간이다
한 프로그램당 실행하는 instruction의 수
instruction 당 cycle의 수
clock cycle을 실행하는데 걸리는 시간 등
이런 걸로 processor performance가 결정이 된다

그렇다면 processor performance에서
우리가 이상적으로 가장 좋은 성능은 무엇일까?
궁극적으로 우리는 CPI가 무엇이 되도록 추구해야할까?
이전에 pipeline stage에서 instruction들을 overlap을 시켰는데
이걸 한 목적은 결국 CPI를 낮추기 위한 것이었고
완벽하게 이상적으로 overlap이 되었을 때
결국 CPI가 1이 되는 것이다
결국 CPI가 1이 되는 것이 가장 좋은 성능이며
우리는 CPI를 최대한 1에 가깝게 만들도록 노력하는 것이다
하지만 실제로 hazard 때문에 CPI가 1이 되기는 힘들다

우리가 앞에서도 배웠는데
stall 때문에 CPI를 이상적으로 1로 만들기는 쉽지 않다
이러한 stall은 data 혹은 control hazard 때문에 주로 발생한다
또, 굉장히 중요한 stall 요인 중 하나로
cache misses도 있다
이전에 어떤 학생이 교수님께 질문을 했는데
1 사이클이 굉장히 짧은데 그럼 cache misses가 발생해서
메모리에 접근하게 되면 굉장히 많은 사이클이 든다고 말씀하셨는데
이럴 때는 어떻게 하냐고 물어봤다고한다
학생의 질문처럼 이 cache misses는
CPI에 있어서 굉장히 중요한 것이고
이게 바로 in-order cycle을 개선할 수 밖에 없는
핵심적인 이유가 된다고 한다
왜냐면 앞에서도 말했듯이 가장 잘 만든 최상의 성능은
CPI가 1이 되는 것이고
1보다 더 작아지는 것은 물리적으로 불가능하다
그런데 cache misses가 발생하면?
이럴 때 우리의 t clock이 모든걸 한 cycle이 되도록
아주 길어지게 만들 수도 있지만
사실 이건 그렇게 현실적인 설계는 아니다
이 stage만 길어지는 것이지
다른 stage는 이것보다 훨씬 짧을 수가 있기 때문이다
그래서 대부분의 in-order pipeline은
single-cycle latency가 L1 cache에 맞춰서 설계가 된다
그래서 보통 1사이클, 많이 걸리면 2사이클 정도에
data를 가져올 수가 있게 된다
이게 가장 일반적이고 최선의 설계인 것이다

그렇다면 어떻게 하면
pipeline stage 측면에서 성능을 끌어올릴 수 있을까?
우선 t clock을 낮출 수가 있을 것이다
이렇게 되면 instruction들을 더 많이 overlap 시킬 수가 있다
하지만 pipeline이 깊어질수록
hazard의 위험은 증가할 수 밖에 없고
그럼 NOP으로 인한 bubble이 증가하게 된다
어쨌든 이상적인 경우에서는
overlap을 할 수 있는 기회를 더 많이 주고
pipeline을 더 잘게 쪼개서 채울 수 있다는 것이다

하지만 위에서 설명한 것처럼
pipeline의 depth를 잘게 쪼개서 깊게 만드는데에는 한계가 있다
이는 앞에서 말한 data hazard의 위험도 있는데
하드웨어적으로도 한계가 존재한다
왜냐하면 앞에서도 봤지만
pipeline stage를 만들려면 사이사이마다
pipeline stage register가 필요하다
이 register가 다음 stage로 control signal과 연산을 전달해주는데
이 레지스터를 세팅하는데도 비용이 든다
또한, 이렇게 사이클이 점점 짧아지면 overhead가 발생하는데
실제로 의미있는 연산을 하는 것보다
레지스터 세팅하고 정보 보내주고하는데에 시간이 더 소비되는 것이다
이러한 overhead는 Pipeline이 생길 때마다
추가되게 된다
결과적으로는 pipeline stage를 계속해서 깊게 만들면
overhead에게 dominate되는 구조가 된다고 한다
그래서 현대의 CPU의 파이프라인은 10개에서 20개 사이를 갖고있다고 한다
frequency가 높아질수록 파이프라인 스테이지가 잘개 쪼개지지만
요즘은 멀티코어가 되면서 상대적으로
frequency에 의해 CPU의 성능이 영향을 덜 받게 되었다고 한다

그렇다면 pipeline을 깊게하는 것 말고
다른 방법으로 CPU의 성능을 높일 수는 없을까?
두번째의 방법으로는 pipeline의 넓이를 넓힐 수가 있다고한다
진짜로 pipeline의 넓이를 넓힌다고 생각하면 되는데
기존에는 한 cycle에는 한 개의 instruction만 처리했다면
wider pipeline을 통해서 한 cycle에 2개, 4개 혹은 그 이상의
명령어를 동시에 처리할 수 있게 되는 것이다
여러 개의 연산을 할 수 있는 unit을 여러개를 두어서
instruction 여러 개를 동시에 시작할 수 있다
이게 우리가 나중에 더 자세히 보게 될
superscalar의 개념이다

마지막으로 CPU의 성능을 향상시키기 위해서
코드 수행 순서를 바꿔주는 방법이 있다
이게 out-of-order execution이다
앞에서 우리는 폰 노이만 구조를 사용하고
이는 코드를 차례대로 처리하는 in-order pipeline 구조라고 했다
하지만 반드시 이렇게 해야할까?
이렇게 순차적으로 코드를 실행하면
다음 instruction을 수행해야하는데
이 instruction을 수행하기위한 하드웨어적 준비가 아직 안되어있는 경우가 있다
따라서, source operands가 준비가 안되어있으면
일단 준비를 시켜둔 다음
준비가 된 것부터 실행을 시키겠다는 뜻이다
코드 상 sequencial한 order를 따라가는게 아닌
흔히 data flow라고 하는 data dependency에 따라서
실행 순서를 따르겠다는 뜻이다

따라서 우리는 병렬로 실행할 수 있는
instruction이 충분히 있어야 하는데
이걸 instruction-level-parallelism(ILP)라고 부른다
instruction 수준에서의 병렬화를 말하는 것이다

위와 같은 코드가 있다고 가정하자
코드를 작성하면 왼쪽처럼 순차적으로 실행하는
assembly instruction이 나오게 된다
그런데 이런 순차적인 코드말고
서로간의 data dependency를 바탕으로
코드를 오른쪽과 같이 재조립하려고한다
오른쪽처럼 재조립을 할 때
해결할 수 없는 true dependency를 기준으로 나눈다
따라서 오른쪽 재조립한 코드를 보면
같은 line에 여러 개의 instruction있기도한데
이렇게 같은 줄에 있는 Instruction들은
서로간의 true dependency가 없다
그렇기 때문에 이렇게 같은 Line에 있는 instruction들은
병렬로 실행이 된다고 하는데
이게 바로 ILP이다
하지만 한 가지 생각해야 할 점은
위는 싱글 스레드 상황에서 할 수 있는 것이다
우리가 지금까지 말한 ILP와 같은 것들은
싱글 스레드에 안에서 하나의 함수를 표현할 때 사용하는 것들이다
이보다 더 높은 차원의 병렬성은 스레드 레벨에서 수행하게 되고
그렇게 하는 것을 멀티 스레드라고 한다
이 코드 자체를 여러 개의 스레드에서 수행하면
더 큰 덩어리에서 병렬을 수행할 수 있는 것이다

아까 앞에서 잠깐 나왔던
superscalar의 개념에 대해 살펴보자
superscalar는 파이프라인 자체가 넓은 것이다
여러 instruction을 동시에 수행할 수 있게 하는 것을 말하며
이게 superscalar라고 하는 이름이 헷갈려서..
잘못지었다고하는..의견이 많다고 한다 ㅋㅋ
아무튼 전통적으로 최적의 CPI는 1이며
물리적으로 CPI는 1보다 더 작아질 수가 없었지만
superscalar를 이용해서 여러 개의 instruction을 동시에 수행하면
실제로 CPI가 1보다 더 낮아질 수가 있는 것이다
따라서 IPC라는 개념도 나오게 되었는데
Instruction Per Cycle이라고
한 cycle당 수행되는 instruction을 뜻하고
CPI는 낮을수록, IPC는 높을수록 좋아지는 것이다
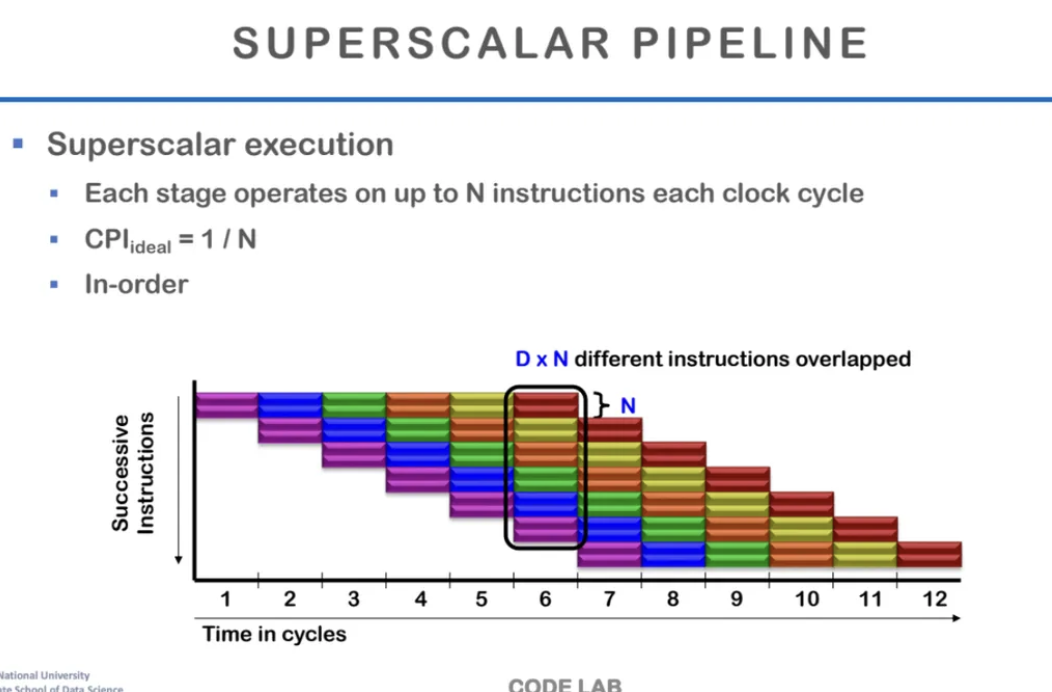
superscalar pipeline을 살펴보자
한 stage마다 2개의 instruction을 실행하는 예시이다
실제로 하나의 stage에서 최대 n개의 instruction을 수행하는 것이 superscalar이고
이상적인 경우에 CPI는 n분이 1이 된다
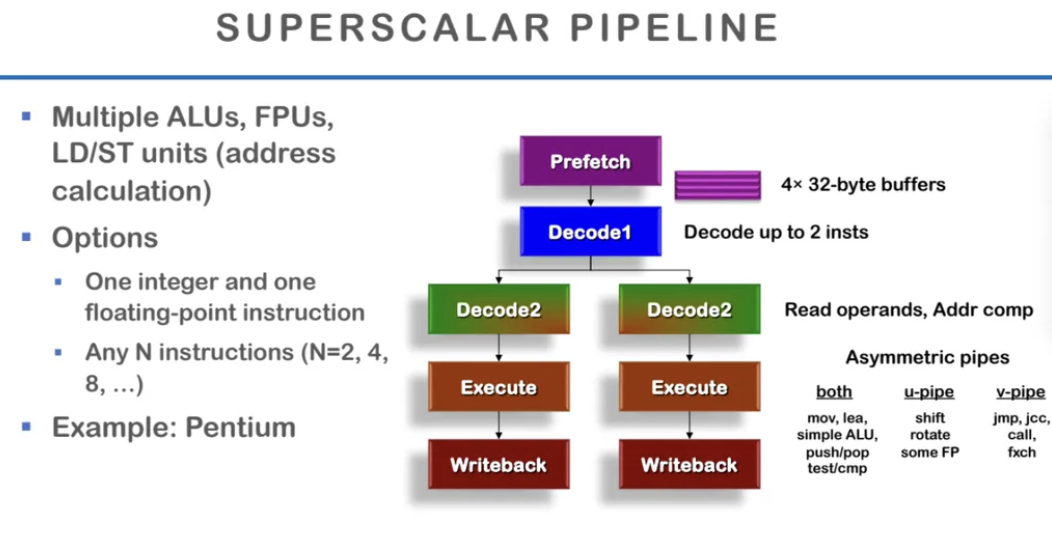
ALU, FPU와 같이 연산이 필요한 것이 여러 개 있을 때
한 번 instruction을 가져와서 2개까지 decode를 한다고 한다
instruction fetch와 decode를 할 때 최대 2개까지 가져와서
각각을 다음 stage에 넣어서 2개의 instruction이
같은 사이클 내에서 동시에 진행되게 만든다
따라서 shift, someFP, rotate, jmp, call 이런건
좀 비용이 들어가는 하드웨어들은 각각 다른 pipeline에 넣는다고한다
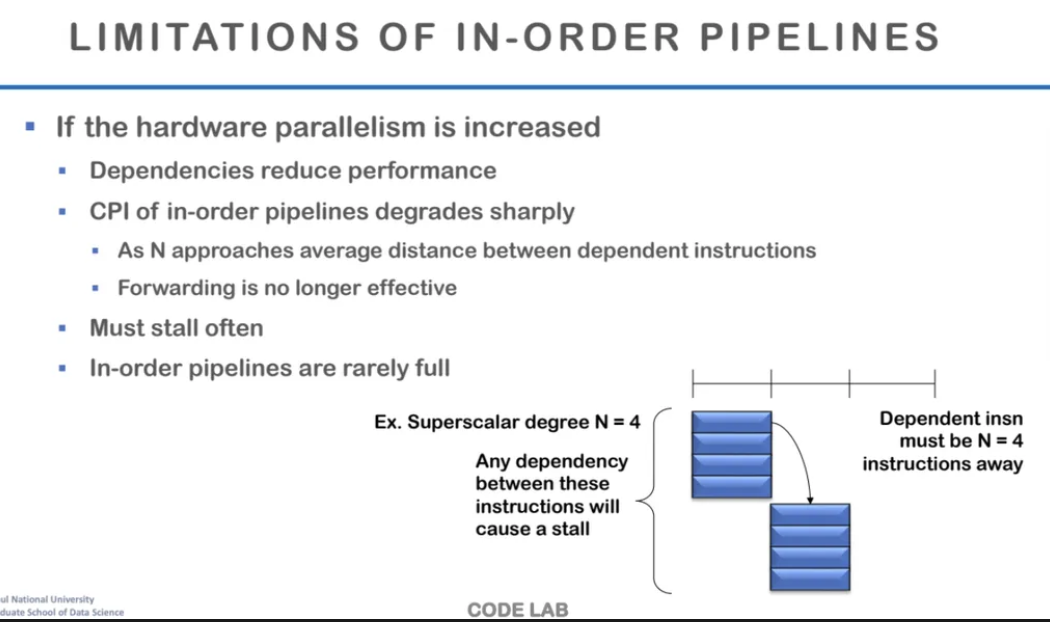
in-order pipeline에서의 문제점을 알아보자
만약 하드웨어 병렬성이 점점 늘어나게 된다고 하면
그만큼 병렬 실행이 가능한 instruction들을 찾아야한다
그런데 이를 in-order pipeline으로 수행한다고 가정해보자
보통 코드상에서 N=4라고 하는 것은
4개씩 병렬로 묶어서 instruction을 실행하는 것을 뜻한다
그럼 첫 번째에서는 4개를 동시에 수행하고
또 다음 4개를 찾아 또 동시에 수행하게 된다
그런데 여기서 문제가 되는 점은
하드웨어는 병렬로 처리가 가능하게 만들어졌는데
in-order로 수행하게 되면
data dependency 때문에 의존성 문제가 계속 발생하고
이로인해 순서를 지켜야해서 stall이 더 많이 생기게된다
따라서 in-order로 수행하면
병렬로 처리해도 오히려 더 수행시간이 길어지게 되는 것이다

위는 병렬로 처리하는데 in-order로 수행하는 예시이다
cycle 4를 확인해보면
add의 결과인 f2를 읽어오지못해서
mulf에서도 stall이 발생하고
따라서 subf에서도 stall이 발생한다
그렇다면 위의 예시에서 이런 의문점이 생기게된다
subf는 지금 addf나 mulf와는 아무런 관계가없다
그럼 addf다음에 바로 mulf를 수행해서
의존성 때문에 stall시키지 말고
mulf를 잠깐 멈춰놓고 subf를 먼저 수행시키면 안되나?
그럼 그 사이에 addf가 수행이 될 것이고
그 이후에 mulf를 수행시키면 stall 시간을 줄일 수 있잖아
이게 가능하잖아?
왜 지금까지 그렇게 안했지?
하면서 나타난 것이 바로 out-of-order execution이라고 한다
오늘 수업 정리 내용은 여기까지..
다음 시간에는 out-or-order execution에 대해서 더 자세히 배워본다고한다