본 게시글은
서울대학교 데이터사이언스대학원 성효진 교수님의
데이터사이언스 응용을 위한 컴퓨팅 시스템 강의를
학습을 목적으로 재구성하였습니다
이번 시간에는 저번 시간에 이어
out of order execution 부분을
마무리 짓고 다음 파트인
운영체제(os) 부분으로 넘어가보려고한다

하드웨어가 ooo exectution시에 코드의 순서를 정하는
dynamic scheduling에 대해서 알아보자
이건 전적으로 하드웨어가 담당하는 부분이다
컴파일 타임이 아닌 실행 중에
코드 실행 순서를 결정하기 때문에
dynamic이라는 이름이 붙었다
우선 branch prediction과 speculation을 통해
실행될 코드들을 예측하고
이를 instruction window라고 하는 곳에 저장해둔다
그런 다음 false dependency가 있는 부분을 모두 없애준다
이걸 어떻게 없애주냐?
register renaming이라고 하는 부분인데
register의 이름을 바꾸는 방식으로 다 없앤다
실제로 우리가 아는 32, 64보다
하드웨어는 더 많은 레지스터를 갖고 있고
이를 physical registers라고 부른다
실제로 Physical registers가 더 많기 때문에
적당한 비어있는 레지스터에
이름을 바꿔서 넣어주게되면
false dependency는 사라지게 되는 것이다
그렇게 false dependency가 사라진 instruction들에서
dependency가 없고 바로바로 실행이 될 수 있는
instruction들부터 뽑아서 실행하게 된다
따라서 이를 코드 상의 순서가 아니라
dependency에 따라서 순서가 실행되는 방식이라
dataflow execution이라고 부른다
어떤 instruction이든 연산을 할 준비가 되었다면
그 때 연산을 바로바로 수행한다는 의미이다
현대의 ooo execution은 크게 봤을 때는
폰 노이만 구조를 따르고 있지만
하나하나 코드 수행 순서에서 봤을 때는
dataflow execution 구조를 따르고 있다

혹시 dependency가 걸려있어
지금 당장 실행이 안되는 instruction이 있다면
buffer를 두어 이러한 instruction들이 기다릴 수 있게 한다
이를 reservation station이라고 부른다
reservation station에 들어가있는 instruction들이
해당 명령어가 실행가능한지를 알기 위해선
이걸 알려주는 무언가가 있어야한다
만약 어떤 필요한 값이 계산이 된다면
wiring이 되어있어서
그 값을 기다리고있는 모든 instruction들에게
쫘악 보내주게 되고
이를 통해 각 instruction들이
수행할 준비가 되었는지 안되었는지를 체크한다
이런 과정을 data flow라고 부른다
이러한 dataflow 구조의 가장 큰 장점은
당연히 stall되는 cycle 동안의 시간에
independent한 instruction들을 수행시킬 수 있다는 것이다
이렇게 stall 시간을 효과적으로 이용하는 것을
latency tolerance를 효율적으로 사용한다고 말한다
이런 latency tolerance를 가장 잘 사용하는 것이
바로 요즘 인공지능으로 아주 핫해진
GPU architecture이다
memory latency tolerance가 굉장히 좋아서
GPU는 메모리에 그렇게 많은 접근을 하면서도
굉장히 빠른 속도를 유지할 수 있다
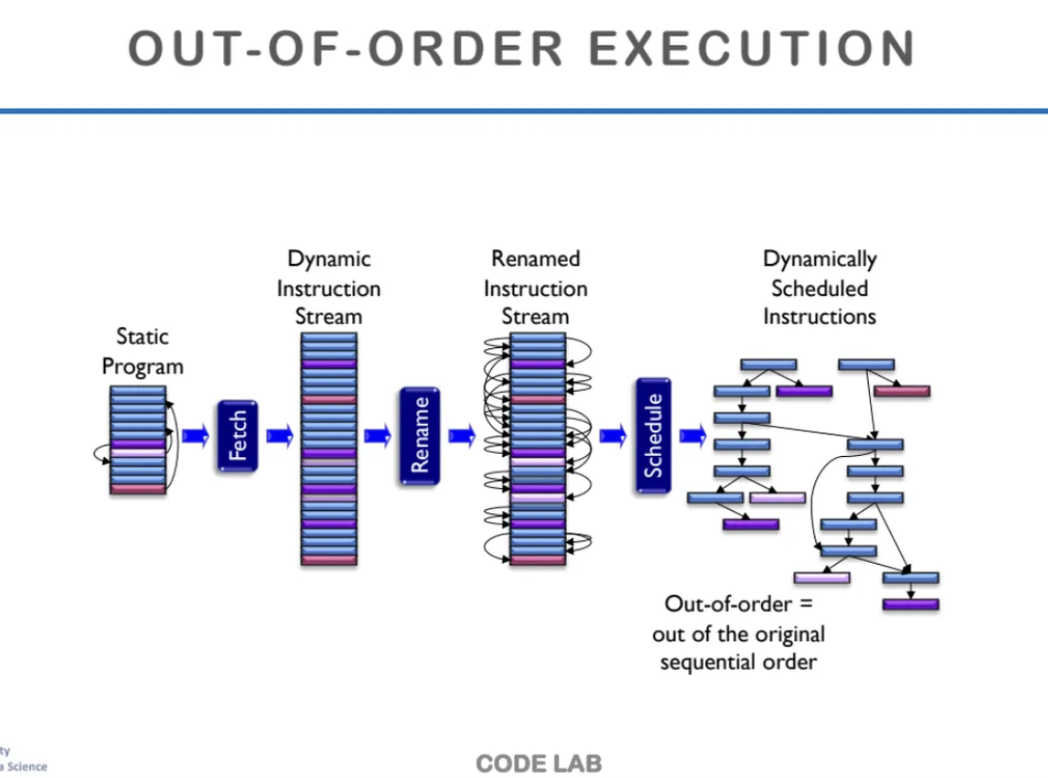
ooo execution이 수행되는 과정을 한번 살펴보자
실제 컴퓨터공학부 학부 수업에서는
이 과정을 배우면서 하드웨어들을 하나하나 뜯어보며
배우게 되는데
대학원 과정에서는 그정도까지는 안한다고 한다
우선 어떤 static program이 있으면
그 코드들을 쭈욱 펼쳐서
stream 형태로 만든다
그 이후에는 앞에서 나왔던
register rename을 통해
false dependency를 없앤다
그런 다음 하드웨어가 dependency를 보고
어떤 instruction들의 실행 순서를 결정한다
이때 dependency가 없는 instruction들끼리는
병렬로 수행할 수 있도록해준다
매우 간단하게 설명했지만
instruction들이 어디에 dependency를 갖고있는지
tracking을 하는 알고리즘이 있다고한다

앞에서 봤던 예시 instruction인데
이 예시를 통해 in order와 out of order을 비교해보자
in-order의 경우 계속해서 stall이 되고
위 예시에서 IMUL이랑 ADD간에 또
R3에서 depdency가 발생하기 때문에
또 stall이 된다
그러나 ooo의 경우
ADD를 하려고 보니 아직 R3에 write가 되지 않은 상태라면
일단은 기다리는데 그 기다리는 동안
다음 instruction이 시작된다

이러한 ooo가 가능하게 하려면
여러가지 추가되는 작업들이 필요하다
우선 기다리고 있는 instruction들에게
알려주는 link가 필요하다
현재 기다리고 있는 instruction들은 위에서 봤던
Reservation station이라고 하는
buffer에서 기다리고 있는데
본인이 필요한 소스가 계산이 되었는지 안되었는지를
계속해서 tracking을 하고 있어야한다
어떤 소스가 연산을 하면
그 tag정보를 instruction들에게 전달한다
그럼 instruction들은 나의 tag와
방금 들어온 tag가 같은지를 확인을 하고
만약 tag가 같다면 내가 기다리고 있는 정보가 온 것이라
수행가능한 상태가 된다고 한다
만약 동시에 여러 instruction들이 기다리고 있다가
동시에 수행가능한 상태가 되는 경우도 있으므로
그런 것들을 순서대로 하나씩 처리하는 로직도 존재한다
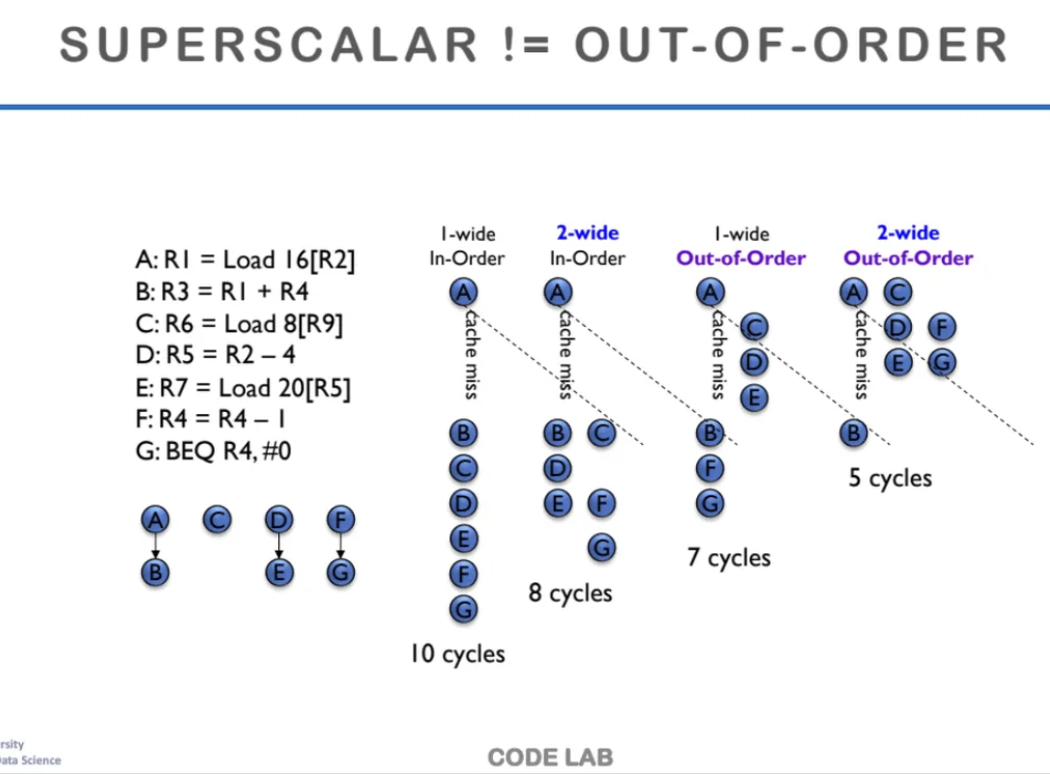
학생들이 앞에서 배웠던
superscalar와 ooo를 많이 헷갈려해서
명확하게 정리를 해보려한다
우선 superscalar는 in-order일수도있고
out-of-order일 수도 있다
superscalar는 그냥 한 cycle에 여러 개의 instruction들을
한 stage에 병렬로 실행하는 것을 말한다
그러기 위해서는 독립적으로 수행이 가능한 instruction들을
2개, 4개씩 묶어서 수행한다
one wide는 1개씩 수행하는ㄴ것
two wide는 2개씩 수행하는 것이다
위 ppt를 보면 in order superscalar와
out of order superscalar를 비교해놨는데
in order의 경우 코드의 원래 순서를 지키기 때문에
cache miss가 발생하면 그 사이를 메꾸지 못하고
기다리는 것을 확인할 수 있다
1 wide에서는 코드를 1개씩 실행하고
2 wide에서는 2개씩 실행한다
out of order에서는 만약 cache miss가 발생하면
또 다른 Instruction들을 그 사이에 dynamic하게 실행한다
superscalar의 성능이 좋고 ooo일수록
CPU의 성능은 올라가게 되고
현대의 CPU는 대부분 이러한 방식으로 작동한다

현대의 superscalar + ooo의 구조이다
위 구조에서 dispatch 윗 부분까지를
프로세서의 frontend라고 부른다
그다음 dispatch 이후의 구조를
프로세서의 backend라고 부른다
frontend에서는 in order instruction을
우선 불러온다
dispatch는 실행을 하라고
fuctnion을 보내는 작업이고
executin은 실제로 그걸 실행하는 작업이다
out of order이면서 동시에 superscalar구조이고
내부에서 코드의 dependency를 기준으로 순서를 정해
실행시킨 다음 마지막에는 다시 inorder 순서로
돌아가게된다
ooo로 계산을 하다가 reorder buffer에
우선 임시로 저장을 하고
Retire를 통해 instruction을 종료시키는데
실제 instruction 순서에 맞춰서 레지스터와 메모리에 쓴다
그래서 다시 inorder 순서로 돌아가는 것이다
지금 위 구조를 봐서 알겠지만
추가적인 buffer도 매우 많아지고
버퍼와 유닛들 간에 엄청나게 많은
와이어들도 추가될 수 밖에 없다

앞에서 설명했던 부분인데 다시 한 번 언급하고 넘어가자
register naming을 하면 false dependency를 없앨 수 있다
buffer를 이용하면 independent operation을
수행할 수 있다는 그런 내용이다

지금까지 우리가 본 구조는
완벽한 data flow의 구조는 아니기 때문에
restricted data flow라고 부른다
전체적으로는 폰 노이만
일부는 data flow 구조를 따르기 때문이다
그럼 ooo가 왜 성능이 더 좋을까?
모든 operation이 single cycle로 돌아간다고해도
여전히 ooo가 더 성능이 좋을까?
한 번 생각을 해보자
in order로 했는데 CPI가 1이 나온다고 가정하자
그래도 ooo가 더 성능이 좋을까?
in order의 경우는 dependency가 발생하면
앞에서 배웠던 stall, bypass, speculation으로 해결한다
ooo는 사실 latency tolerance에 굉장히 좋은 구조인데
이런 tolerance 자체가 필요없는 프로그램이라면
사실 ooo 구조는 더 불리하게 작용할 수 있다
만약 우리의 프로그램이 또 너무 큰 경우를 생각해보자
stall하는 동안에 실행할 수 있는 instruction을 찾아야하는데
instruction window에서 이를 찾아야한다
그런데 계속해서 stall해서 계속해서 instruction을
찾아와야하는 상황이 생긴다면
그게 가능할까?
사실 한계가 있을 수 밖에 없다
따라서 instruction window의 사이즈 크기가 클수록
instruction을 가져올 수 있는 확률이 커진다
그래서 만약 instruction을 가져와야할 상황이
너무 많이 생기면 이걸 다 충족시키지 못한다
그래서 이럴 때는 멀티스레드로 수행하게된다

pipeline depth가 계속 깊어지기 때문에
ooo 구조도 결국 한계가 있을 수 밖에 없다
그리고 한 가지 더 생각해야 할 점은
ooo의 로직이 정말 복잡하다
그래서 이러한 ooo를 정확하게 만드는 것도
효율적으로 만드는 것도 정말 어렵다
실제로 에너지효율 때문에 지금의 하드웨어는
더 이상 복잡하게 만들 수도 없다고 한다
우리가 frequency를 높이면
에너지 소모는 더 높아지게 되고
물리적으로 어떤 열의 발산이라던지
power budget을 감당할 수가 없게된다
따라서 지금의 코어는 ILP를 어느 수준까지
끌어올린 다음 더이상 고도화를 진행하지 않는다고 한다
그래서 다른 방향으로 병렬화를 하려고 하는데
GPU는 data level parallelism(DLP)을 수행한다
같은 연산을 하는데 각각 다른 데이터에다가 하는 것이다
thread-level-parallelism(TLP)이라고
우리의 코어 개수에 따라서 병렬화를 하는 것이고
훨씬 더 general한 형태의 병렬ㄹ
DLP와는 다르게 각각의 스레드들이
같은 일을 하지 않아도 된다

지금까지 배운 cpu pipelining 내용의 요약이다
한 번 잘 읽어보면 좋을 것 같다

이제 다음 내용인
process와 운영체제 내용으로..

지금까지 배운 내용은
프로세서 아키텍처의 내용이었다면
지금부터 배울건
우리와 하드웨어를 연결해주는 고리인
운영체제에 대한 내용이다
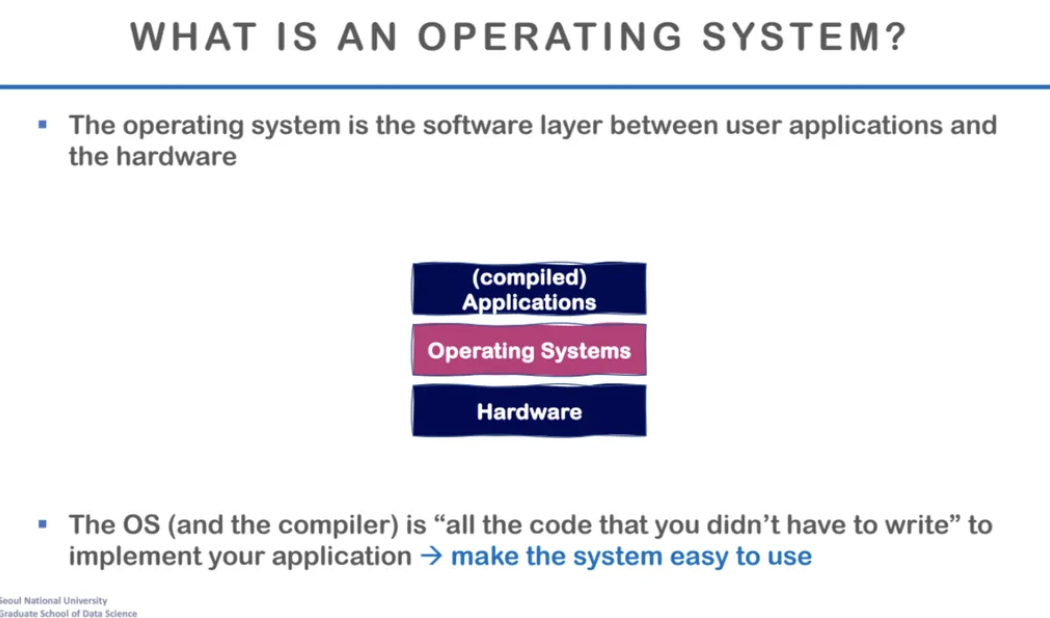
운영체제의 가장 큰 목적은
지금까지 배운 복잡한 하드웨어의 파이프라인을
단 하나도 몰라도 되도록 해주는 것이라고 한다
복잡한 내용들을 다 추상화해서
하드웨어를 쉽게 쓸 수 있도록 제공하는
어떤 플랫폼과도 같은 것이 바로
operating system(os)
한국어로는 운영체제이다

os는 우리가 다양한 자원들을
편하게 사용할 수 있도록 도와준다
우리가 이전에 배웠던 CPU와 스레드
그리고 memory에 접근할 수 있도록 하는
추상화된 virtual address
그리고 디스크, 네트워크 등등
다 우리가 직접 다루는 것이 아니고
os가 제공하는 체제 안에서 우리는 접근할 수 있다
따라서 이걸 얼마나 효율적으로
어떻게 추상화했는지가 매우 중요해진다
즉, os의 목적은 성능으로인한 impact를 최소화하면서
관리와 관련된 기능들을 모두 제공하는 것이다

하드웨어들에 대한 access를 제공해주는 것이
os의 목표이다
우리가 프로그램 하나를 실행하면
그 프로그램 한개만 cpu를 독차지하는 것처럼 보인다
하지만 실제로는 그렇지가 않으며
cpu와 같이 공유하는 자원을 관리하는 것이 os이다
이러한 os의 목적 중에서는
protection의 목적도 있는데
프로그램들이 서로 서로 침범하지 않고
각자의 데이터에 대해서만 연산하도록
보호해주는 역할도 한다

os를 사용하면 뭐가 좋은가..
뭐 프로그램을 작성하기 쉬워지고 등등
이것저것 많은데 그 중 한가지만 보자면
장치에 독립적으로 코드를 작성할 수가 있다는 점이다
AMD인지 intel인지 코드를 따로 작성할 필요가 없다

os는 위의 4가지 기능을 제공한다고한다
오늘 우리가 볼 내용은
virtualization에 관련된 내용이다

앞에서도 말했지만 우리는 어떤 한개의 프로그램이
모든 하드웨어 리소스를 다 갖고있는 것과 같은 환상을 본다
이는 사실은 공유되는 자원을
각각의 프로그램들이 분배해서 사용하고 있는 것이고
이걸 하는게 os의 핵심 기능 중 하나이고
이를 virtualization이라고 한다

여러 개의 프로세스가 동시에 돌면서
interact를 하는데
이런 event를 어떻게 관리하는지가
concurrency에 관련된 내용이다

또한, 우리가 컴퓨터 전원을 꺼도
하드디스크에 있는 내용들은 다 남아있다
이러한 것도 다 os가 관리를 해주고
이를 persistence라고 부른다

앞에서도 말했던 내용인데
os는 서로 서로를 보호하는 목적도 있다
파일 authentication같이
함부로 어떤 하드웨어에 접근할 수 없게
도와주는 역할도 한다

프로세스에 대해 배워보자
사실 앞에서 다 배운 내용인데
좀 더 구체적으로 살펴보기 + 복습겸
다시 한 번 살펴보자

프로세스는 쉽게 말해서 running program이다
job 혹은 task라고도 부르는데
코드가 실행하는 동안에 실행하는 데이터를 포함하는 개념이다
그래서 process는 코드 자체와는 다른 개념이다
뭔가를 실행할 때
실행하는 코드와 코드와 관련된 정보를
모두 포함하는 추상화된 개념이며
os가 스케줄링을 할 때도 프로세스를 단위로 수행한다

그렇다면 프로세스는 어떤 정보를 포함하는가?
첫 번째는 주소 공간이다
프로그램과 관련된 정보를 저장해두는 어떤 공간인데
PC가 increment하면서 코드를 실행하는데
이때 PC에 들어가는 것이 바로 address이다
또한 프로그램을 실행하는 순간
굉장히 많은 데이터를 생성하는데
이걸 어딘가에 저장을 해두고 사용해야한다
이 때의 data 접근도 주소를 통해서 가능하다
우리가 코드에서 동적으로 할당하면 heap에
지역변수는 stack에 저장된다
두 번째는 CPU states이다
PC, stack pointer, 레지스터와 같은
정보들을 다 포함한다
마지막으로는 파일이나
network connection과 같은 하드웨어 정보들이다
프로세스마다 파일을 열고 네트워크 커넥션을 하는데
이런 것도 다 따로 관리하게된다

왼쪽의 c언어 코드가 그냥 단순 프로그램이라면
이를 compile해서 assembly코드로 만들고
해당 data들은 data section에 들어가게된다
이렇게 compile해서 나온 것이
프로세스가 된다

그렇다면 우리가 코딩을 할 때도 알겠지만
한개의 파일에 모든 코드를 다 작성하지는 않는다
하지만 compile할 때는 한 파일만 컴파일을 한다
이를 컴파일과정에서 한 파일에서 사용되는 다른 파일의 코드들을
linker가 연결해준다

Loader는 실행 파일을 실제로 실행되게
만들어주는 역할을 한다
우리가 c언어를 컴파일하면 생성되는 실행파일을
프로세스로 시작하게 해주는 역할을 한다
디스크에 있는 실행파일 코드와 초기 데이터들을
메인메모리로 가져오고
각각 code, data와 같은 section에 적절하게 배치한다
그렇게 공유되는 라이브러리들도 다 연결을 한 다음
os에 프로세스를 만들어달라고 요청을 한다
앞에서 compiler, assembler, linker그리고 loader를 봤는데
우리가 코드를 작성해서 아키텍처에 들어가기 전까지
운영체제가 해주는 과정을 살펴보았다
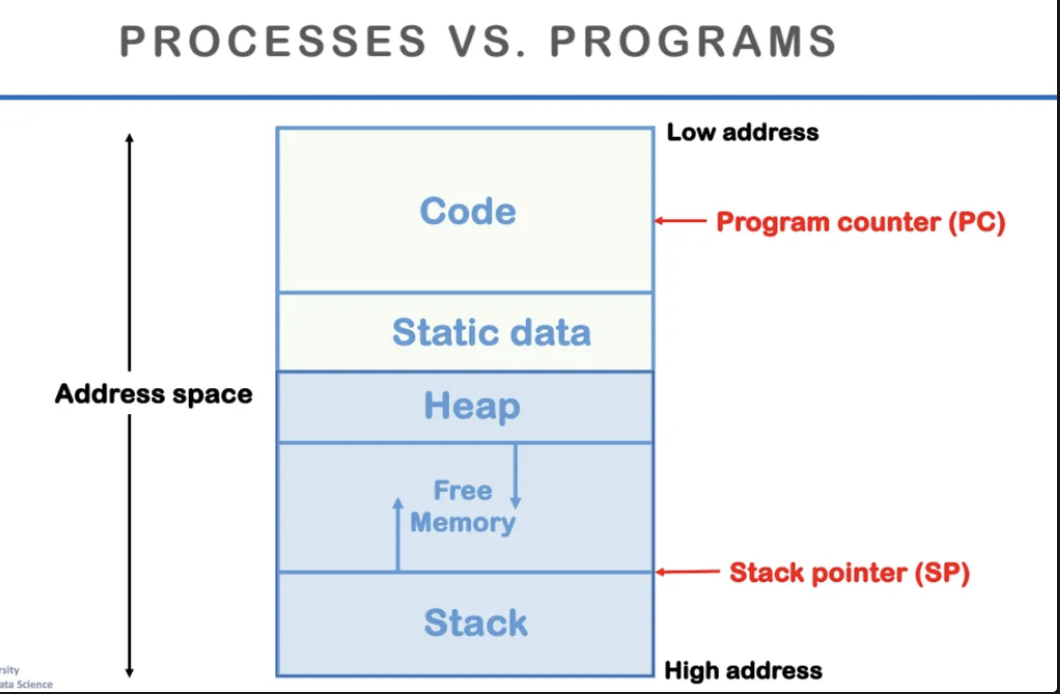
첫 수업시간에도 봤던 그림이고
사실 컴퓨터 관련 공부를 하다보면
너무 많이 보게 되는 memory layout 그림인데
한 번 더 자세하게 살펴보자
code는 코드가 저장되는 곳이고
heap은 동적 할당되는 변수들이 저장되는 곳
stack은 지역변수나 함수들이 저장되는 곳이다
함수들은 호출될 때마다 stack frame에
함수와 관련된 정보들을 쌓게 되고
함수의 argument들, 실행했을 때 필요한 register 정보 등을
stack에 저장하게 된다

이것도 앞에서 배운 내용인데
프로세스가 여러 개 있어도
마치 CPU한개를 다 차지하고 있는 것처럼 보이는데
CPU는 각 프로세스들을 동시에 실행하는 것이 아니고
번갈아가면서 실행한다
이 것을 가능하게 해주는게 바로
time sharing이다
또한, 컴퓨터의 유한한 공간을 잘 나눠서
각각의 프로세스들이 사용할 수 있게 해주는 것도
space sharing의 개념이다

process를 관리하는 단계이다
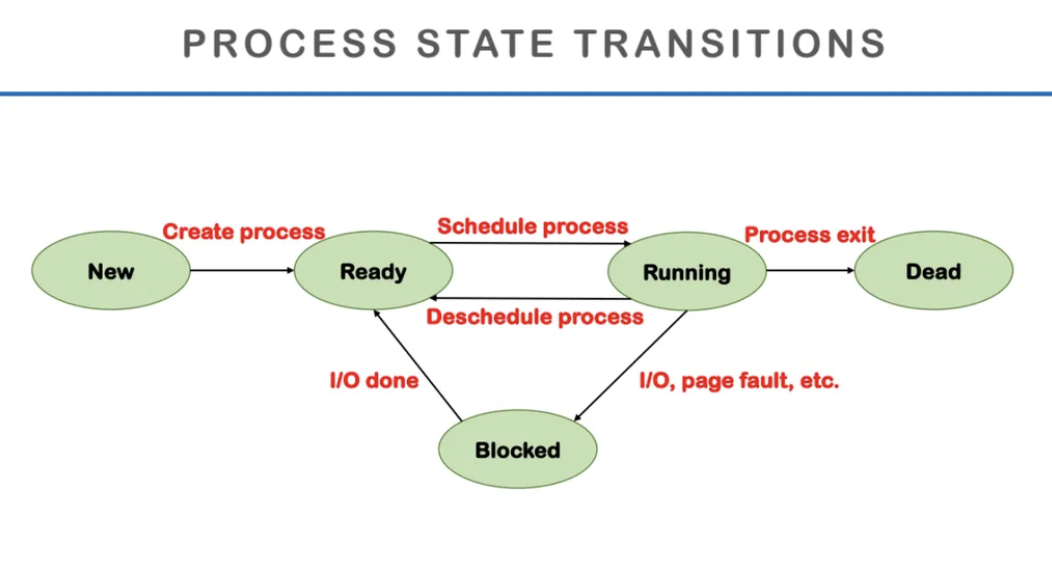
우선 새로운 프로세스가 생성되면
실행을 준비시킨다
Ready가 완료되면 프로세스를 실행시키는데
block이 되면 disk에서 읽어오는데 시간이 걸리니까
그게 끝날때가지 기다렸다가 다시 끝나면 실행되는 것을 반복한다
이걸 프로세스가 끝날 때까지 기다리다가
프로세스가 끝나면 dead가 되고 끝난다

그렇다면 os는 상태를 어떻게 관리할까
PCB라는 프로세스 상태를 관리하는 메타데이터가 있다
어떤 process가 running인지 ready인지를
PCB에서 갖고있다
만약에 process가 running 하는 중이면
저 PC, SP, register가 실제로 하드웨어에 올라가 있는 상태가 된다
이게 실행 중이 아닐 때는 해당 정보는 그냥
PCB에만 존재하게 된다
그러다가 스케줄이 돼서 CPU에서 실행을 하게 되면
이 정보들이 한 번에 하드웨어를 옮겨가고
그러다가 또 그렇게 수행을 하다가 수행한 내용을 저장하고
다시 PCB에 지금까지의 내용들을 저장하고를 반복한다

프로세스가 수행되다가 다른 프로세스 수행을 위해 멈추게되면
프로세스가 멈췄을 때 모든 정보들을 PCB에 저장한 다음
다시 해당 프로세스를 수행할 차례가 되면
PCB에 있던걸 다시 하드웨어에 써서 작동을 시킨다
이러한 과정을 context switching이라고 한다
당연히 이러한 과정에는 약간의 overhead가 있고
이 overhead가 일종의 스케줄링 오버헤드이다
우리는 어떤 프로세스가 하드웨어를
독점하게 만들 수는 없다
그럼 다른 프로세스는 끝까지 기다려야한다
따라서 이러한 상황을 막기 위해서
context switching은 필수적이고
이걸 os가 하는 것이다
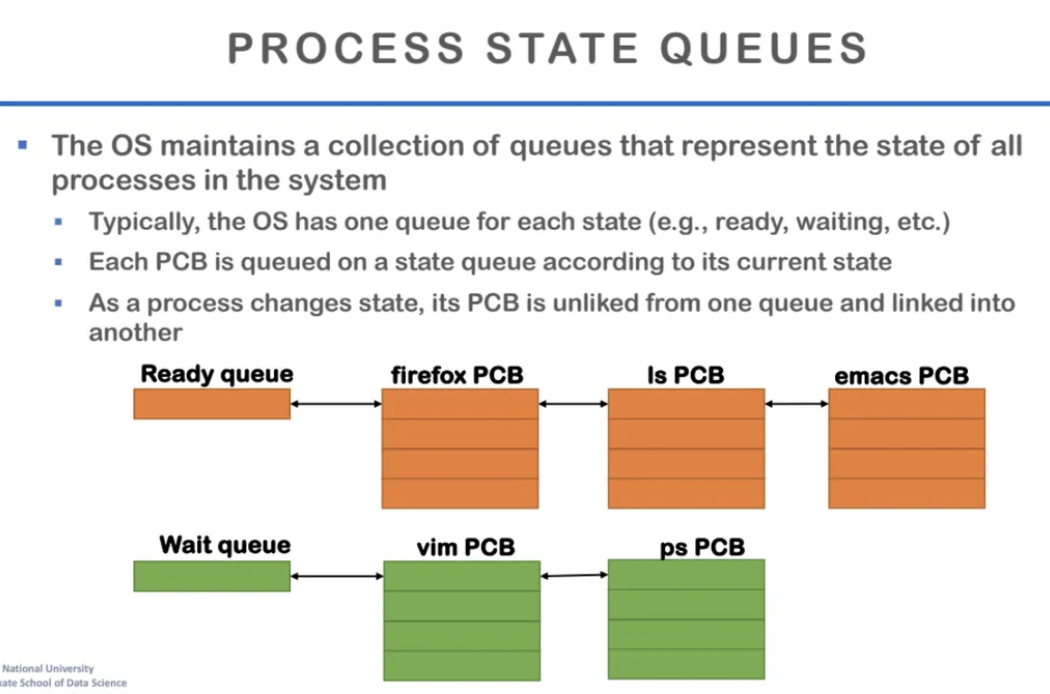
os는 각 프로세스들의 상태를 표현하는
queue를 갖고있다고 한다
os는 모든 프로세스를 상태별로 나눠서 관리하고
이를 위해 여러 개의 queue를 사용하여
각 프로세스의 상태에 따라 해당 큐에 넣고 뺀다

프로세스가 생성이 되면 PCB도 생성이 된다
그러고 그게 ready queue에 들어가게 된다
그러고 프로세스가 실행이 시작되면
PCB는 다른 queue로 또 이동하게 된다
그러다가 프로세스가 멈추게 되면
잠시동안은 PCB를 갖고 있다가
결국에는 os는 PCB를 deallocate 시킨다
오늘 수업의 내용은 여기까지라
여기까지 .. 정리 끝 -!