본 게시글은
서울대학교 데이터사이언스대학원 성효진 교수님의
데이터사이언스 응용을 위한 컴퓨팅 시스템 강의를
학습을 목적으로 재구성하였습니다
우리가 이미 앞에서
Program Representation을 배우면서
다 들어봤을 내용이라고 하셨다
이전에는 프로그램의 표현을 배우기 위한 배경지식으로
CPU 아키텍처에 대해서 배웠다면
이번 시간에는 정말 본격적인 CPU 아키텍처에 관한 내용이라고
생각하면 좋을 것 같다
교수님 말씀도 너무 빠르고 진도도 너무 빨라서
따라가는게 약간 벅차다 ㅠ
암튼 이번 수업 내용 정리 시작 ㅠ

컴퓨터란 무엇인가?
단순히 우리가 사용하고있는 데스크탑이나 노트북 말고
정말로 컴퓨터란 무엇인가?
흔히들 컴퓨터를 계산하는 기계라고 하지만
그렇다면 계산기는 컴퓨터인가?
보통 계산기를 컴퓨터라고 하지는 않는다

이 ENIAC이 바로 최초의 우리가 생각하는 컴퓨터라고한다
이 때에 컴퓨터라는 개념이 정의가 되었고
이 당시 프로그래밍의 개념은 실제로 switch와 cable을 변경하는 것이었다

위 ppt는 튜링 머신이라는 것이다
이 때는 프로그램이 물리적으로 연결을 해서
프로그램 자체가 데이터와 같이
어딘가에 저장이 되는 형태였다
실행하는 프로그램도 저장장치에 있고
데이터도 저장장치에 있는 구조였다

그러다가 세상에 등장을 한 것이 바로
현대 대부분의 컴퓨터의 구조가 되고있는
폰 노이만 구조이다
우리가 사용하고 있는 대부분의 아키텍처는
이 구조를 따르고 있다
위 ppt가 폰 노이만 구조를 추상화한 것이다
폰 노이만 구조가 나온 이후로
모든 데이터들은 Input device를 통해서
프로그램과 데이터 모두 메모리에 저장이 되었다
그리고 해당 프로그램이나 데이터에 접근하기 위해서는
메모리 주소에 access하게 되었다
우리가 이전 수업시간에 배웠던
CPU와 메인메모리가 계속해서
데이터를 주고받는 형태가 바로 폰 노이만 아키텍처이다
이걸 가능하게 하려면 몇 가지 장치가 필요한데
첫 번째는 몇 번째 instruction을 실행할 것인지를
제어하는 제어기 역할을 하는 control unit
그리고 연산을 수행하는 ALU가 있다
데이터를 input device로 받아오고
결과를 output device로 내보내는 형태가 되었다
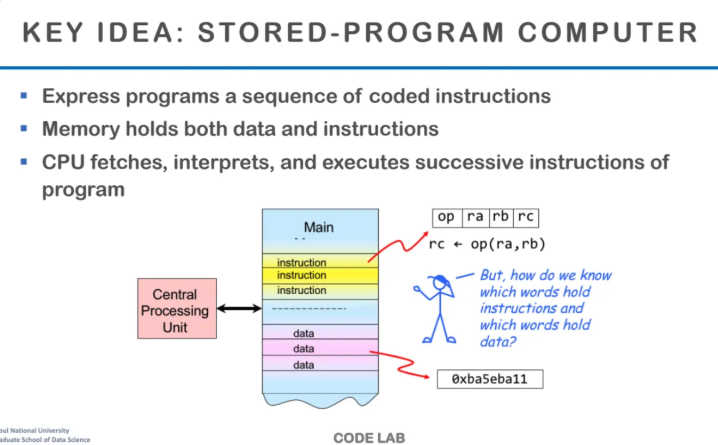
폰 노이만 형태의 가장 핵심 아이디어는
stored program computer라는 점이다
위 그림이 가장 대표적인 폰 노이만 아키텍처인데
아키텍처 내부를 열어보면
위와 같은 방식으로 구성이 되어있다고한다
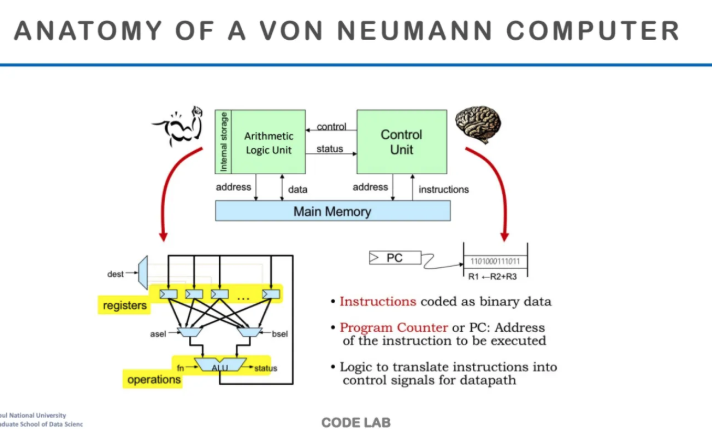
폰 노이만 구조의 내부를 자세하게 살펴보자
main memory가 있고
control unit이 instruction을 읽어온다
그리고 control unit이 ALU에 어떤 instruction이
연산을 수행해야하는지 신호를 보낸다
연산을 할거면 ALU에다가 ADD, SUB, XOR 등
특정 연산을 하라고 신호를 주는 것이다
연산이 끝나면 ALU는 상태를 다시 돌려준다
왼쪽 아래가 ALU를 간단히 살펴본 그림인데
레지스터는 ALU 옆에서 빠른 연산을 수행하도록 존재한다
또한 앞에서 수도 없이 나왔지만
PC(Program Counter)는 어떤 Instruction을
실행할지를 저장하는 곳이다

ALU에 대해서 알아보자
이미 이것도 앞에서 수도없이 배웠지만
ALU는 더하기, 빼기, 로직과 같은
기본적인 연산을 수행하는 장치이다
기본연산보다 더 복잡한 연산은
ALU 여러개를 조합해서 지원한다
ALU는 연산을 할 수 있는 가장 기본 단위이고
주로 symbol로 연산을 많이 표현한다

CPU 내부에선 데이터 저장을 어디에 어떻게 할까?
매번 메모리에 접근해서 결과를 가져오면
비용이 너무 많이 들기 때문에
CPU 내부의 레지스터파일에 데이터들을 저장한다
위 예시에서 (A+B)*C/D와 같은 연산이 있다면
A+B를 연산해서 레지스터에 저장하고
C를 보고 연산해서 또 레지스터에 저장하는걸 반복하는 형식이다

Instruction은 실제로 컴퓨터를 실행하는
가장 기본적인 단위이다
Instruction Set Architecture(ISA)는
하드웨어와 소프트웨어 사이의 인터페이스를 정의하는 개념으로
CPU가 이해하고 실행할 수 있는 명령어들의 집합이다
컴퓨터 언어는 크게 2개로 구분되는데
컴퓨터가 이해할 수 있는 0과 1로 구성된 machine language와
그 machine language를 사람이 해석할 수 있게 바꾼
assembly language가 있다
폰 노이만 구조의 큰 특징 중 하나는
기본적으로 instruction들이 순서대로 실행되는 것이다
왜냐하면 PC가 instruction을 가져올 때
increment를 하면서 가져오기 때문이다

ISA에 대해서 배워보쟝

ISA는 우리가 아는 x86-4, AMD, mac sillicon 등
각각 회사마다 다르게 정의를 한다
하드웨어가 제공하는 기능들을 정의해놓은 것이고
그게 정확하게 어떻게 구현되어 있는지는
우리가 알 필요도 없고 나와있지도 않다고 한다
그래서 new layer of abstractions이라는 표현이 붙는다고한다
위 ppt에서 두개의 CPU 예시를 들었는데
1978년에 나온 8086과
2024년에 나온 Core Ultra 9는
내부에 존재하는 트랜지스터나 레지스터의 수는 완전히 다르지만
ISA가 완전히 똑같기 때문에
software가 호환이 가능하다고 한다
하지만 이런 구조도 단점이 있는데
완전 초기에 나왔던 ISA의 design decision들이 있는데
이게 지금과 일치하지 않지만 이걸 되돌릴 수가 없다고 한다
x86이 처음 나왔을 때는 하드웨어의 수가 적었기 때문에
하나의 instruction을 잘게 쪼개서 여러 개의 연산이 나오도록 설계가 되었는데
지금은 가용 하드웨어의 수가 많아져서 그렇게 할 필요가 없지만
초기에 그렇게 설계된 것을 바꿀 수가 없다고 한다

앞에서 assembly code를 공부할 때 배웠지만 한 번 더 살펴보자
instruction은 크게 opcode와 operands로 구성되어있다
이런 instruction format에는 크게 3가지가 있는데
R-Type은 레지스터 타입으로
레지스터를 여러 개를 읽어오는 경우이다
I-Type은 인코딩 방식으로
숫자가 바로 들어가는 경우를 말한다
마지막 J-Type은 Jump나 branch처럼
연산을 하는게 아니라 PC를 통해서 수행하는 경우이다
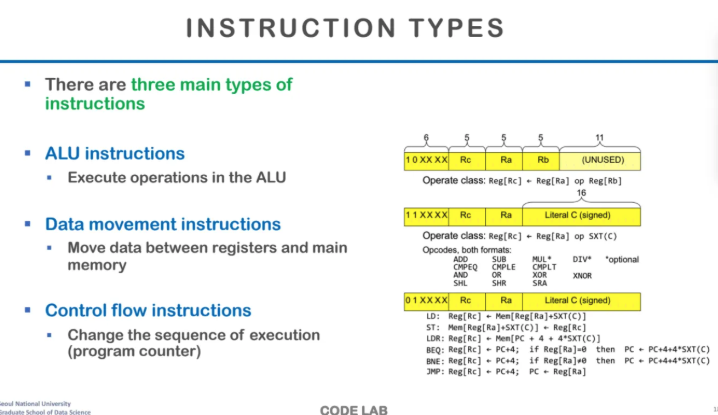
instruction을 하는 일에 따라 나눈 경우도
크게 3가지로 구분할 수 있다
ALU, Data movement, Control Flow가 있다
ALU는 앞에서 나왔듯이 연산,
data movement는 register와 memory에서
데이터를 주고받는 것들을,
control flow는 jump나 branch를 말한다
위 ppt에서 가장 앞에 나와있는 것이 opcode이고
오른쪽 아래는 어떤 Instruction type에 따라
저렇게 instruction이 정의가 될 수 있다는 예시이다

ALU instruction에 대해 살펴보자
가장 앞부분이 opcode이고
차례대로 dest와 source register들이다

많은 프로그램들에서 constant를 빈번하게 사용한다
그래서 constant만을 받는 새로운 operand를 만드나?
에 관한 논의가 많이 진행된다고 한다
이렇게 하면 당연히 opcode의 종류는 늘어나게된다
그러고 당연히 instruction의 수도 증가해서 복잡해진다
하지만 trade-off가 당연히 존재하는데
맨날 쓰는 constant들을 매번 레지스터에서 읽어와서
쓸데없는 레지스터 사용을 줄일 수 있게 된다
그래서 흔히들은 자주 쓰는 constant들(0, 1, -1)에 대해서는
바로 쓰이는 instruction을 사용한다고 한다
특히 반복문에서 0부터 어디까지, condition에서 0또는 1을 비교할 때
주로 constant들에서만 사용되는 instruction을 사용한다고한다

constant가 존재하는 ALU instruction이다
가장 앞이 opcode
그다음이 dest
그 다음이 first operand이고 위 예시에서는
first operand는 레지스터에 위치한다
그리고 마지막이 16bit의 constant이다
위 예시에서는 -3을 2의보수형태로 표현했다고한다

Load와 Store instruction이다
load와 store은 사실상
register와 main memory간의 데이터 교환이다
그래서 이걸 수행하려면
메모리 주소를 실제로 정확하게 알아야한다
그래서 위의 예시를 보면
ra와 16비트 signed constant가 들어가는데
이는 정확하게 address를 계산하기 위함이다
ra에다가 뒤의 constant를 더해서
그 address 값으로 메모리에 access하는 것이다
이런식으로 load와 store을 수행하는 이유는
보통 memory는 base에다가 offset을 지정해주는 형태로
계산하는 것이 매우 일반적이기 때문이다
아마 위 말을 듣고 바로 떠오르는 예시가 있었을 것이다
바로 array에서의 요소 접근이다
우리는 보통 array가 있으면 array[1]과 같이
index로 접근하는데
저렇게 접근하는 방식이 보통
array의 base memory + index방식으로
메모리의 주소를 계산해서 access하는 것이다
따라서 우리가 주로 하는 array나 struct에서의
요소 접근이 위와 같은 방식으로 계산된다
그런데 base는 보통 레지스터에 위치한다
왜냐면 우리가 코드를 실행하는 그 순간에는
우리가 정의한 array나 struct이 memory의 어디에 들어갈지 알 수가 없다
함수 내에서 지역변수를 만들든
malloc이나 new로 할당을 하든
메모리 할당은 모두 동적으로 이뤄지게된다
하지만 offset은 우리가 코드 실행 시점에도 알 수 있기 때문에
base의 값은 레지스터에 저장하고
offset은 constant로 저장해서 정확한 메모리 주소를 계산하는 것이다

보통 load를 수행한 뒤 연산을 하고
그 다음 다시 store을 한다

Branch instruction에 대해서 알아보자
branch는 PC에 있는 instruction을
어디에 있는걸로 바꿀 건지를 선택하는 것이다
if문이 가장 흔한 예시인데
해당 조건이 실행되면 다음에 실행해야할 instruction은 어디인지
next instruction값을 미리 계산해서 넘어가는 것이다
위 예시는 완전 기본적인 branch example이고
함수를 호출할 때도 branch instruction은 수행된다

위의 branch가 condition을 갖고있는 것이었다면
jump는 condition이 없는 branch instruction이다
이 또한 함수 사용할 때 자주 사용된다

이제 본격적으로 CPU 아키텍처에 대해 살펴보자

CPU 아키텍처를 디자인 할 때 중요한 것들을 살펴보자
보통 일반적으로는 실행시간이
CPU 성능 측정의 기준이 된다
또한, cost를 최소화하는 것이 매우 중요하다
여기서 cost라고 하는 것은
circuit을 통해서 CPU를 구성했을 때
overhead를 최소화 하는 것이 엔지니어링 적으로
CPU 설계를 최적화하는 과정이다
그리고 당연히 가격대비 성능을 최적화하는 것이 best이다
그렇다면 CPU 실행 시간을 어떻게 줄일 수 있을까?
크게 3가지 주요한 방법이 있는데
첫 번째는 instruction의 개수를 줄이는 것이다
하지만 이건 CPU 아키텍처만으로 해결할 수 있는 문제가 아니다
우리가 코딩을 어떻게 하는지도 영향을 줄 수 있고
ISA도 영향을 줄 수 있고
컴파일러의 최적화 수준에 따라서도 달라질 수 있다
두번째는 cycles per instruction(CPI)를 줄이는 것이다
clock이란 컴퓨터 연산의 단위인데
하나의 instruction에 몇 개의 clock이 필요한지가
바로 CPI이다
그리고 한개의 clock의 길이는 clock cycle이라고 부르고
이는 흔히 frequency로 나타낸다
clock cycle이 짧아질수록
1초에 더 많은 clock cycle이 들어가게 되는 것이다
따라서 세번째 방법은 clock cycle을 줄이는 것이다
결론부터 말하면 우리가 봐야할 것은
두 번째인 CPI를 줄이는 것이다
cycle time을 줄이는 것은 CPU 아키텍처의 관점에서도 가능은 하지만
트랜지스터같은 더욱 low한 레벨의 역할도 있다
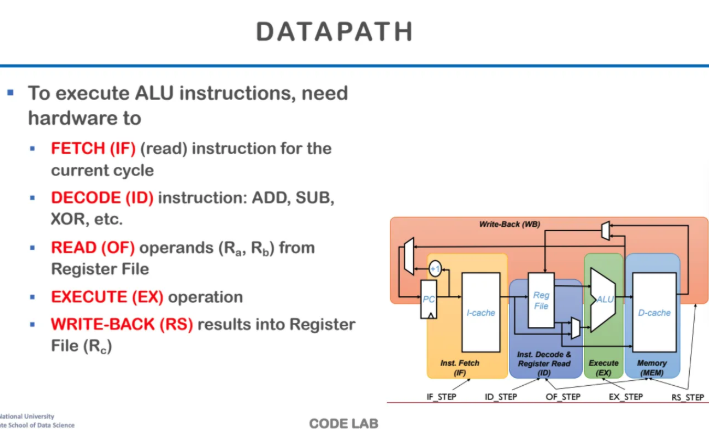
그렇다면 우리가 어떤 코드가 들어왔을 때
이를 실행하는 단계를 살펴보자
이런 것을 pipelining이라고 하는데
CPU pipelining은 크게 5가지로 나눌 수 있다
1. FETCH (instruction fecth, IF)
우리가 실행하고자 하는 Instruction을
PC로부터 가져오는 것이다
2. DECODE (instruction decode, ID)
이전 단계에서 받아온 instruction을
decoding하는 단계이다
가져온 instruction을 열어서 해석하는건데
아까 앞에서 본 폰 노이만 구조에서
control unit이 하는 역할이다
3. READ
instruction을 실행하려면 연산자들이
레지스터에 들어가있어야한다
해당 단계는 operands 레지스터를 읽어서
연산을 준비하는 단계이다
4. EXECUTE
instruction을 실행하는 단계이다
45. WRITE-BACK
실행이 끝나면 해당 결과를
레지스터에 저장하는 단계이다
오른쪽 아래의 도식을 자세히 살펴보자
처음에 PC가 Instruction의 주소를 주면
해당 instruction을 I-cache에서 읽어온다
그럼 그걸 decoding을 하고 register를 읽어온다
그다음에 ALU를 통해 execute를 한 뒤
결과를 memory에 저장할수도 레지스터에 저장할 수도 있는데
어쨌든 저장을 한 뒤 Write-Back을 해준다
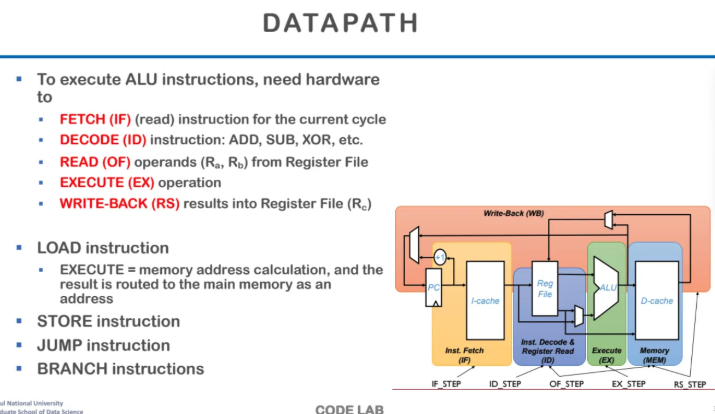
각 instruction들마다 어떻게 실행되는지를 간단히 살펴보자
load같은 경우는 execute 단계에서
메모리 주소를 계산하고
해당 메모리 주소의 결과가 memory address로 간다
jump나 store도 마찬가지이다
execute 단계에서 주소값 연산을 한다
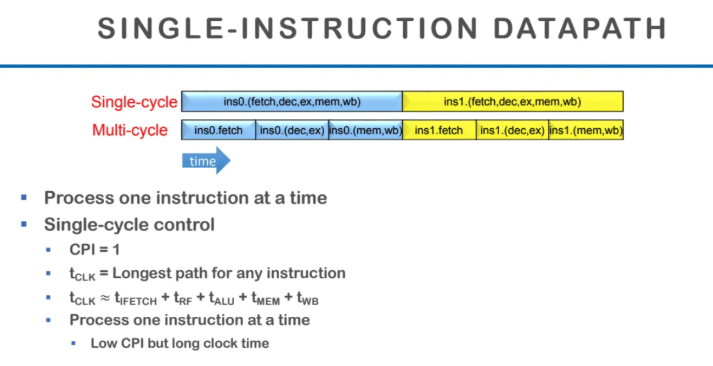
single cycle control에 대해서 살펴보자
single cycle control은 한 개의 instruction을
한 개의 clock cycle에 실행하는 방식이다
이 경우 CPI는 1이 된다
t clk는 clock time의 길이인데
보통 t clk은 어떤 Instruction이든
실행시간이 가장 오래걸리는 것을 기준으로 맞추기때문에
t clk은 실행시간이 가장 오래걸리는 instruction 기준으로
5가지의 모든 단계를 더한 값과 비슷하다
따라서 한개의 instruction을 기준으로 t clk을 설정하면
CPI 자체는 매우 낮아질 수 있다
왜냐하면 t clk자체가 길어지기 때문이다

그래서 t clk을 짧게 가져가서
multi cycle control의 방식을 적용하면
CPI가 늘어나게 된다
그래서 어떻게 하면 CPI도 낮추고
t clk도 짧게 가져갈 수 있을까?
이게 바로 pipelining 최적화의 목표이다
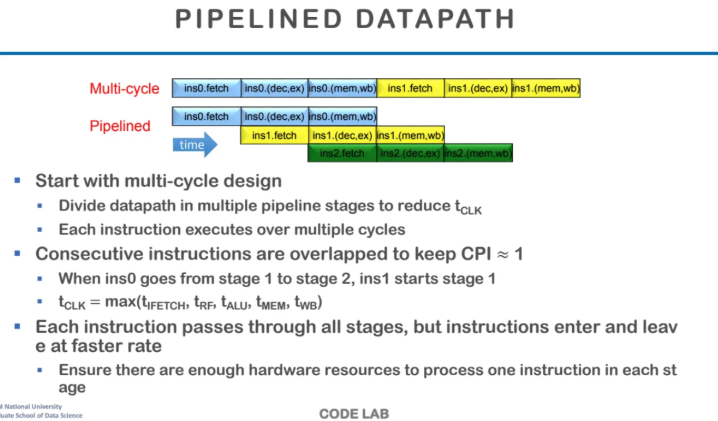
multi-cycle design이란 하나의 instruction을
한 번에 처리하는 것이 아니라
여러 번의 clock cycle에 나누어서 처리하는 방식이다
그래서 각 stage 중에서 가장 시간이 오래 걸리는 걸
기준으로 clock time을 설정한다
이러한 multi-cycle으로는 연속적인 instruction을
최대한 겹치게 수행하도록하면
CPI를 1에 가깝게 가져갈 수 있다
이게 바로 CPU의 pipelining이다
이 방식이 single cycle design보다
CPI가 더 높지만
clock time이 더 짧기 때문에 높은 성능을 보일 수 있다
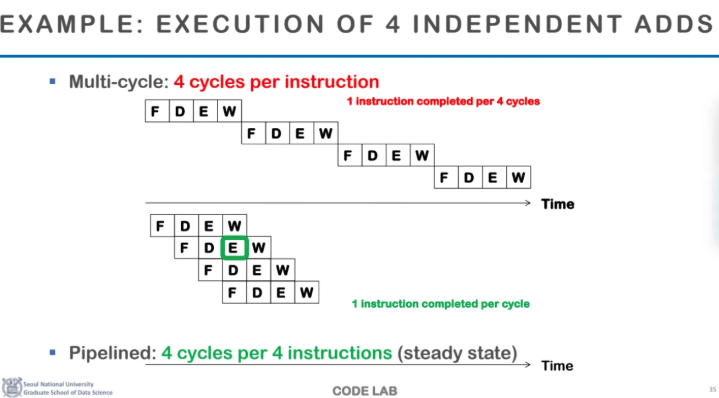
위 ppt에서 일반적인 mulit cycle 구조에서는
한 개의 instruction을 4개의 cycle로 나누었다
이렇게 되면 CPI는 4가 되는데
아래에 CPU pipelining으로 각 cycle을 중첩수행되도록 만들어
결론적으로 평균 CPI를 1에 가깝게 만들어준다
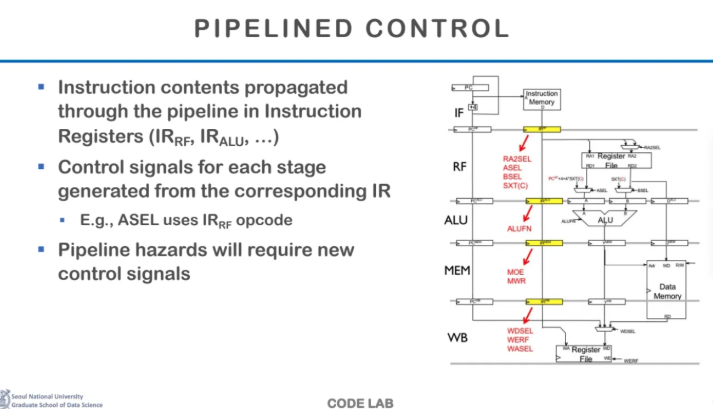
이게 가장 이상적이고 가장 일반적인
CPU pipeline의 구조이다
instruction이 각 stage를 지나가고
pipeline 사이에는 pipeline register가 존재한다
이 pipeline register에 대한 설명은 나중에 나온다
각각의 pipeline stage마다 clock이 바뀌었을 때
어떤 action을 취할지를 결정해주고
그 cycle동안 해당 pipeline을 실행시켜주고
그걸 또 다음 stage에 넘겨주고
이런걸 계속 반복한다
이게 아주 이상적으로 pipeline을 꽉꽉 채워서
수행한다면 이렇게 되는 것이다
하지만 늘 현실이라는(...) 장벽은
이상적으로 두게 내버려두질 않는데
뒤에가면 나오는 hazard라는 개념이
이렇게 이쁘게 수행되지 않도록 방해한다
아무리 이렇게 이상적일 때 잘되도록 설계해도
결국 hazard를 어떻게 처리하냐가
매우 중요한 문제가 되는 것이다
(99개 잘해도 1번 잘못하면 조지는 인생이랑 똑같음)
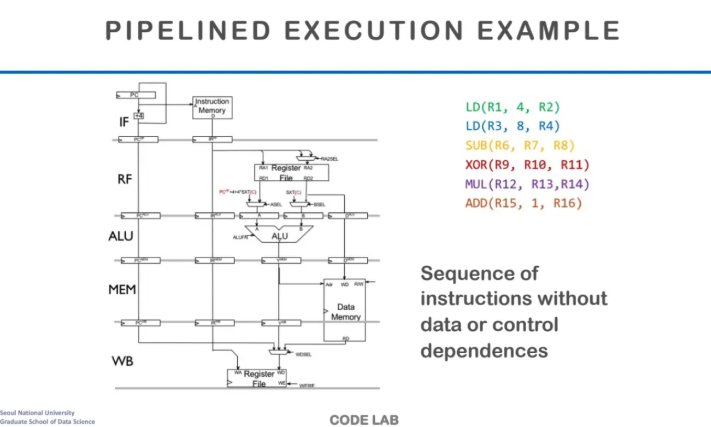
앞에서 배운 instruction을 예시로
pipeline excution example을 수행해보자
load를 2번 해주고 그 뒤로
sub, xor, mul, add를 수행해주자
위 example instruction이 굉장히 이상적인 이유는
data dependency가 없기 때문이다
data dependency란 앞에서 로드한 데이터를
뒤에서 읽는다던가, 앞에서 어떤 작업이 완료되어야만
뒤의 instruction에서 수행가능한
그런 것들을 말하는 것이고 이게 대표적인 hazard의 원인이다
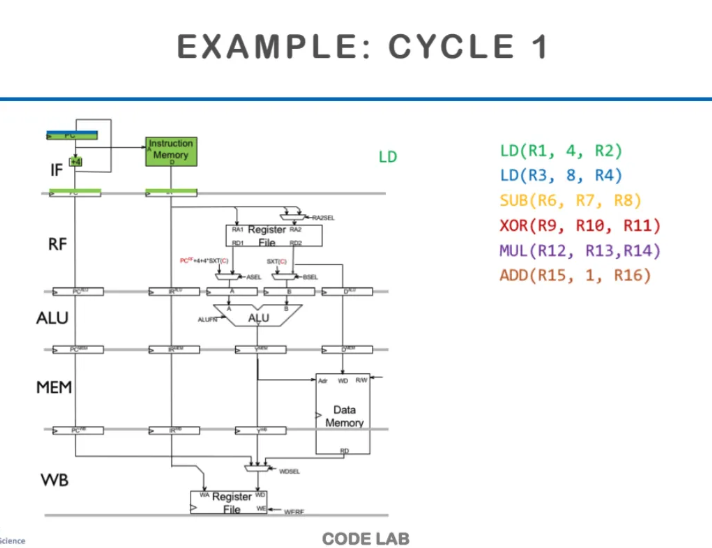
맨 처음에 IF에서 초록색 LD instruction을 fetch해온다
icache에서 가져오든 메모리에서 가져오든
어떻게든 instruction을 가져온다
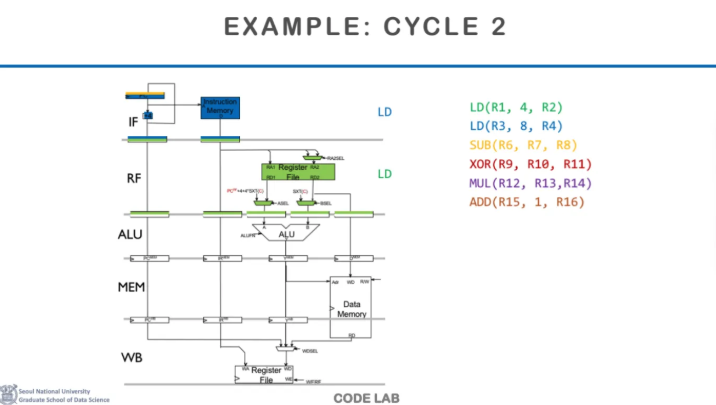
첫번째 LD는 두번째 단계인 RF로 가서
register file을 읽는다
이때 두번째 instruction인 LD가
첫 번째 단계인 IF로 들어온다
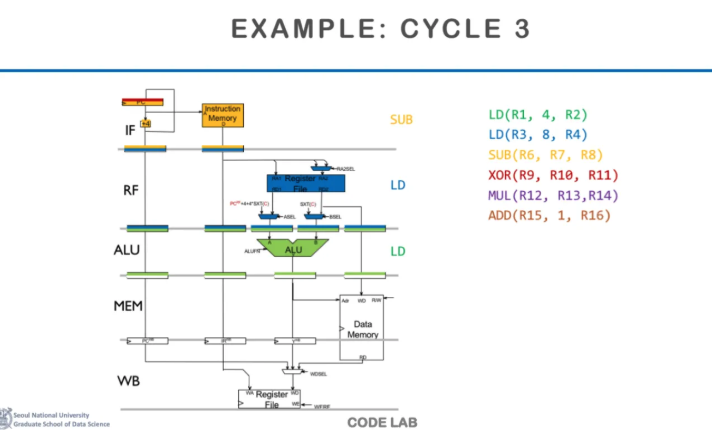
그다음 cycle 3에서는
첫 번째 instruction은 ALU에 가서
address연산을 수행하고
그 뒤의 instruction들도 각 단계로 들어온다
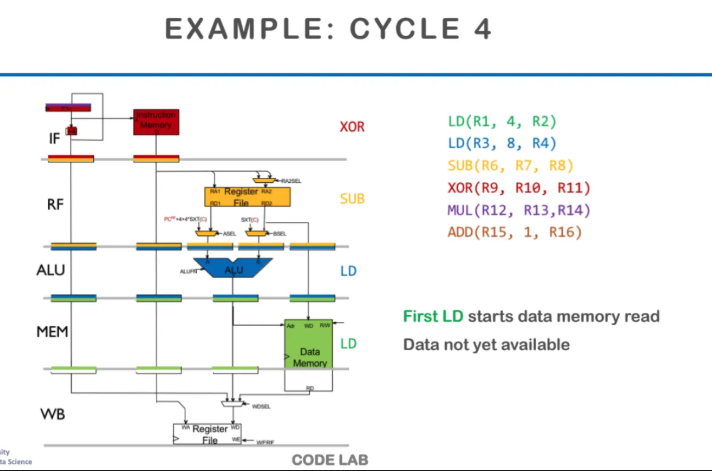
이제 cycle 4에 들어오면
첫 번째 Instruction은 MEM 단계에 들어가서
메모리를 읽어온다
이 때 cache memory에 접근하는데
이때 만약 어떠한 이유로 cache miss가 발생하면
메인메모리로 가서 데이터를 읽어와야한다
만약 이런 상황이 발생한다면
거의 몇 백 cycle이 걸리는데
이러한 상황도 우리가 뒤에 가서 다뤄야할
hazard의 경우 중 하나이다
이런 경우 몇 백 cycle을 기다릴지 아니면
다른 어떤 방식으로 수행할지가
hazard를 해결하는 option들이 되는 것이다
더욱 자세한건 hazard를 배우면서 나온다고한다
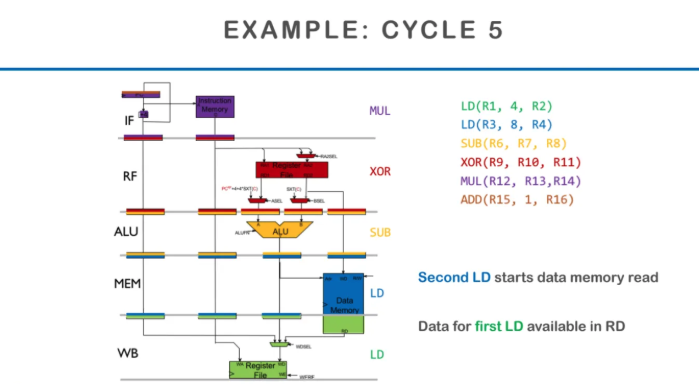
cycle 5에서는 마지막으로 첫 번째 instruction이
WB단계로가서 MEM에서 읽어온 결과를 쓰게 된다
그러고 그 뒤의 instruction들도 차곡차곡 따라오게된다
이게 바로 굉장히 이상적인 경우의 data pipeling이고
그 이유는 코드 간의 data dependency가
단 하나도 없기 때문이다

이제부터 pipeline에서 발생할 수 있는 예외 사항인
hazard에 대해서 배워보도록하자

위에서 우리는 instruction들이 어떻게
pipeline에서 수행이 되는지 확인했다
하지만 매번 말했지만 위의 예시는
굉장히 이상적인 코드이기 때문에
아름답게(?) pipeline에 꽉꽉 맞춰서 수행이 가능했다
하지만 보통 현실에서는 그렇지가 못하다
늘 현실에서는 어떠한 예외가 존재하는데
pipeline의 경우 예외는 대부분
data dependency나 control dependency이다
만약 data에서 dependency가 발생하면
이는 data hazard가 되는 것이고
branch, jump, exception 등에 의해서
control dependency가 발생하면
이는 control hazard 상황이 되는 것이다
따라서 이런 hazard가 발생하면
그걸 handling하는 로직을 추가해야한다

우선 data dependency에 대해서 알아보자
data dependence에는 3가지 종류가 있다
첫 번째는 Read-After-Write이라고 하는 RAW인데
앞에서 해당 메모리에 write가 끝나야지
그 뒤에서 읽을 수 있다는 것이다
이건 우리가 없앨 수가 없는 dependency라고 해서
true dependency라고 부른다
그다음 Anti-Dependence가 있는데
메모리를 다 읽기 전까지 쓸 수 없다는 것인데
이건 사실상 실제로 다른 곳에 저장하면 되기 때문에
정확하게 말하면 없앨 수 있는 dependence이다
마지막 output dependence도
다 쓰기를 기다린 다음 같은 메모리에 써야한다는 뜻인데
이도 결국 register를 재사용하기 때문에 생기는 dependence라
사실상 없앨 수 있는 dependence이다
따라서 사실상 없앨 수 있는 dependence인
WAR과 WAW는 false dependence라고 부른다
control dependency란
branch를 가기 전에 condition을 먼저 계산해야해서
branch target을 수행할 수 없는 경우,
branch에 가기 전에 branch instruction이 먼저
수행될 수 없는 경우를 말한다
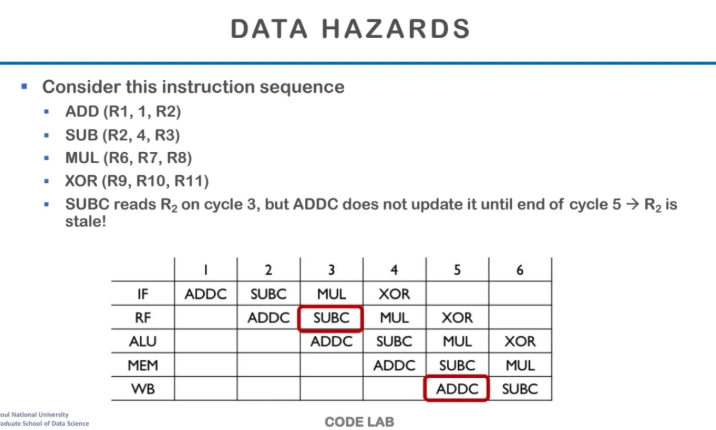
data hazard의 상황을 한 번 살펴보자
위와 같은 Instruction sequence가 있다고 가정한다
ADD와 SUB에서 R2가 dependence한 것을 확인할 수 있다
이건 R2에서 ADD값을 써줘야 SUB에서 R2를 read 할 수 있으므로
피할 수 없는 true dependency이다
매 instruction마다 src와 dest의 위치가 바뀌는데
이 예시에서는 src, src, dest이다
위 table을 한 번 잘 살펴보자
ADDC를 수행해줬다
원래 이상적으로라면 ADDC를 수행한 이후
3번째 clock에 SUBC가 RF 되어야하는데
R2가 아직 write이 되지 않아 접근할 수가 없다
그럼 R2가 write이 되는 시점은 언제냐?
바로 ADD가 마지막 WB를 끝마쳤을 때이다
이게 대표적인 data hazard의 예시이다

이러한 hazard 상황을 해결하는 방법은
크게 3가지가 있다
첫 번째는 Stall
두번째는 Bypass
세번째는 Speculate이다
이번 수업시간에서는 Stall까지만 알아보고
Bypass와 Speculate는 다음 시간부터 알아본다고한다
일단 간단하게만 살펴보자면
stall은 가장 간단한 resolve 방식으로
그냥 이전의 수행이 완료될 때까지 기다리는 것이다
아무것도 안하고 기다리면서 해당 pipeline stage를
NOP과 같은 의미없는 Instruction으로 채운다
Bypass는 Forward라고도 불리는 방법인데
만약 위의 예시같은 경우
실제 ADD연산이 수행되는 것은 execution인 ALU 단계이다
그래서 메모리에 아직 쓰지는 않았지만
ALU 단계에서 R1, R2의 값을 이미 알고있는 것이다
그래서 ALU에서 와이어로 로직을 연결해서
계산이 완료되면 그 이전의 stage로 보내주는 것이다
그럼 SUB는 ADD가 WB이 끝날 때까지 기다리지않아도
앞에서 계산 값을 미리 받아서 사용할 수 있게 된다
마지막으로는 speculate인데
이는 어떤 값일지 예측을 하는 것이다
예측한 값을 가지고 R2의 값은 00일 것이다라고해서
실행을 하는 것이다
만약 예측을 했는데 실제 값이 예측 값과 동일하다면
개이득이 되어서 그냥 넘어가는 것이고
만약 틀리게된다면 지금까지 다 실행한 것을 flush 해버리는
처참한 결말을 맞이해야한다
이러한 speculate는 주로 ALU 연산과 같은 것보다는
control dependency에 자주 사용되는데
왜냐하면 보통 condition같은 경우는 true, false 밖에 없기 때문에
예측 범위가 줄어 예측이 상당히 용이하다
또한, ADD, SUB같은 기본 ALU 연산을 value prediction이라고 부르는데
실제로 하드웨어에서 수행하긴 하지만
굉장히 쉽지 않은 작업이다

마지막으로 Stall을 자세히 살펴보고
오늘 수업 내용 정리는 마무리해보려고 한다
stall은 가장 단순한 해결방식이다
결과가 없어서 읽을 수가 없으니깐
ㄷㅏ음 단계로 넘어갈수가 없어서
NOP이라는 의미없는 버블 instruction을 넣는다
위 table을 한 번 잘 살펴보자
cycle 3에서 SUB가 R2를 RF 해와야하는데
이전의 ADDC에서 아직 R2에 값을 쓰질 않아서
더이상 수행을 진행할 수가 없다
그래서 4번째 cycle부터 더이상 진행하지 않고
NOP instruction이 수행되어 SUBC에서
더이상 진행하지 않고 멈춘 것을 볼 수 있다
그러고 ADDC가 WB가 끝나는
6번째 cycle까지 기다리다가
7번째 cycle부터 SUBC가 다시 진행되는 것을 볼 수 있다
stall이 생기게되면 너무 당연하겠지만
CPI가 증가한다
왜냐하면 한개의 instruction을 수행하는데
cycle이 당연히 더 소모가 많이 되기 때문이다
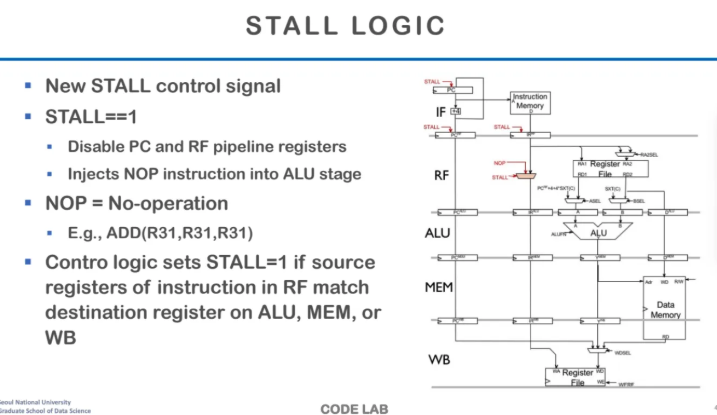
stall의 로직이다
stall control을 보내는 register가 있는데
여기서 stall 여부를 signal로 보내준다
stall signal을 보내주면 PC를 disable 시키면서
더이상 instruction을 fetching해오지못하게한다
그런 다음 해당 stage에는 아무 의미가 없는
NOP을 넣는다
실제로 아무 것도 안하는 것은 아니라고 한다
근데 그냥 의미가 없는 instruction을 넣는 것이라고 한다
ppt 예시에서는 ADD(R31, R31, R31)과 같은
수행은 되지만 아무런 의미가 없는
그런 instruction을 넣어주는 것이라고 한다
아무튼 stall signal이 1이 되는 경우는
source register의 RF가
dest register에서 ALU, MEM, WB와 매칭될 때이고
이 stall이 진행되는 것이라고 한다
오늘 수업 내용은 여기까지..
내용도 너무 많고
속도도 너무 빨라서 벅찼지만..
그래도 나름 재밌는 것 같다
끝-!